Flink 有非常灵活的分层 API 设计,其中的核心层就是 DataStream/DataSet API。由于新版本已经实现了流批一体, DataSet API 将被弃用,官方推荐统一使用 DataStream API 处理流数据和批数据。
DataStream 在用法上有些类似于常规的 Java 集合,但又有所不同。我们在代码中往往并不关心集合中具体的数据,而只是用 API 定义出一连串的操作来处理它们;这就叫作数据流的“转换”(transformations)。
一个 Flink 程序,其实就是对 DataStream 的各种转换。具体来说,代码基本上都由以下几部分构成,
⚫ 获取执行环境(execution environment)
⚫ 读取数据源(source)
⚫ 定义基于数据的转换操作(transformations)
⚫ 定义计算结果的输出位置(sink)
⚫ 触发程序执行(execute)
其中,获取环境和触发执行,都可以认为是针对执行环境的操作。所以本章我们就从执行环境、数据源(source)、转换操作(transformation)、输出(sink)四大部分,对常用的 DataStream API 做基本介绍。 
执行环境(Execution Environment)
创建执行环境
编 写 Flink 程 序 的 第 一 步 , 就 是 创 建 执 行 环 境 。 我 们 要 获 取 的 执 行 环 境 , 是StreamExecutionEnvironment 类的对象,这是所有 Flink 程序的基础。在代码中创建执行环境的方式,就是调用这个类的静态方法,具体有以下三种。
1. getExecutionEnvironment
最简单的方式,就是直接调用 getExecutionEnvironment 方法。它会根据当前运行的上下文直接得到正确的结果:如果程序是独立运行的,就返回一个本地执行环境;如果是创建了 jar包,然后从命令行调用它并提交到集群执行,那么就返回集群的执行环境。也就是说,这个方
法会根据当前运行的方式,自行决定该返回什么样的运行环境。 StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
这种“智能”的方式不需要我们额外做判断,用起来简单高效,是最常用的一种创建执行环境的方式 。
2. createLocalEnvironment
这个方法返回一个本地执行环境。可以在调用时传入一个参数,指定默认的并行度;如果不传入,则默认并行度就是本地的 CPU 核心数。 StreamExecutionEnvironment localEnv = StreamExecutionEnvironment.createLocalEnvironment() ;
3. createRemoteEnvironment
这个方法返回集群执行环境。需要在调用时指定 JobManager 的主机名和端口号,并指定要在集群中运行的 Jar 包。StreamExecutionEnvironment remoteEnv = StreamExecutionEnvironment<br />.createRemoteEnvironment(<br />"host", // JobManager 主机名<br />1234, // JobManager 进程端口号<br />"path/to/jarFile.jar" // 提交给 JobManager 的 JAR 包<br />);
在获取到程序执行环境后,我们还可以对执行环境进行灵活的设置。比如可以全局设置程序的并行度、禁用算子链,还可以定义程序的时间语义、配置容错机制。
执行模式(Execution Mode)
节中我们获取到的执行环境,是一个 StreamExecutionEnvironment,顾名思义它应该是做流处理的。那对于批处理,又应该怎么获取执行环境呢?
在之前的 Flink 版本中,批处理的执行环境与流处理类似,是调用类 ExecutionEnvironment的静态方法,返回它的对象 :
// 批处理环境ExecutionEnvironment batchEnv = ExecutionEnvironment.getExecutionEnvironment();// 流处理环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
基于 ExecutionEnvironment 读入数据创建的数据集合,就是 DataSet;对应的调用的一整套转换方法,就是 DataSet API。
而从 1.12.0 版本起, Flink 实现了 API 上的流批统一。 DataStream API 新增了一个重要特性:可以支持不同的“执行模式”(execution mode),通过简单的设置就可以让一段 Flink 程序在流处理和批处理之间切换。这样一来, DataSet API 也就没有存在的必要了。
⚫ 流执行模式(STREAMING)
这是 DataStream API 最经典的模式,一般用于需要持续实时处理的无界数据流。默认情况下,程序使用的就是 STREAMING 执行模式。
⚫ 批执行模式(BATCH)
专门用于批处理的执行模式, 这种模式下, Flink 处理作业的方式类似于 MapReduce 框架。对于不会持续计算的有界数据,我们用这种模式处理会更方便。
⚫ 自动模式(AUTOMATIC)
在这种模式下,将由程序根据输入数据源是否有界,来自动选择执行模式。
1. BATCH 模式的配置方法
由于 Flink 程序默认是 STREAMING 模式,我们这里重点介绍一下 BATCH 模式的配置。主要有两种方式:
(1)通过命令行配置 不指定就是STREAMINGbin/flink run -Dexecution.runtime-mode=BATCH ...在提交作业时,增加 execution.runtime-mode 参数,指定值为 BATCH。(2) 通过代码配置StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.BATCH);
在代码中,直接基于执行环境调用 setRuntimeMode 方法,传入 BATCH 模式。
建议: 不要在代码中配置, 而是使用命令行。这同设置并行度是类似的: 在提交作业时指定参数可以更加灵活,同一段应用程序写好之后,既可以用于批处理也可以用于流处理。而在代码中硬编码(hard code)的方式可扩展性比较差,一般都不推荐。
2. 什么时候选择 BATCH 模式
一个简单的原则就是:用 BATCH 模式处理批量数据,用 STREAMING模式处理流式数据。因为数据有界的时候,直接输出结果会更加高效;而当数据无界的时候, 我们没得选择——只有 STREAMING 模式才能处理持续的数据流。
触发程序执行
写完输出(sink)操作并不代表程序已经结束。因为当 main()方法被调用时,其实只是定义了作业的每个执行操作,然后添加到数据流图中;这时并没有真正处理数据——因为数据可能还没来。 Flink 是由事件驱动的,只有等到数据到来,才会触发真正的计算,这也被称为“延迟执行”或“懒执行”(lazy execution)。
所以我们需要显式地调用执行环境的 execute()方法,来触发程序执行。 execute()方法将一直等待作业完成,然后返回一个执行结果(JobExecutionResult)。
Flink 支持的数据类型
简单来说,对于常见的 Java 和 Scala 数据类型, Flink 都是支持的。 Flink 在内部, Flink对支持不同的类型进行了划分,这些类型可以在 Types 工具类中找到:
(1)基本类型
所有 Java 基本类型及其包装类,再加上 Void、 String、 Date、 BigDecimal 和 BigInteger。
(2)数组类型
包括基本类型数组(PRIMITIVE_ARRAY)和对象数组(OBJECT_ARRAY)
(3)复合数据类型
⚫ Java 元组类型(TUPLE):这是 Flink 内置的元组类型,是 Java API 的一部分。最多25 个字段,也就是从 Tuple0~Tuple25,不支持空字段
⚫ Scala 样例类及 Scala 元组:不支持空字段
⚫ 行类型(ROW):可以认为是具有任意个字段的元组,并支持空字段
⚫ POJO: Flink 自定义的类似于 Java bean 模式的类
(4)辅助类型
Option、 Either、 List、 Map 等
(5)泛型类型(GENERIC)
Flink 支持所有的 Java 类和 Scala 类。不过如果没有按照上面 POJO 类型的要求来定义,就会被 Flink 当作泛型类来处理。 Flink 会把泛型类型当作黑盒,无法获取它们内部的属性;它们也不是由 Flink 本身序列化的,而是由 Kryo 序列化的。
在这些类型中,元组类型和 POJO 类型最为灵活,因为它们支持创建复杂类型。而相比之下, POJO 还支持在键( key)的定义中直接使用字段名,这会让我们的代码可读性大大增加。所以,在项目实践中,往往会将流处理程序中的元素类型定为 Flink 的 POJO 类型。
Flink 对 POJO 类型的要求如下:
⚫ 类是公共的( public)和独立的( standalone,也就是说没有非静态的内部类);
⚫ 类有一个公共的无参构造方法;
⚫ 类中的所有字段是 public 且非 final 的;或者有一个公共的 getter 和 setter 方法,这些方法需要符合 Java bean 的命名规范。
元组的两个元素都是基本数据类型。那如果元组中的一个元素又有泛型,该怎么处理呢?
Flink 专门提供了 TypeHint 类,它可以捕获泛型的类型信息,并且一直记录下来,为运行时提供足够的信息。我们同样可以通过.returns()方法,明确地指定转换之后的 DataStream 里元素的类型。
聚合算子
1. 按键分区(keyBy)
对于 Flink 而言, DataStream 是没有直接进行聚合的 API 的。因为我们对海量数据做聚合肯定要进行分区并行处理,这样才能提高效率。所以在 Flink 中,要做聚合,需要先进行分区;这个操作就是通过 keyBy 来完成的。
keyBy 是聚合前必须要用到的一个算子。 keyBy 通过指定键(key),可以将一条流从逻辑上划分成不同的分区(partitions)。这里所说的分区,其实就是并行处理的子任务,也就对应着任务槽(task slot)。
基于不同的 key,流中的数据将被分配到不同的分区中去,这样一来,所有具有相同的 key 的数据,都将被发往同一个分区,那么下一步算子操作就将会在同一个 slot中进行处理了。 
在内部,是通过计算 key 的哈希值(hash code),对分区数进行取模运算来实现的。所以这里 key 如果是 POJO 的话,必须要重写 hashCode()方法。
keyBy()方法需要传入一个参数,这个参数指定了一个或一组 key。有很多不同的方法来指定 key:比如对于 Tuple 数据类型,可以指定字段的位置或者多个位置的组合;对于 POJO 类型,可以指定字段的名称(String);另外,还可以传入 Lambda 表达式或者实现一个键选择器(KeySelector),用于说明从数据中提取 key 的逻辑。
KeyedStream 也继承自 DataStream,所以基于它的操作也都归属于 DataStream API。但它跟之前的转换操作得到的SingleOutputStreamOperator 不同,只是一个流的分区操作,并不是一个转换算子。 KeyedStream 是一个非常重要的数据结构,只有基于它才可以做后续的聚合操作(比如 sum, reduce);而且它可以将当前算子任务的状态(state)也按照 key 进行划分、限定为仅对当前 key 有效。
简单聚合:
⚫ sum():在输入流上,对指定的字段做叠加求和的操作。
⚫ min():在输入流上,对指定的字段求最小值。
⚫ max():在输入流上,对指定的字段求最大值。
⚫ minBy():与 min()类似,在输入流上针对指定字段求最小值。不同的是, min()只计算指定字段的最小值,其他字段会保留最初第一个数据的值;而 minBy()则会返回包含字段最小值的整条数据。
⚫ maxBy():与 max()类似,在输入流上针对指定字段求最大值。两者区别与min()/minBy()完全一致。
带不带by的区别:(min/minBy 和 max/maxBy)
不带By 只计算指定字段的最大或最小值,其他字段维持不变和第一条数据一样,
带By,将返回最大或最小的整条的数据

物理分区: ———————————-> keyBy操作如果根据某个key分配的不均匀怎么处理?比如某个key的数据很多。
分区”(partitioning) 操作就是要将数据进行重新分布,传递到不同的流分区去进行下一步处理。
keyBy 它就是一种按照键的哈希值来进行重新分区的操作。只不过这种分区操作只能保证把数据按key“分开”,至于分得均不均匀、每个 key 的数据具体会分到哪一区去,这些是完全无从控制的——所以我们有时也说, keyBy 是一种逻辑分区(logical partitioning)操作。
如果说 keyBy 这种逻辑分区是一种“软分区”,那真正硬核的分区就应该是所谓的“物理分区”(physical partitioning)。也就是我们要真正控制分区策略,精准地调配数据,告诉每个数据到底去哪里。
有些时候,我们还需要手动控制数据分区分配策略。比如当发生数据倾斜的时候,系统无法自动调整,这时就需要我们重新进行负载均衡,将数据流较为平均地发送到下游任务操作分区中去。 Flink 对于经过转换操作之后的 DataStream,提供了一系列的底层操作接口,能够帮
我们实现数据流的手动重分区。为了同 keyBy 相区别,我们把这些操作统称为“物理分区”操作。物理分区与 keyBy 另一大区别在于, keyBy 之后得到的是一个 KeyedStream,而物理分区之后结果仍是 DataStream,且流中元素数据类型保持不变。从这一点也可以看出,分区算子并不对数据进行转换处理,只是定义了数据的传输方式。
常见的物理分区策略有随机分配(Random)、轮询分配(Round-Robin)、重缩放(Rescale)和广播(Broadcast)
1. 随机分区(shuffle)
最简单的重分区方式就是直接“洗牌”。通过调用 DataStream 的.shuffle()方法,将数据随机地分配到下游算子的并行任务中去。随机分区服从均匀分布(uniform distribution),所以可以把流中的数据随机打乱,均匀地传递到下游任务分区,因为是完全随机的,所以对于同样的输入数据, 每次执行得到的结果也不会相同。
轮询分区(Round-Robin)
轮询也是一种常见的重分区方式。简单来说就是“发牌”,按照先后顺序将数据做依次分发。通过调用 DataStream 的.rebalance()方法,就可以实现轮询重分区。 rebalance使用的是 Round-Robin 负载均衡算法,可以将输入流数据平均分配到下游的并行任务中去。重缩放分区(rescale)
重缩放分区和轮询分区非常相似。当调用 rescale()方法时,其实底层也是使用 Round-Robin算法进行轮询,但是只会将数据轮询发送到下游并行任务的一部分中。也就是说,“发牌人”如果有多个,那么 rebalance 的方式是每个发牌人都面向所有人发牌;而 rescale的做法是分成小团体,发牌人只给自己团体内的所有人轮流发牌。
由于 rebalance 是所有分区数据的“重新平衡”,当 TaskManager 数据量较多时,这种跨节点的网络传输必然影响效率;而如果我们配置的 task slot 数量合适,用 rescale 的方式进行“局部重缩放”,就可以让数据只在当前 TaskManager 的多个 slot 之间重新分配,从而避免了网络传输带来的损耗。
从底层实现上看, rebalance 和 rescale 的根本区别在于任务之间的连接机制不同。 rebalance将会针对所有上游任务(发送数据方)和所有下游任务(接收数据方)之间建立通信通道,这是一个笛卡尔积的关系;而 rescale 仅仅针对每一个任务和下游对应的部分任务之间建立通信
通道,节省了很多资源。广播(broadcast)
这种方式其实不应该叫做“重分区”,因为经过广播之后,数据会在不同的分区都保留一份,可能进行重复处理。可以通过调用 DataStream 的 broadcast()方法,将输入数据复制并发送到下游算子的所有并行任务中去。全局分区(global)
全局分区也是一种特殊的分区方式。这种做法非常极端,通过调用.global()方法,会将所有的输入流数据都发送到下游算子的第一个并行子任务中去。这就相当于强行让下游任务并行度变成了 1,所以使用这个操作需要非常谨慎,可能对程序造成很大的压力。
输出算子(Sink)
Flink 作为数据处理框架,最终还是要把计算处理的结果写入外部存储,为外部应用提供支持,本节将主要讲解 Flink 中的 Sink 操作。我们已经了解了 Flink 程序如何对数据进行读取、转换等操作,最后一步当然就应该将结果数据保存或输出到外部系统了。
Flink官方提供的连接器:
我们可以看到,像 Kafka 之类流式系统, Flink 提供了完美对接, source/sink 两端都能连接,可读可写;而对于 Elasticsearch、文件系统(FileSystem)、 JDBC 等数据存储系统,则只提供了输出写入的 sink 连接器。
除 Flink 官方之外, Apache Bahir 作为给 Spark 和 Flink 提供扩展支持的项目,也实现了一些其他第三方系统与 Flink 的连接器;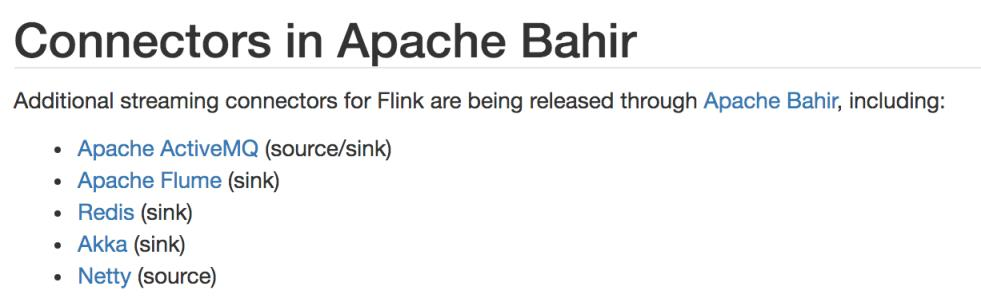
除此以外,就需要用户自定义实现 sink 连接器了。
1.输出到文件
对应着读取文件作为输入数据源, Flink 本来也有一些非常简单粗暴的输出到文件的预实现方法:如 writeAsText()、 writeAsCsv(),可以直
接将输出结果保存到文本文件或 Csv 文件。但我们知道,这种方式是不支持同时写入一份文件的;
Flink 为此专门提供了一个流式文件系统的连接器: StreamingFileSink,它继承自抽象类RichSinkFunction,而且集成了 Flink 的检查点(checkpoint)机制,用来保证精确一次(exactly once)的一致性语义。
StreamingFileSink 为批处理和流处理提供了一个统一的 Sink,它可以将分区文件写入 Flink支持的文件系统。它可以保证精确一次的状态一致性, 大大改进了之前流式文件 Sink 的方式。
它的主要操作是将数据写入桶(buckets),每个桶中的数据都可以分割成一个个大小有限的分区文件,这样一来就实现真正意义上的分布式文件存储。我们可以通过各种配置来控制“分桶”的操作; 默认的分桶方式是基于时间的,我们每小时写入一个新的桶。换句话说,每个桶内保存的文件,记录的都是 1 小时的输出数据。
StreamingFileSink 支持行编码(Row-encoded)和批量编码(Bulk-encoded, 比如 Parquet)格式。这两种不同的方式都有各自的构建器(builder),调用方法也非常简单,可以直接调用StreamingFileSink 的静态方法:
⚫ 行编码: StreamingFileSink.forRowFormat(basePath, rowEncoder)。
⚫ 批量编码: StreamingFileSink.forBulkFormat(basePath, bulkWriterFactory)。
在创建行或批量编码 Sink 时,我们需要传入两个参数,用来指定存储桶的基本路径(basePath)和数据的编码逻辑(rowEncoder 或 bulkWriterFactory)。
(1)行编码就是对输出流一行一行的写入
(2)块编码就是批量写入,类似于hbase的列式存储

若有收获,就点个赞吧
0 人点赞
