import org.apache.flink.api.common.typeinfo.Types;import org.apache.flink.api.java.tuple.Tuple2;import org.apache.flink.streaming.api.datastream.DataStreamSource;import org.apache.flink.streaming.api.datastream.KeyedStream;import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import org.apache.flink.util.Collector;import java.util.Arrays;public class BoundedStreamWordCount {public static void main(String[] args) throws Exception {// 1. 创建流式执行环境StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();// 2. 读取文件DataStreamSource<String> lineDSS = env.readTextFile("input/words.txt");// 3. 转换数据格式SingleOutputStreamOperator<Tuple2<String, Long>> wordAndOne = lineDSS.flatMap((String line, Collector<String> words) -> {Arrays.stream(line.split(" ")).forEach(words::collect);}).returns(Types.STRING).map(word -> Tuple2.of(word, 1L)).returns(Types.TUPLE(Types.STRING, Types.LONG));// 4. 分组KeyedStream<Tuple2<String, Long>, String> wordAndOneKS = wordAndOne.keyBy(t -> t.f0);// 5. 求和SingleOutputStreamOperator<Tuple2<String, Long>> result = wordAndOneKS.sum(1);// 6. 打印result.print();// 7. 执行env.execute();}}// 输出结果:// 3> (world,1)// 2> (hello,1)// 4> (flink,1)// 2> (hello,2)// 2> (hello,3)// 1> (java,1)
这与批处理的结果是完全不同的。批处理针对每个单词,只会输出一个最终的统计个数;而在流处理的打印结果中, “hello”这个单词每出现一次,都会有一个频次统计数据输出。这就是流处理的特点,数据逐个处理,每来一条数据就会处理输出一次。我们通过打印结果,可以清晰地看到单词“hello”数量增长的过程。
我们读取文件,第一行应该是“hello flink”,怎么这里输出的第一个单词是“world”呢?每个输出的结果二元组,前面都有一个数字,这又是什么呢?
我们可以先做个简单的解释。 Flink 是一个分布式处理引擎,所以我们的程序应该也是分布式运行的。在开发环境里,会通过多线程来模拟 Flink 集群运行。所以这里结果前的数字,其实就指示了本地执行的不同线程,对应着 Flink 运行时不同的并行资源。这样第一个乱序的
问题也就解决了:既然是并行执行,不同线程的输出结果,自然也就无法保持输入的顺序了。
另外需要说明,这里显示的编号为 1~4,是由于运行电脑的 CPU 是 4 核,所以默认模拟的并行线程有 4 个。这段代码不同的运行环境,得到的结果会是不同的。关于 Flink 程序并行执行的数量,可以通过设定“并行度”(Parallelism)来进行配置。
// 修改数据源,尝试无界流,将上面代码改造下,从172.31.10.23主机读取// 2. 读取文本流 ,从主机名的8080端口下,172.31.10.23 node1 使用172.31.10.23主机DataStreamSource<String> lineDSS = env.socketTextStream("node1", 8080);
主机先启动8080端口,然后在启动程序使得程序能够监听到端口输入的数据: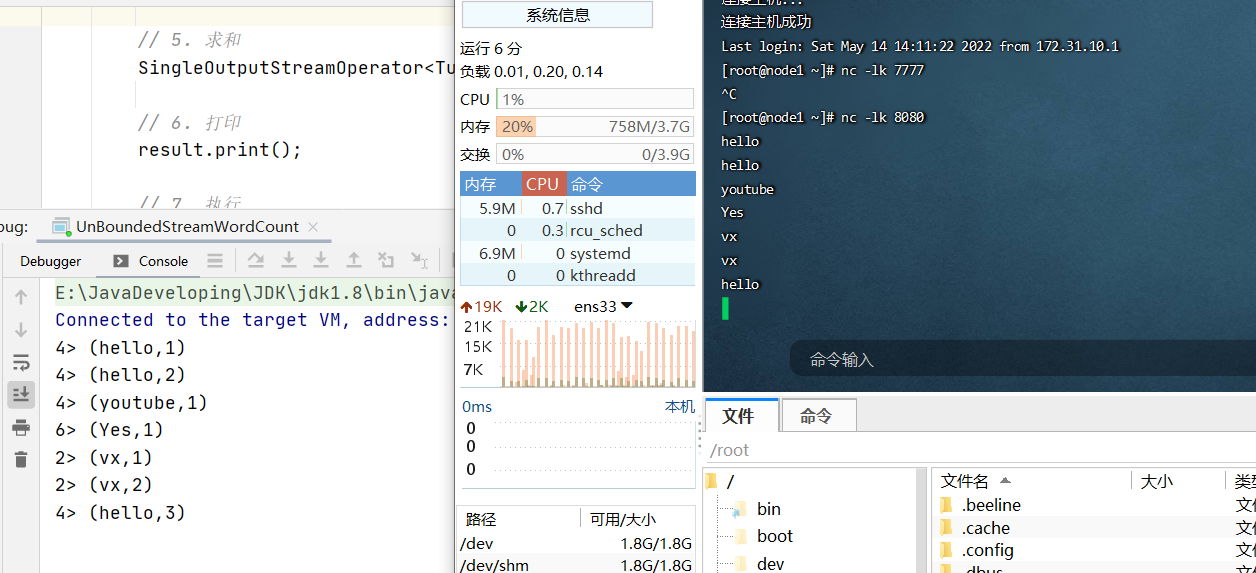

若有收获,就点个赞吧
0 人点赞
