HDFS基本介绍
HDFS 是 Hadoop Distribute File System 的简称,意为:Hadoop 分布式文件系统。是 Hadoop 核心组件之一,作为最底层的分布式存储服务而存在。
分布式文件系统解决的问题就是大数据存储。它们是横跨在多台计算机上的存储系统。分布式文件系统在大数据时代有着广泛的应用前景,它们为存储和处理超大规模数据提供所需的扩展能力。
可以把HDFS理解为将多个节点上的容量汇总到一起,拼接成一个大的文件系统,在一个节点上上传数据,在其他的节点上都能够访问使用。
HDFS的组成架构
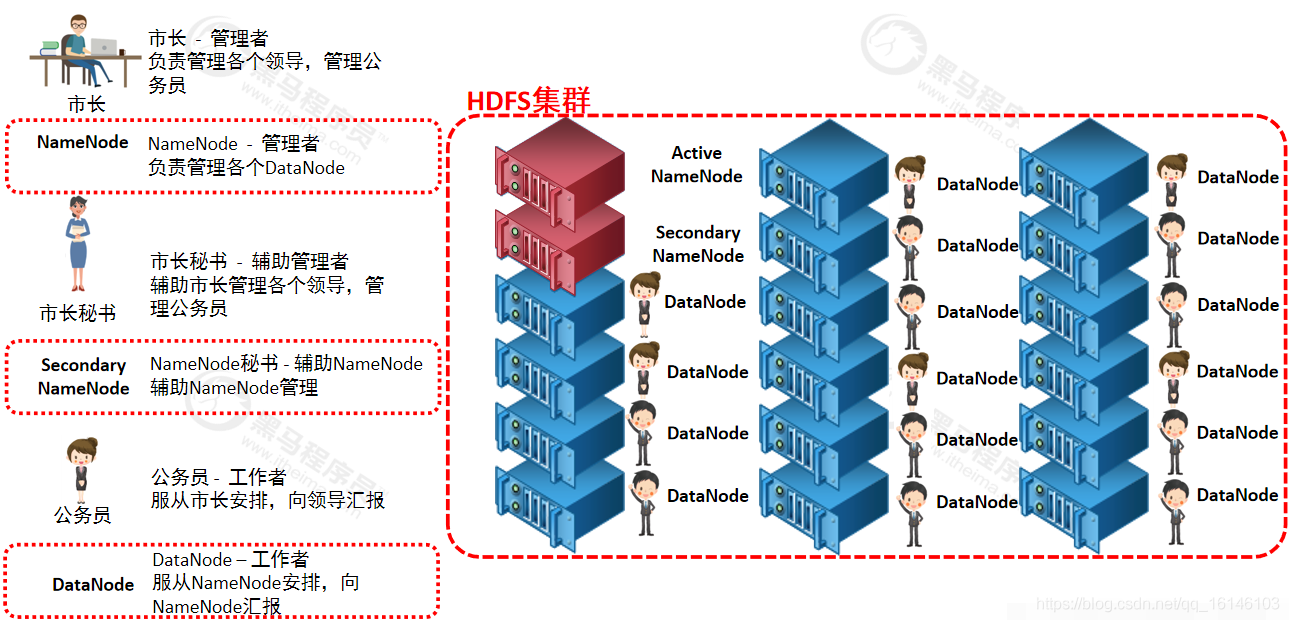
在HDFS中,使用主从节点的方式,即使用Master和Slave结构对集群进行管理。一般一个 HDFS 集群只有一个Namenode 和一定数目的Datanode 组成。Namenode 是 HDFS 集群主节点,Datanode 是 HDFS集群从节点,两种角色各司其职,共同协调完成分布式的文件存储服务。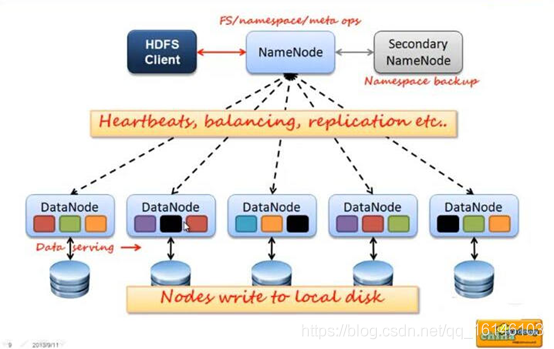
[
](https://blog.csdn.net/qq_16146103/article/details/105665463)
HDFS集群包括,NameNode,DataNode,client以及Secondary Namenode
HDFS将所有的文件全部抽象成为block块来进行存储,不管文件大小,全部一视同仁都是以block块的统一大小和形式进行存储,方便我们的分布式文件系统对文件的管理。
副本机制:
HDFS视硬件错误为常态,硬件服务器随时有可能发生故障。为了容错,文件的所有 block 都会有副本。每个文件的 block 大小和副本系数都是可配置的。应用程序可以指定某个文件的副本数目。副本系数可以在文件创建的时候指定,也可以在之后改变。
HDFS的优点
1.高容错性
二. HDFS的缺点
1. 不适合低延时数据访问
-
2. 无法高效的对大量小文件进行存储
- 存储大量小文件的话,它会占用NameNode大量的内存来存储文件
- 一个文件只能有一个写,不允许多个线程同时写
- 仅支持数据append(追加),不支持文件的随机修改
基于分布式机器的文件存储系统,操作文件肯定是比操作内存慢的;

若有收获,就点个赞吧
0 人点赞
