Hadoop介绍:
狭义上:
Hadoop指的是Apache软件基金会的一款开源软件。
用java语言实现开源,允许用户使用简单的编程模型实现跨机器集群对海量数据进行分布式计算处理
Hadoop核心组件
Hadoop HDFS(分布式文件存储系统):解决海量数据存储
Hadoop YARN(集群资源管理和任务调度框架):解决资源任务调度
Hadoop MapReduce(分布式计算框架):解决海量数据计算
广义上:
Hadoop指的是围绕Hadoop打造的大数据生态圈:
Hadoop发展简史 :
Hadoop之父: Doug Cutting
Hadoop起源于Apache Lucene子项目: Nutch,Nutch的设计目标是构建一个大型的全网搜索引擎。遇到瓶颈:如何解决数十亿网页的存储和索引问题
Google三篇论文:
《The Google file system》 :谷歌分布式文件系统GFS
《MapReduce: Simplified Data Processing on Large Clusters》 :谷歌分布式计算框架MapReduce
《Bigtable: A Distributed Storage System for Structured Data》 :谷歌结构化数据存储系统
Hadoop现状 :
- HDFS作为分布式文件存储系统,处在生态圈的底层与核心地位;
- YARN作为分布式通用的集群资源管理系统和任务调度平台, 支撑各种计算引擎运行,保证了Hadoop地位;
- MapReduce作为大数据生态圈第一代分布式计算引擎,由于自身设计的模型所产生的弊端,导致企业一线几乎不再直接使用MapReduce进行编程处理,但是很多软件的底层依然在使用MapReduce引擎来处理数据
Hadoop特性优点:
Scalability:Hadoop是在可用的计算机集群间分配数据并完成计算任务的,这些集群以方便灵活的方式扩展到数以千计的节点。(扩容能力)
Economical:Hadoop集群允许通过部署普通廉价的机器组成集群来处理大数据,以至于成本很低。看重的是集群整体能力。(成本低)
Efficiency:通过并发数据,Hadoop可以在节点之间动态并行的移动数据,使得速度非常快。(效率高)
Reliability:能自动维护数据的多份复制,并且在任务失败后能自动地重新部署(redeploy)计算任务。(可靠性)
开源社区版:Apache开源社区发行也是官方发行版本优点:更新迭代快缺点:兼容稳定性不周
商业发行版:商业公司发行基于Apache开源协议某些服务需要收费优点:稳定兼容好缺点:收费 版本更新慢。
Apache开源社区版本http://hadoop.apache.org/
商业发行版本Cloudera:https://www.cloudera.com/products/open-source/apache-hadoop.html
Hortonworks :https://www.cloudera.com/products/hdp.html
本课程中使用的是Apache版的Hadoop,版本号为:3.3.0
Hadoop架构变迁:
Hadoop 1.0:
HDFS(分布式文件存储)
MapReduce(资源管理和分布式数据处理)
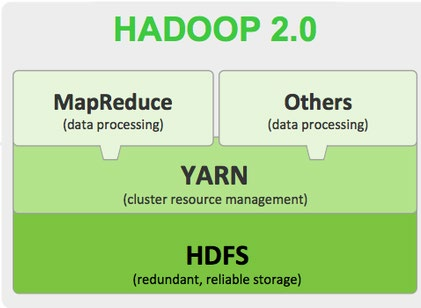
Hadoop 2.0:
HDFS(分布式文件存储)
MapReduce(分布式数据处理)
YARN(集群资源管理、任务调度)


Hadoop架构变迁(3.0新版本)
Hadoop 3.0架构组件和Hadoop 2.0类似,3.0着重于性能优化。
通用方面:
精简内核、类路径隔离、 shell脚本重构
Hadoop HDFS:
EC纠删码、 多NameNode支持
Hadoop MapReduce:
任务本地化优化、 内存参数自动推断
Hadoop YARN:
Timeline Service V2、队列配置

若有收获,就点个赞吧
0 人点赞
