流处理引擎通常为应用程序提供了三种数据处理语义:最多一次、至少一次和精确一次。
如下是对这些不同处理语义的宽松定义(一致性由弱到强):
At most noce < At least once < Exactly once < End to End Exactly once
3.1.1 At-most-once-最多一次
有可能会有数据丢失
这本质上是简单的恢复方式,也就是直接从失败处的下个数据开始恢复程序,之前的失败数据处理就不管了。可以保证数据或事件最多由应用程序中的所有算子处理一次。这意味着如果数据在被流应用程序完全处理之前发生丢失,则不会进行其他重试或者重新发送。
3.1.2 At-least-once-至少一次
有可能重复处理数据
应用程序中的所有算子都保证数据或事件至少被处理一次。这通常意味着如果事件在流应用程序完全处理之前丢失,则将从源头重放或重新传输事件。然而,由于事件是可以被重传的,因此一个事件有时会被处理多次(至少一次),至于有没有重复数据,不会关心,所以这种场景需要人工干预自己处理重复数据。
3.1.3 Exactly-once-精确一次,从失败的地方回放能够成功的处理一次
Exactly-Once 是 Flink、Spark 等流处理系统的核心特性之一,这种语义会保证每一条消息只被流处理系统处理一次。即使是在各种故障的情况下,流应用程序中的所有算子都保证事件只会被『精确一次』的处理。(也有文章将 Exactly-once 翻译为:完全一次,恰好一次)
Flink实现『精确一次』的分布式快照/状态检查点方法受到 Chandy-Lamport 分布式快照算法的启发。通过这种机制,流应用程序中每个算子的所有状态都会定期做 checkpoint。如果是在系统中的任何地方发生失败,每个算子的所有状态都回滚到最新的全局一致 checkpoint 点。在回滚期间,将暂停所有处理。源也会重置为与最近 checkpoint 相对应的正确偏移量。整个流应用程序基本上是回到最近一次的一致状态,然后程序可以从该状态重新启动。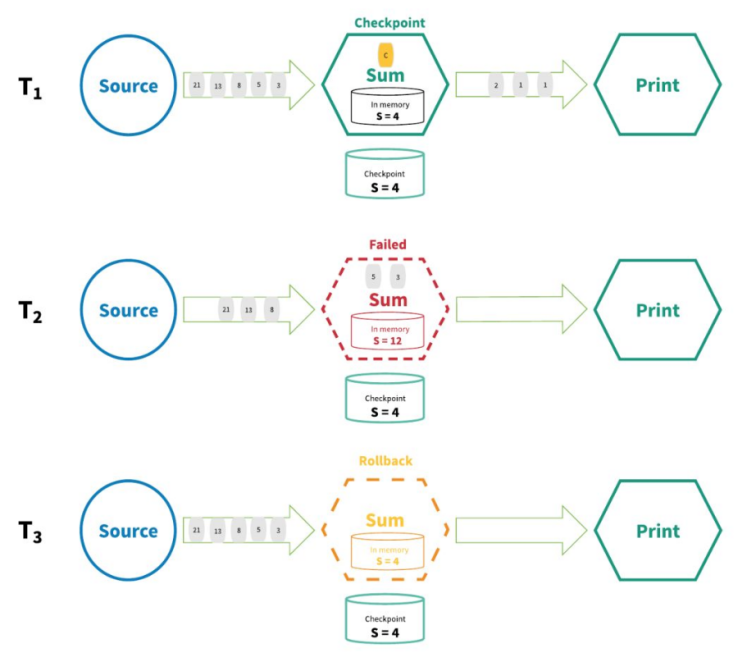
3.1.4 End-to-End Exactly-Once-端到端的精确一次
Flink 在1.4.0 版本引入『exactly-once』并号称支持『End-to-End Exactly-Once』“端到端的精确一次”语义。
它指的是 Flink 应用从 Source 端开始到 Sink 端结束,数据必须经过的起始点和结束点。
注意:
『exactly-once』和『End-to-End Exactly-Once』的区别:
Exactly Once:保证所有记录仅影响内部状态一次
End-To-End Exactly Once:保证所有记录仅影响内部和外部状态一次
内部状态表示Flink处理程序,外部表示外部数据源;比如kafka
3.1.5 Exactly Once 实现
实现Exactly Once有三种方式:
(1)At least once + 去重 (至少一次+去重)
每个算子维护一个事务日志,跟踪已处理的事件,在事件进入下个算子之前,移除重复事件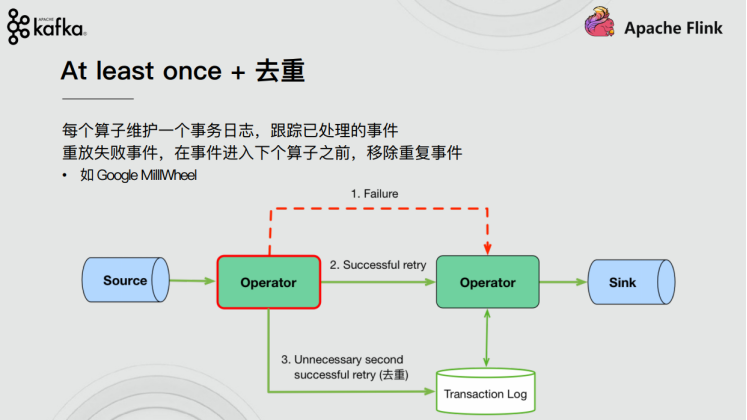
(2)At least once + 幂等 (至少一次+幂等)
依赖Sink端存储的去重性和数据特征,通过replace into+unique key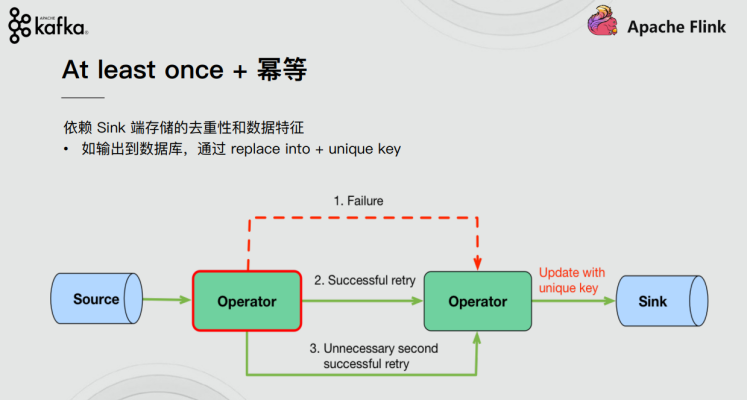
(3)分布式快照 checkpoint (Flink使用的是这个)
Chandy-Lamport分布式快照算法
引入barrier,把input stream分为preshot records 和 postshot records,Operator收到上游barrier的时候做一个snapshot,继续往下处理,当所有Sink Operator都完成了Snapshot,这一轮Snapshot就完成了。

3.2 End-to-End Exactly-Once的实现
通过前面的学习,我们了解到,Flink内部借助分布式快照Checkpoint已经实现了内部的Exactly-Once,但是Flink 自身是无法保证外部其他系统“精确一次”语义的,所以 Flink 若要实现所谓“端到端(End to End)的精确一次”的要求,那么外部系统必须支持“精确一次”语义;然后借助一些其他手段才能实现。如下:
3.2.1 Source
发生故障时需要支持重设数据的读取位置,如Kafka可以通过offset来实现(其他的没有offset系统,我们可以自己实现累加器计数)
3.2.2 Transformation
也就是Flink内部,已经通过Checkpoint保证了,如果发生故障或出错时,Flink应用重启后会从最新成功完成的checkpoint中恢复——重置应用状态并回滚状态到checkpoint中输入流的正确位置,之后再开始执行数据处理,就好像该故障或崩溃从未发生过一般。
- 分布式快照机制:
我们在之前的课程中讲解过Flink 的容错机制,Flink 提供了失败恢复的容错机制,而这个容错机制的核心就是持续创建分布式数据流的快照来实现。
同Spark 相比,Spark 仅仅是针对 Driver 的故障恢复 Checkpoint。而 Flink 的快照可以到算子级别,并且对全局数据也可以做快照。Flink 的分布式快照受到 Chandy-Lamport 分布式快照算法启发,同时进行了量身定做。
- Barrier
Flink 分布式快照的核心元素之一是 Barrier(数据栅栏),我们也可以把 Barrier 简单地理解成一个标记,该标记是严格有序的,并且随着数据流往下流动。每个 Barrier 都带有自己的 ID,Barrier 极其轻量,并不会干扰正常的数据处理。
Barrier 会随着正常数据继续往下流动,每当遇到一个算子,算子会插入一个标识,这个标识的插入时间是上游所有的输入流都接收到 snapshot n。与此同时,当我们的 sink 算子接收到所有上游流发送的 Barrier 时,那么就表明这一批数据处理完毕,Flink 会向“协调者”发送确认消息,表明当前的 snapshot n 完成了。当所有的 sink 算子都确认这批数据成功处理后,那么本次的 snapshot 被标识为完成。
这里就会有一个问题,因为Flink 运行在分布式环境中,一个 operator 的上游会有很多流,每个流的 barrier n 到达的时间不一致怎么办?这里 Flink 采取的措施是:快流等慢流。
解决方式:其中一个流到的早,其他的流到的比较晚。当第一个barrier n到来后,当前的 operator 会继续等待其他流的 barrier n。直到所有的barrier n 到来后,operator 才会把所有的数据向下发送。
- 异步和增量
按照上面我们介绍的机制,每次在把快照存储到我们的状态后端时,如果是同步进行就会阻塞正常任务,从而引入延迟。因此Flink 在做快照存储时,可采用异步方式。
此外,由于checkpoint 是一个全局状态,用户保存的状态可能非常大,多数达 G 或者 T 级别。在这种情况下,checkpoint 的创建会非常慢,而且执行时占用的资源也比较多,因此 Flink 提出了增量快照的概念。也就是说,每次都是进行的全量 checkpoint,是基于上次进行更新的。
3.2.3 Sink
需要支持幂等写入或事务写入(Flink的两阶段提交需要事务支持)
3.3 Flink+Kafka的End-to-End Exactly-Once
在上一小节我们了解到Flink的 End-to-End Exactly-Once需要Checkpoint+事务的提交/回滚操作,在分布式系统中协调提交和回滚的一个常见方法就是使用两阶段提交协议。接下来我们了解下Flink的TwoPhaseCommitSinkFunction是如何支持End-to-End Exactly-Once的。
Flink 1.4版本之后,通过两阶段提交(TwoPhaseCommitSinkFunction)支持End-To-End Exactly Once,而且要求Kafka 0.11+。
利用TwoPhaseCommitSinkFunction是通用的管理方案,只要实现对应的接口,而且Sink的存储支持变乱提交,即可实现端到端的划一性语义。
3.3.2 两阶段提交-API
在 Flink 中的Two-Phase-Commit-2PC两阶段提交的实现方法被封装到了 TwoPhaseCommitSinkFunction 这个抽象类中,只需要实现其中的beginTransaction、preCommit、commit、abort 四个方法就可以实现“精确一次”的处理语义,如FlinkKafkaProducer就实现了该类并实现了这些方法。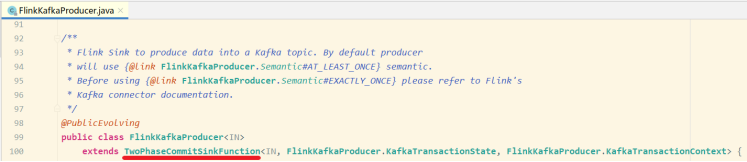
1.beginTransaction,在开启事务之前,我们在目标文件系统的临时目录中创建一个临时文件,后面在处理数据时将数据写入此文件;
2.preCommit,在预提交阶段,刷写(flush)文件,然后关闭文件,之后就不能写入到文件了,我们还将为属于下一个检查点的任何后续写入启动新事务;
3.commit,在提交阶段,我们将预提交的文件原子性移动到真正的目标目录中,请注意,这会增加输出数据可见性的延迟;
4.abort,在中止阶段,我们删除临时文件。
3.3.3 两阶段提交-简单流程

整个过程可以总结为下面四个阶段:
1.一旦 Flink 开始做 checkpoint 操作,那么就会进入 pre-commit “预提交”阶段,同时JobManager的Coordinator 会将 Barrier 注入数据流中
2.当所有的 barrier 在算子中成功进行一遍传递(就是Checkpoint完成),并完成快照后,则“预提交”阶段完成;
3.等所有的算子完成“预提交”,就会发起一个commit“提交”动作,但是任何一个“预提交”失败都会导致 Flink 回滚到最近的 checkpoint;
我们对上述知识点总结下:
1.一旦所有operator完成预提交,就提交一个commit。
2.如果只要有一个预提交失败,则所有其他提交都将中止,我们将回滚到上一个成功完成的checkpoint。
3.在预提交成功之后,提交的commit需要保证最终成功 – operator和外部系统都需要保障这点。如果commit失败(例如,由于间歇性网络问题),整个Flink应用程序将失败,应用程序将根据用户的重启策略重新启动,还会尝试再提交。这个过程至关重要,因为如果commit最终没有成功,将会导致数据丢失。
4.完整的实现两阶段提交协议可能有点复杂,这就是为什么Flink将它的通用逻辑提取到抽象类TwoPhaseCommitSinkFunction中的原因。
3.4 代码示例
3.4.1 Flink+Kafka实现End-to-End Exactly-Once (见idea)
3.4.2 Flink+MySQL实现End-to-End Exactly-Once(见idea)
需求
1.checkpoint每10s进行一次,此时用FlinkKafkaConsumer实时消费kafka中的消息
2.消费并处理完消息后,进行一次预提交数据库的操作
3.如果预提交没有问题,10s后进行真正的插入数据库操作,如果插入成功,进行一次checkpoint,flink会自动记录消费的offset,可以将checkpoint保存的数据放到hdfs中
4.如果预提交出错,比如在5s的时候出错了,此时Flink程序就会进入不断的重启中,重启的策略可以在配置中设置,checkpoint记录的还是上一次成功消费的offset,因为本次消费的数据在checkpoint期间,消费成功,但是预提交过程中失败了
5.注意此时数据并没有真正的执行插入操作,因为预提交(preCommit)失败,提交(commit)过程也不会发生。等将异常数据处理完成之后,再重新启动这个Flink程序,它会自动从上一次成功的checkpoint中继续消费数据,以此来达到Kafka到Mysql的Exactly-Once。
package cn.itcast.extend;import org.apache.flink.api.common.ExecutionConfig;import org.apache.flink.api.common.typeutils.base.VoidSerializer;import org.apache.flink.api.java.typeutils.runtime.kryo.KryoSerializer;import org.apache.flink.runtime.state.filesystem.FsStateBackend;import org.apache.flink.shaded.jackson2.com.fasterxml.jackson.databind.node.ObjectNode;import org.apache.flink.streaming.api.CheckpointingMode;import org.apache.flink.streaming.api.datastream.DataStreamSource;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import org.apache.flink.streaming.api.functions.sink.TwoPhaseCommitSinkFunction;import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;import org.apache.flink.streaming.util.serialization.JSONKeyValueDeserializationSchema;import org.apache.kafka.clients.CommonClientConfigs;import java.sql.*;import java.text.SimpleDateFormat;import java.util.Date;import java.util.Properties;public class Kafka_Flink_MySQL_EndToEnd_ExactlyOnce {public static void main(String[] args) throws Exception {//1.envStreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);//方便测试env.enableCheckpointing(10000);env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);env.getCheckpointConfig().setMinPauseBetweenCheckpoints(1000);//env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);env.setStateBackend(new FsStateBackend("file:///D:/ckp"));//2.SourceString topic = "flink_kafka";Properties props = new Properties();props.setProperty(CommonClientConfigs.BOOTSTRAP_SERVERS_CONFIG,"node1:9092");props.setProperty("group.id","flink");props.setProperty("auto.offset.reset","latest");//如果有记录偏移量从记录的位置开始消费,如果没有从最新的数据开始消费props.setProperty("flink.partition-discovery.interval-millis","5000");//开一个后台线程每隔5s检查Kafka的分区状态FlinkKafkaConsumer<ObjectNode> kafkaSource = new FlinkKafkaConsumer<>("topic_in", new JSONKeyValueDeserializationSchema(true), props);kafkaSource.setStartFromGroupOffsets();//从group offset记录的位置位置开始消费,如果kafka broker 端没有该group信息,会根据"auto.offset.reset"的设置来决定从哪开始消费kafkaSource.setCommitOffsetsOnCheckpoints(true);//Flink执行Checkpoint的时候提交偏移量(一份在Checkpoint中,一份在Kafka的默认主题中__comsumer_offsets(方便外部监控工具去看))DataStreamSource<ObjectNode> kafkaDS = env.addSource(kafkaSource);//3.transformation//4.SinkkafkaDS.addSink(new MySqlTwoPhaseCommitSink()).name("MySqlTwoPhaseCommitSink");//5.executeenv.execute();}}/**自定义kafka to mysql,继承TwoPhaseCommitSinkFunction,实现两阶段提交。功能:保证kafak to mysql 的Exactly-OnceCREATE TABLE `t_test` (`id` bigint(20) NOT NULL AUTO_INCREMENT,`value` varchar(255) DEFAULT NULL,`insert_time` datetime DEFAULT NULL,PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4*/class MySqlTwoPhaseCommitSink extends TwoPhaseCommitSinkFunction<ObjectNode, Connection, Void> {public MySqlTwoPhaseCommitSink() {super(new KryoSerializer<>(Connection.class, new ExecutionConfig()), VoidSerializer.INSTANCE);}/*** 执行数据入库操作*/@Overrideprotected void invoke(Connection connection, ObjectNode objectNode, Context context) throws Exception {System.err.println("start invoke.......");String date = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(new Date());System.err.println("===>date:" + date + " " + objectNode);String value = objectNode.get("value").toString();String sql = "insert into `t_test` (`value`,`insert_time`) values (?,?)";PreparedStatement ps = connection.prepareStatement(sql);ps.setString(1, value);ps.setTimestamp(2, new Timestamp(System.currentTimeMillis()));//执行insert语句ps.execute();//手动制造异常if(Integer.parseInt(value) == 15) System.out.println(1/0);}/*** 获取连接,开启手动提交事务(getConnection方法中)*/@Overrideprotected Connection beginTransaction() throws Exception {String url = "jdbc:mysql://localhost:3306/bigdata?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull&useSSL=false&autoReconnect=true";Connection connection = DBConnectUtil.getConnection(url, "root", "root");System.err.println("start beginTransaction......."+connection);return connection;}/*** 预提交,这里预提交的逻辑在invoke方法中*/@Overrideprotected void preCommit(Connection connection) throws Exception {System.err.println("start preCommit......."+connection);}/*** 如果invoke执行正常则提交事务*/@Overrideprotected void commit(Connection connection) {System.err.println("start commit......."+connection);DBConnectUtil.commit(connection);}@Overrideprotected void recoverAndCommit(Connection connection) {System.err.println("start recoverAndCommit......."+connection);}@Overrideprotected void recoverAndAbort(Connection connection) {System.err.println("start abort recoverAndAbort......."+connection);}/*** 如果invoke执行异常则回滚事务,下一次的checkpoint操作也不会执行*/@Overrideprotected void abort(Connection connection) {System.err.println("start abort rollback......."+connection);DBConnectUtil.rollback(connection);}}class DBConnectUtil {/*** 获取连接*/public static Connection getConnection(String url, String user, String password) throws SQLException {Connection conn = null;conn = DriverManager.getConnection(url, user, password);//设置手动提交conn.setAutoCommit(false);return conn;}/*** 提交事务*/public static void commit(Connection conn) {if (conn != null) {try {conn.commit();} catch (SQLException e) {e.printStackTrace();} finally {close(conn);}}}/*** 事务回滚*/public static void rollback(Connection conn) {if (conn != null) {try {conn.rollback();} catch (SQLException e) {e.printStackTrace();} finally {close(conn);}}}/*** 关闭连接*/public static void close(Connection conn) {if (conn != null) {try {conn.close();} catch (SQLException e) {e.printStackTrace();}}}}package cn.itcast.extend;import com.alibaba.fastjson.JSON;import lombok.AllArgsConstructor;import lombok.Data;import lombok.NoArgsConstructor;import org.apache.kafka.clients.producer.Producer;import org.apache.kafka.clients.producer.ProducerRecord;import java.util.Properties;public class DataProducer {public static void main(String[] args) throws InterruptedException {Properties props = new Properties();props.put("bootstrap.servers", "node1:9092");props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");Producer<String, String> producer = new org.apache.kafka.clients.producer.KafkaProducer<>(props);try {for (int i = 1; i <= 20; i++) {DataBean data = new DataBean(String.valueOf(i));ProducerRecord record = new ProducerRecord<String, String>("flink_kafka", null, null, JSON.toJSONString(data));producer.send(record);System.out.println("发送数据: " + JSON.toJSONString(data));Thread.sleep(1000);}}catch (Exception e){System.out.println(e);}producer.flush();}}@Data@NoArgsConstructor@AllArgsConstructorclass DataBean {private String value;}
4. Streaming File Sink
4.1 介绍
https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/connectors/streamfile_sink.html
https://blog.csdn.net/u013220482/article/details/100901471
4.1.1 场景描述
StreamingFileSink是Flink1.7中推出的新特性,是为了解决如下的问题:
大数据业务场景中,经常有一种场景:外部数据发送到kafka中,flink作为中间件消费kafka数据并进行业务处理;处理完成之后的数据可能还需要写入到数据库或者文件系统中,比如写入hdfs中。
StreamingFileSink就可以用来将分区文件写入到支持 Flink FileSystem 接口的文件系统中,支持Exactly-Once语义。
这种sink实现的Exactly-Once都是基于Flink checkpoint来实现的两阶段提交模式来保证的,主要应用在实时数仓、topic拆分、基于小时分析处理等场景下。
实现写入HDFS文件系统中的精确一次
package org.example.flink.feature;import org.apache.commons.lang3.SystemUtils;import org.apache.flink.api.common.RuntimeExecutionMode;import org.apache.flink.api.common.functions.FlatMapFunction;import org.apache.flink.api.common.functions.MapFunction;import org.apache.flink.api.common.serialization.SimpleStringEncoder;import org.apache.flink.api.java.tuple.Tuple2;import org.apache.flink.core.fs.Path;import org.apache.flink.runtime.state.filesystem.FsStateBackend;import org.apache.flink.streaming.api.CheckpointingMode;import org.apache.flink.streaming.api.datastream.DataStream;import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;import org.apache.flink.streaming.api.environment.CheckpointConfig;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import org.apache.flink.streaming.api.functions.sink.filesystem.OutputFileConfig;import org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink;import org.apache.flink.streaming.api.functions.sink.filesystem.rollingpolicies.DefaultRollingPolicy;import org.apache.flink.util.Collector;import java.util.concurrent.TimeUnit;/*** Author itcast* Desc 演示Flink StreamingFileSink将流式数据写入到HDFS 数据一致性由Checkpoint + 两阶段提交保证*/public class StreamingFileSinkDemo {public static void main(String[] args) throws Exception {//TODO 0.envStreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);//开启Checkpoint//===========类型1:必须参数=============//设置Checkpoint的时间间隔为1000ms做一次Checkpoint/其实就是每隔1000ms发一次Barrier!env.enableCheckpointing(1000);if (SystemUtils.IS_OS_WINDOWS) {env.setStateBackend(new FsStateBackend("file:///D:/ckp"));} else {env.setStateBackend(new FsStateBackend("hdfs://node1:8020/flink-checkpoint/checkpoint"));}//===========类型2:建议参数===========env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);//默认是0env.getCheckpointConfig().setTolerableCheckpointFailureNumber(10);//默认值为0,表示不容忍任何检查点失败env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);env.getCheckpointConfig().setCheckpointTimeout(60000);//默认10分钟env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);//默认为1//TODO 1.sourceDataStream<String> lines = env.socketTextStream("node1", 9999);//TODO 2.transformation//注意:下面的操作将上面的2步合成了1步,直接切割单词并记为1返回SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = lines.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {@Overridepublic void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {String[] arr = value.split(" ");for (String word : arr) {out.collect(Tuple2.of(word, 1));}}});SingleOutputStreamOperator<String> result = wordAndOne.keyBy(t -> t.f0).sum(1).map(new MapFunction<Tuple2<String, Integer>, String>() {@Overridepublic String map(Tuple2<String, Integer> value) throws Exception {return value.f0 + ":" + value.f1;}});//TODO 3.sinkresult.print();//使用StreamingFileSink将数据sink到HDFSOutputFileConfig config = OutputFileConfig.builder().withPartPrefix("prefix")//设置文件前缀.withPartSuffix(".txt")//设置文件后缀.build();StreamingFileSink<String> streamingFileSink = StreamingFileSink.forRowFormat(new Path("hdfs://node1:8020/FlinkStreamFileSink/parquet"), new SimpleStringEncoder<String>("UTF-8")).withRollingPolicy(DefaultRollingPolicy.builder().withRolloverInterval(TimeUnit.MINUTES.toMillis(15))//每隔15分钟生成一个新文件.withInactivityInterval(TimeUnit.MINUTES.toMillis(5))//每隔5分钟没有新数据到来,也把之前的生成一个新文件.withMaxPartSize(1024 * 1024 * 1024).build()).withOutputFileConfig(config).build();result.addSink(streamingFileSink);//TODO 4.executeenv.execute();}}

若有收获,就点个赞吧
0 人点赞
