Flink支持多种安装模式
- Local—本地单机模式,学习测试时使用
- Standalone—独立集群模式,Flink自带集群,开发测试环境使用
- StandaloneHA—独立集群高可用模式,Flink自带集群,开发测试环境使用
- On Yarn—计算资源统一由Hadoop YARN管理,生产环境使用
1.1.1.1 为什么使用Flink On Yarn?
在实际开发中,使用Flink时,更多的使用方式是Flink On Yarn模式,原因如下:
-1.Yarn的资源可以按需使用,提高集群的资源利用率
-2.Yarn的任务有优先级,根据优先级运行作业
-3.基于Yarn调度系统,能够自动化地处理各个角色的 Failover(容错)
○ JobManager 进程和 TaskManager 进程都由 Yarn NodeManager 监控
○ 如果 JobManager 进程异常退出,则 Yarn ResourceManager 会重新调度 JobManager 到其他机器
○ 如果 TaskManager 进程异常退出,JobManager 会收到消息并重新向 Yarn ResourceManager 申请资源,重新启动 TaskManager。
Flink如何和Yarn进行交互?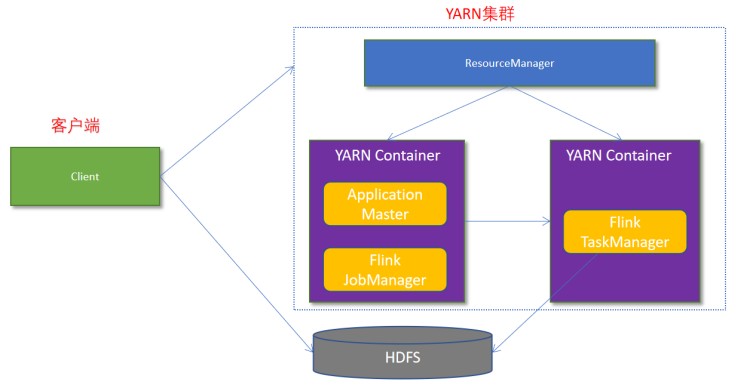
1.1.1.1 两种方式
1.1.1.1.1 Session模式
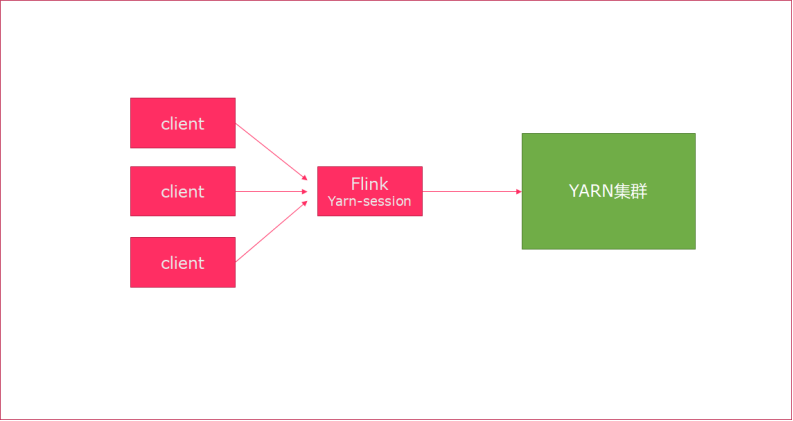
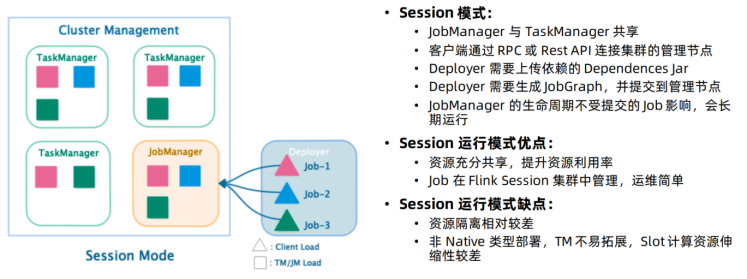
特点:需要事先申请资源,启动JobManager和TaskManger
优点:不需要每次递交作业申请资源,而是使用已经申请好的资源,从而提高执行效率
缺点:作业执行完成以后,资源不会被释放,因此一直会占用系统资源
应用场景:适合作业递交比较频繁的场景,小作业比较多的场景
1.1.1.1.2 Per-Job模式


特点:每次递交作业都需要申请一次资源
优点:作业运行完成,资源会立刻被释放,不会一直占用系统资源
缺点:每次递交作业都需要申请资源,会影响执行效率,因为申请资源需要消耗时间
应用场景:适合作业比较少的场景、大作业的场景
1.1.1 测试
1.1.1.1 Session模式
yarn-session.sh(开辟资源) + flink run(提交任务)
- 在yarn上启动一个Flink会话,node1上执行以下命令
/export/server/flink/bin/yarn-session.sh -n 2 -tm 800 -s 1 -d
说明:
申请2个CPU、1600M内存
# -n 表示申请2个容器,这里指的就是多少个taskmanager
# -tm 表示每个TaskManager的内存大小
# -s 表示每个TaskManager的slots数量
# -d 表示以后台程序方式运行
- 使用flink run提交任务:
/export/server/flink/bin/flink run /export/server/flink/examples/batch/WordCount.jar
运行完之后可以继续运行其他的小任务
/export/server/flink/bin/flink run /export/server/flink/examples/batch/WordCount.jar
- 关闭yarn-session:
yarn application -kill application_1599402747874_0001
1.1.1.2 Per-Job分离模式
1.直接提交job
/export/server/flink/bin/flink run -m yarn-cluster -yjm 1024 -ytm 1024 /export/server/flink/examples/batch/WordCount.jar
# -m jobmanager的地址
# -yjm 1024 指定jobmanager的内存信息
# -ytm 1024 指定taskmanager的内存信息
2.注意:
在之前版本中如果使用的是flink on yarn方式,想切换回standalone模式的话,如果报错需要删除:【/tmp/.yarn-properties-root】
rm -rf /tmp/.yarn-properties-root
因为默认查找当前yarn集群中已有的yarn-session信息中的jobmanager
1.1.1.3 参数总结
[root@node1 bin]# /export/server/flink/bin/flink —help
代码:
package cn.itcast.hello;import org.apache.flink.api.common.RuntimeExecutionMode;import org.apache.flink.api.common.typeinfo.Types;import org.apache.flink.api.java.functions.KeySelector;import org.apache.flink.api.java.tuple.Tuple2;import org.apache.flink.api.java.utils.ParameterTool;import org.apache.flink.streaming.api.datastream.DataStream;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import org.apache.flink.util.Collector;import java.util.Arrays;/*** Author itcast* Desc* 需求:使用Flink完成WordCount-DataStream--使用lambda表达式--修改代码使适合在Yarn上运行* 编码步骤* 1.准备环境-env* 2.准备数据-source* 3.处理数据-transformation* 4.输出结果-sink* 5.触发执行-execute//批处理不需要调用!流处理需要*/public class WordCount4_Yarn {public static void main(String[] args) throws Exception {//获取参数ParameterTool params = ParameterTool.fromArgs(args);String output = null;if (params.has("output")) {output = params.get("output");} else {output = "hdfs://node1:8020/wordcount/output_" + System.currentTimeMillis();}//1.准备环境-envStreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);//2.准备数据-sourceDataStream<String> linesDS = env.fromElements("itcast hadoop spark", "itcast hadoop spark", "itcast hadoop", "itcast");//3.处理数据-transformationDataStream<Tuple2<String, Integer>> result = linesDS.flatMap((String value, Collector<String> out) -> Arrays.stream(value.split(" ")).forEach(out::collect)).returns(Types.STRING).map((String value) -> Tuple2.of(value, 1)).returns(Types.TUPLE(Types.STRING, Types.INT))//.keyBy(0);.keyBy((KeySelector<Tuple2<String, Integer>, String>) t -> t.f0).sum(1);//4.输出结果-sinkresult.print();//如果执行报hdfs权限相关错误,可以执行 hadoop fs -chmod -R 777 /System.setProperty("HADOOP_USER_NAME", "root");//设置用户名//result.writeAsText("hdfs://node1:8020/wordcount/output_"+System.currentTimeMillis()).setParallelism(1);result.writeAsText(output).setParallelism(1);//5.触发执行-executeenv.execute();}}

若有收获,就点个赞吧
0 人点赞
