5. Flink-容错机制
5.1 Checkpoint
5.1.1 State Vs Checkpoint
State:
维护/存储的是某一个Operator的运行的状态/历史值,是维护在内存中!
一般指一个具体的Operator的状态(operator的状态表示一些算子在运行的过程中会产生的一些历史结果,如前面的maxBy底层会维护当前的最大值,也就是会维护一个keyedOperator,这个State里面存放就是maxBy这个Operator中的最大值)
State数据默认保存在Java的堆内存中/TaskManage节点的内存中
State可以被记录,在失败的情况下数据还可以恢复
Checkpoint:
某一时刻,Flink中所有的Operator的当前State的全局快照,一般存在磁盘上
表示了一个Flink Job在一个特定时刻的一份全局状态快照,即包含了所有Operator的状态
可以理解为Checkpoint是把State数据定时持久化存储了
比如KafkaConsumer算子中维护的Offset状态,当任务重新恢复的时候可以从Checkpoint中获取
注意:
Flink中的Checkpoint底层使用了Chandy-Lamport algorithm分布式快照算法可以保证数据的在分布式环境下的一致性!
https://zhuanlan.zhihu.com/p/53482103
Chandy-Lamport algorithm算法的作者也是ZK中Paxos 一致性算法的作者
https://www.cnblogs.com/shenguanpu/p/4048660.html
Flink中使用Chandy-Lamport algorithm分布式快照算法取得了成功,后续Spark的StructuredStreaming也借鉴了该算法。
5.1.2 Checkpoint执行流程
5.1.2.1 简单流程

0.Flink的JobManager创建CheckpointCoordinator
1.Coordinator向所有的SourceOperator发送Barrier栅栏(理解为执行Checkpoint的信号)
2.SourceOperator接收到Barrier之后,暂停当前的操作(暂停的时间很短,因为后续的写快照是异步的),并制作State快照, 然后将自己的快照保存到指定的介质中(如HDFS), 一切 ok之后向Coordinator汇报并将Barrier发送给下游的其他Operator
3.其他的如TransformationOperator接收到Barrier,重复第2步,最后将Barrier发送给Sink
4.Sink接收到Barrier之后重复第2步
5.Coordinator接收到所有的Operator的执行ok的汇报结果,认为本次快照执行成功
注意:
1.在往介质(如HDFS)中写入快照数据的时候是异步的(为了提高效率)
2.分布式快照执行时的数据一致性由Chandy-Lamport algorithm分布式快照算法保证!
5.1.3 State状态后端/State存储介质
注意:
前面学习了Checkpoint其实就是Flink中某一时刻所有的Operator的全局快照;
那么快照应该要有一个地方进行存储,而这个存储的地方叫做状态后端;
Flink中的State状态后端有很多种:
5.1.3.1 MemStateBackend[了解]

第一种是内存存储,即 MemoryStateBackend,构造方法是设置最大的StateSize,选择是否做异步快照,
对于State状态存储在 TaskManager 节点也就是执行节点内存中的,因为内存有容量限制,所以单个 State maxStateSize 默认 5 M,且需要注意 maxStateSize <= akka.framesize 默认 10 M。
对于Checkpoint 存储在 JobManager 内存中,因此总大小不超过 JobManager 的内存。
推荐使用的场景为:本地测试、几乎无状态的作业,比如 ETL、JobManager 不容易挂,或挂掉影响不大的情况。
不推荐在生产场景使用。
5.1.3.2 FsStateBackend

另一种就是在文件系统上的 FsStateBackend 构建方法是需要传一个文件路径和是否异步快照。
State 依然在 TaskManager 内存中,但不会像 MemoryStateBackend 是 5 M 的设置上限
Checkpoint 存储在外部文件系统(本地或 HDFS),打破了总大小 Jobmanager 内存的限制。
推荐使用的场景为:常规使用状态的作业、例如分钟级窗口聚合或 join、需要开启HA的作业。
如果使用HDFS,则初始化FsStateBackend时,
需要传入以 “hdfs://”开头的路径(即: new FsStateBackend(“hdfs:///hacluster/checkpoint”)),
如果使用本地文件,则需要传入以“file://”开头的路径(即:new FsStateBackend(“file:///Data”))。
在分布式情况下,不推荐使用本地文件。因为如果某个算子在节点A上失败,在节点B上恢复,使用本地文件时,在B上无法读取节点 A上的数据,导致状态恢复失败。
5.1.3.3 RocksDBStateBackend

还有一种存储为 RocksDBStateBackend ,
RocksDB 是一个 key/value 的内存存储系统,和其他的 key/value 一样,先将状态放到内存中,如果内存快满时,则写入到磁盘中,
但需要注意 RocksDB 不支持同步的 Checkpoint,构造方法中没有同步快照这个选项。
不过 RocksDB 支持增量的 Checkpoint,意味着并不需要把所有 sst 文件上传到 Checkpoint 目录,仅需要上传新生成的 sst 文件即可。它的 Checkpoint 存储在外部文件系统(本地或HDFS),
其容量限制只要单个 TaskManager 上 State 总量不超过它的内存+磁盘,单 Key最大 2G,总大小不超过配置的文件系统容量即可。
推荐使用的场景为:超大状态的作业,例如天级窗口聚合、需要开启 HA 的作业、最好是对状态读写性能要求不高的作业。
5.1.3.4 Checkpoint配置方式
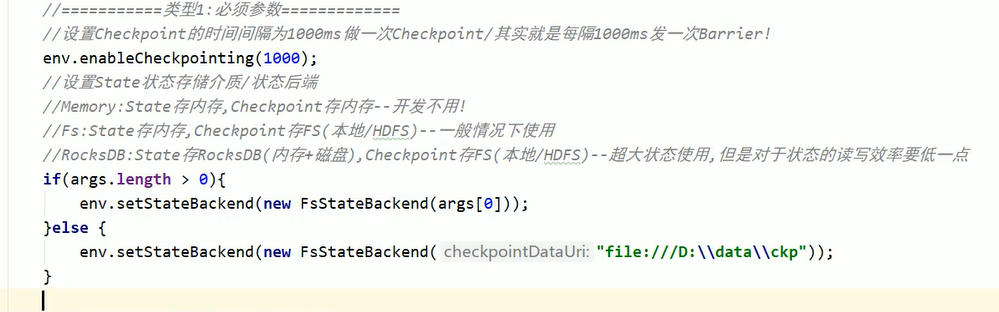
修改flink-conf.yaml#这里可以配置#jobmanager(即MemoryStateBackend),#filesystem(即FsStateBackend),#rocksdb(即RocksDBStateBackend)state.backend: filesystemstate.checkpoints.dir: hdfs://namenode:8020/flink/checkpoints
//1.MemoryStateBackend--开发中不用env.setStateBackend(new MemoryStateBackend)//2.FsStateBackend--开发中可以使用--适合一般状态--秒级/分钟级窗口...env.setStateBackend(new FsStateBackend("hdfs路径或测试时的本地路径"))//3.RocksDBStateBackend--开发中可以使用--适合超大状态--天级窗口...env.setStateBackend(new RocksDBStateBackend(filebackend, true))注意:RocksDBStateBackend还需要引入依赖<dependency><groupId>org.apache.flink</groupId><artifactId>flink-statebackend-rocksdb_2.11</artifactId><version>1.7.2</version></dependency>
5.2 状态恢复和重启策略
5.2.1 自动重启策略和恢复

5.2.1.1 重启策略配置方式
配置文件中
在flink-conf.yml中可以进行配置,示例如下:
restart-strategy: fixed-delay
restart-strategy.fixed-delay.attempts: 3
restart-strategy.fixed-delay.delay: 10 s
5.2.1.2 重启策略分类
5.2.1.2.1 默认重启策略
如果配置了Checkpoint,而没有配置重启策略,那么代码中出现了非致命错误时程序会无限重启
5.2.1.2.2 无重启策略
Job直接失败,不会尝试进行重启
设置方式1:
restart-strategy: none
设置方式2:
无重启策略也可以在程序中设置
val env = ExecutionEnvironment.getExecutionEnvironment()
env.setRestartStrategy(RestartStrategies.noRestart())
5.2.1.2.3 固定延迟重启策略—开发中使用
设置方式1:
重启策略可以配置flink-conf.yaml的下面配置参数来启用,作为默认的重启策略:
例子:
restart-strategy: fixed-delay
restart-strategy.fixed-delay.attempts: 3
restart-strategy.fixed-delay.delay: 10 s
设置方式2:
也可以在程序中设置:
val env = ExecutionEnvironment.getExecutionEnvironment()
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(
3, // 最多重启3次数
Time.of(10, TimeUnit.SECONDS) // 重启时间间隔
))
上面的设置表示:如果job失败,重启3次, 每次间隔10
5.2.1.2.4 失败率重启策略—开发偶尔使用
设置方式1:
失败率重启策略可以在flink-conf.yaml中设置下面的配置参数来启用:
例子:
restart-strategy:failure-rate
restart-strategy.failure-rate.max-failures-per-interval: 3
restart-strategy.failure-rate.failure-rate-interval: 5 min
restart-strategy.failure-rate.delay: 10 s
设置方式2:
失败率重启策略也可以在程序中设置:
val env = ExecutionEnvironment.getExecutionEnvironment()
env.setRestartStrategy(RestartStrategies.failureRateRestart(
3, // 每个测量时间间隔最大失败次数
Time.of(5, TimeUnit.MINUTES), //失败率测量的时间间隔
Time.of(10, TimeUnit.SECONDS) // 两次连续重启的时间间隔
))
上面的设置表示:如果5分钟内job失败不超过三次,自动重启, 每次间隔10s (如果5分钟内程序失败超过3次,则程序退出)
5.2.2 手动重启并恢复-了解
将程序取消后,然后继续执行,如果需要恢复之前的数据,那就可以指定之前的CheckPoint文件,进行恢复
重新启动任务并指定从哪恢复
cn.itcast.checkpoint.CheckpointDemo01
hdfs://node1:8020/flink-checkpoint/checkpoint/9e8ce00dcd557dc03a678732f1552c3a/chk-34,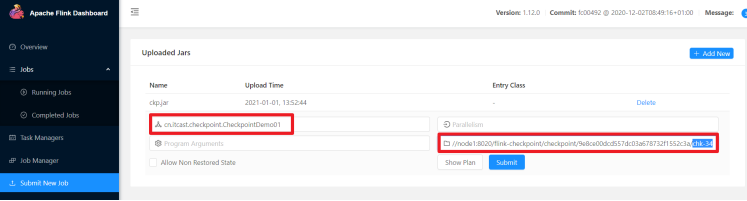
5.3 Savepoint
5.3.1 Savepoint介绍
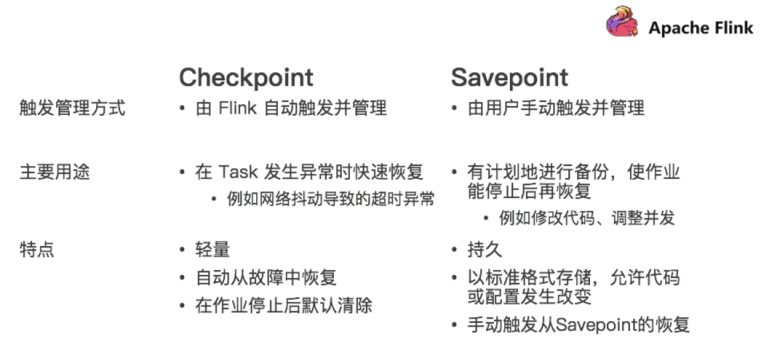
Savepoint:保存点,类似于以前玩游戏的时候,遇到难关了/遇到boss了,赶紧手动存个档,然后接着玩,如果失败了,赶紧从上次的存档中恢复,然后接着玩。
在实际开发中,可能会遇到这样的情况:如要对集群进行停机维护/扩容…
那么这时候需要执行一次Savepoint也就是执行一次手动的Checkpoint/也就是手动的发一个barrier栅栏,那么这样的话,程序的所有状态都会被执行快照并保存,当维护/扩容完毕之后,可以从上一次Savepoint的目录中进行恢复。
5.3.2 Savepoint VS Checkpoint

5.3.3 Savepoint演示
# 启动yarn session/export/server/flink/bin/yarn-session.sh -n 2 -tm 800 -s 1 -d# 运行job-会自动执行Checkpoint/export/server/flink/bin/flink run --class cn.itcast.checkpoint.CheckpointDemo01 /root/ckp.jar# 手动创建savepoint--相当于手动做了一次Checkpoint/export/server/flink/bin/flink savepoint 702b872ef80f08854c946a544f2ee1a5 hdfs://node1:8020/flink-checkpoint/savepoint/# 停止job/export/server/flink/bin/flink cancel 702b872ef80f08854c946a544f2ee1a5# 重新启动job,手动加载savepoint数据/export/server/flink/bin/flink run -s hdfs://node1:8020/flink-checkpoint/savepoint/savepoint-702b87-0a11b997fa70 --class cn.itcast.checkpoint.CheckpointDemo01 /root/ckp.jar# 停止yarn sessionyarn application -kill application_1607782486484_0014
6. 扩展:关于并行度
一个Flink程序由多个Operator组成(source、transformation和 sink)。
一个Operator由多个并行的Task(线程)来执行, 一个Operator的并行Task(线程)数目就被称为该Operator(任务)的并行度(Parallel)
并行度可以有如下几种指定方式:
1.Operator Level(算子级别)(可以使用)
一个算子、数据源和sink的并行度可以通过调用 setParallelism()方法来指定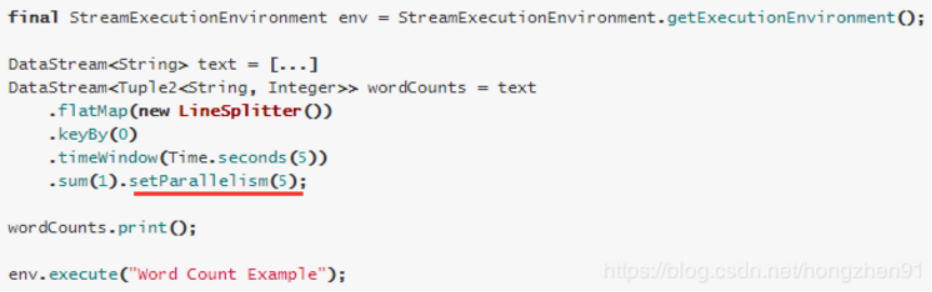
2.Execution Environment Level(Env级别)(可以使用)
执行环境(任务)的默认并行度可以通过调用setParallelism()方法指定。为了以并行度3来执行所有的算子、数据源和data sink, 可以通过如下的方式设置执行环境的并行度:
执行环境的并行度可以通过显式设置算子的并行度而被重写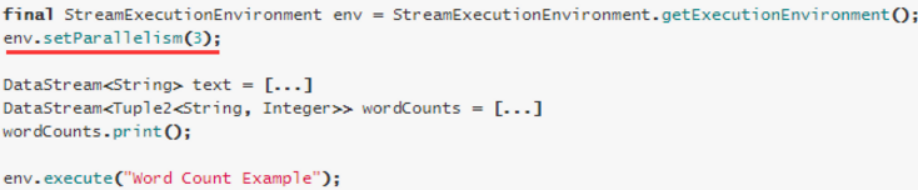
3.Client Level(客户端级别,推荐使用)(可以使用)
并行度可以在客户端将job提交到Flink时设定。
对于CLI客户端,可以通过-p参数指定并行度
./bin/flink run -p 10 WordCount-java.jar
4.System Level(系统默认级别,尽量不使用)
在系统级可以通过设置flink-conf.yaml文件中的parallelism.default属性来指定所有执行环境的默认并行度

Example1
在fink-conf.yaml中 taskmanager.numberOfTaskSlots 默认值为1,即每个Task Manager上只有一个Slot ,此处是3
Example1中,WordCount程序设置了并行度为1,意味着程序 Source、Reduce、Sink在一个Slot中,占用一个Slot

Example2
通过设置并行度为2后,将占用2个Slot
Example3
通过设置并行度为9,将占用9个Slot
Example4
通过设置并行度为9,并且设置sink的并行度为1,则Source、Reduce将占用9个Slot,但是Sink只占用1个Slot
注意:
1.并行度的优先级:算子级别> env级别 > Client级别 > 系统默认级别 (越靠前具体的代码并行度的优先级越高)
2.如果source不可以被并行执行,即使指定了并行度为多个,也不会生效
3.在实际生产中,我们推荐在算子级别显示指定各自的并行度,方便进行显示和精确的资源控制。
4.slot是静态的概念,是指taskmanager具有的并发执行能力; parallelism是动态的概念,是指程序运行时实际使用的并发能力

若有收获,就点个赞吧
0 人点赞
