MapReduce特点:
高容错性:
Hadoop集群是分布式搭建和部署的,任何单一机器节点宕机了,它可以把上面的计算任务转移到另一个节点上运行,不影响整个作业任务的完成,过程
完全是由Hadoop内部完成的。
适合海量数据的离线处理:
可以处理GB,TB和PB级别的数据量
其他的框架如spark,flink都是基于内存,速度快,但是不如MapReduce稳定。
MapReduce局限性:
实时计算性能差:
MapReduce主要应用于离线作业,无法做到秒级或者亚秒级的数据响应
不能进行流式计算:
流式计算特点是数据源源不断的计算,并且数据是动态的;而MapReduce作为一个离线计算框架,主要是针对静态数据的,数据是不能动态变化得。

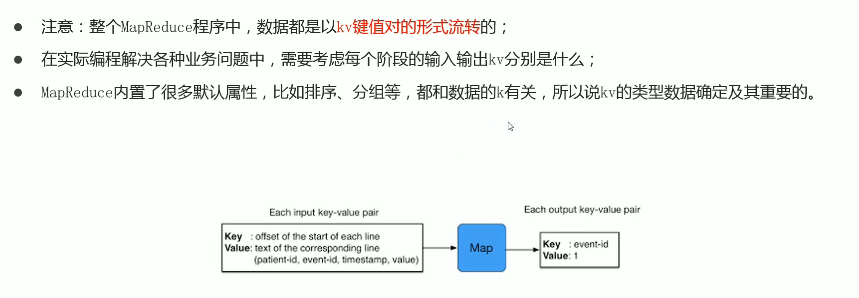
shuffle 洗牌,排序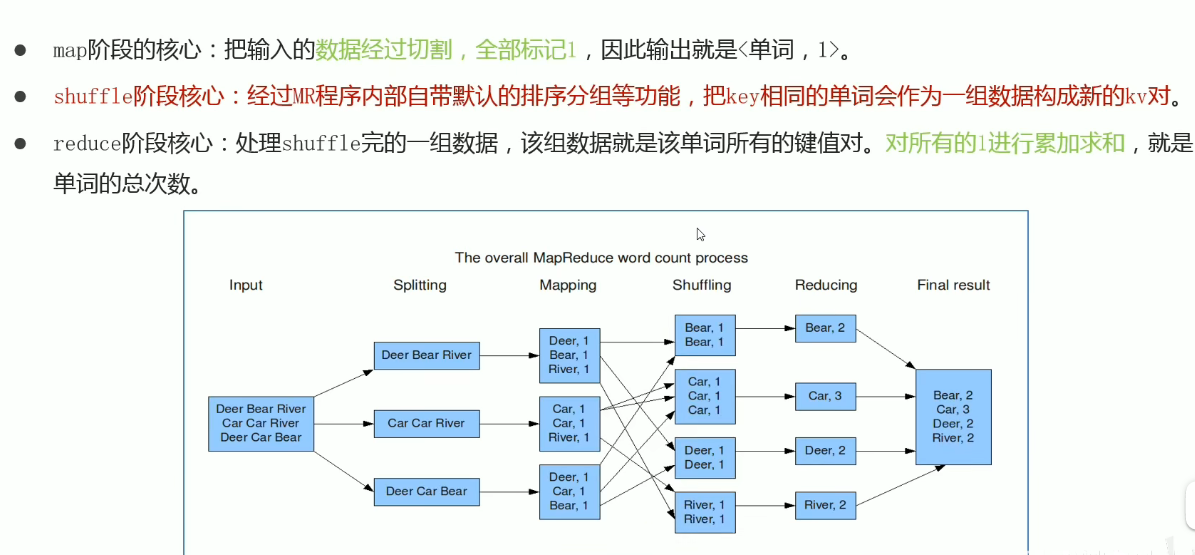
MAP执行过程:
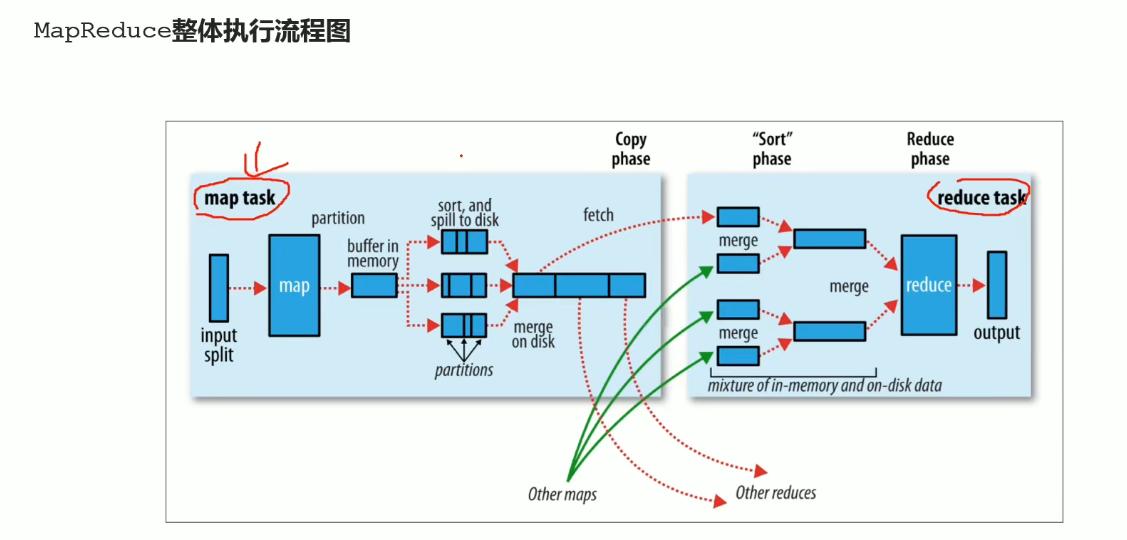

内存缓冲区满了就写入磁盘
Reduce执行过程: MapTask数据合并

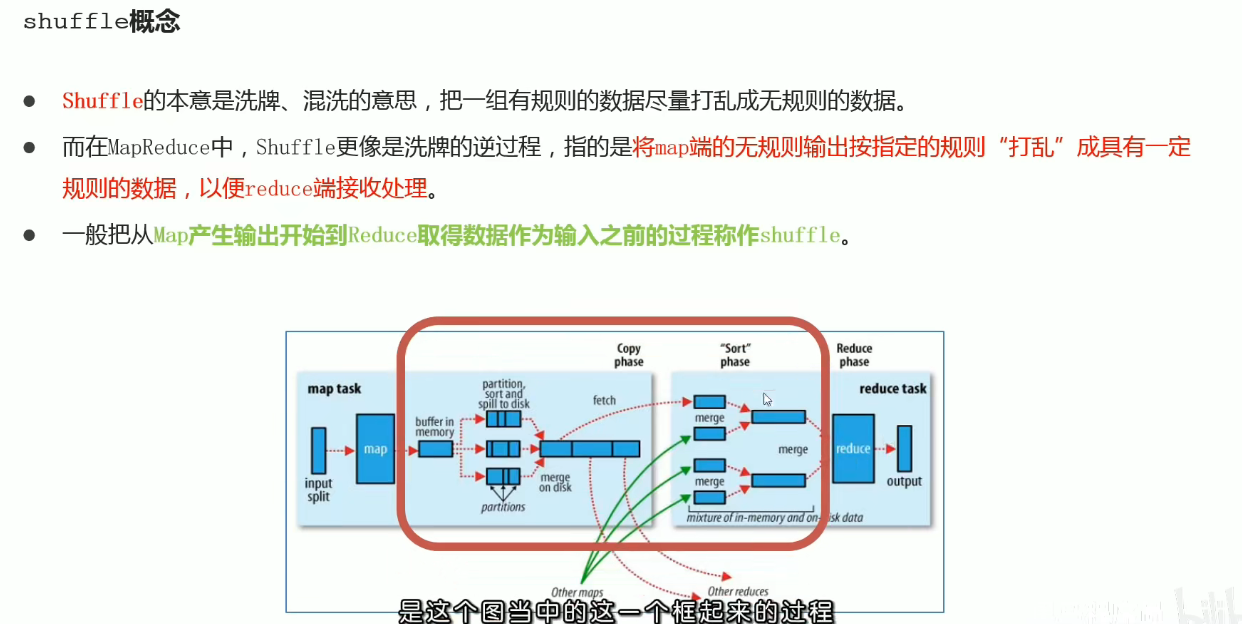
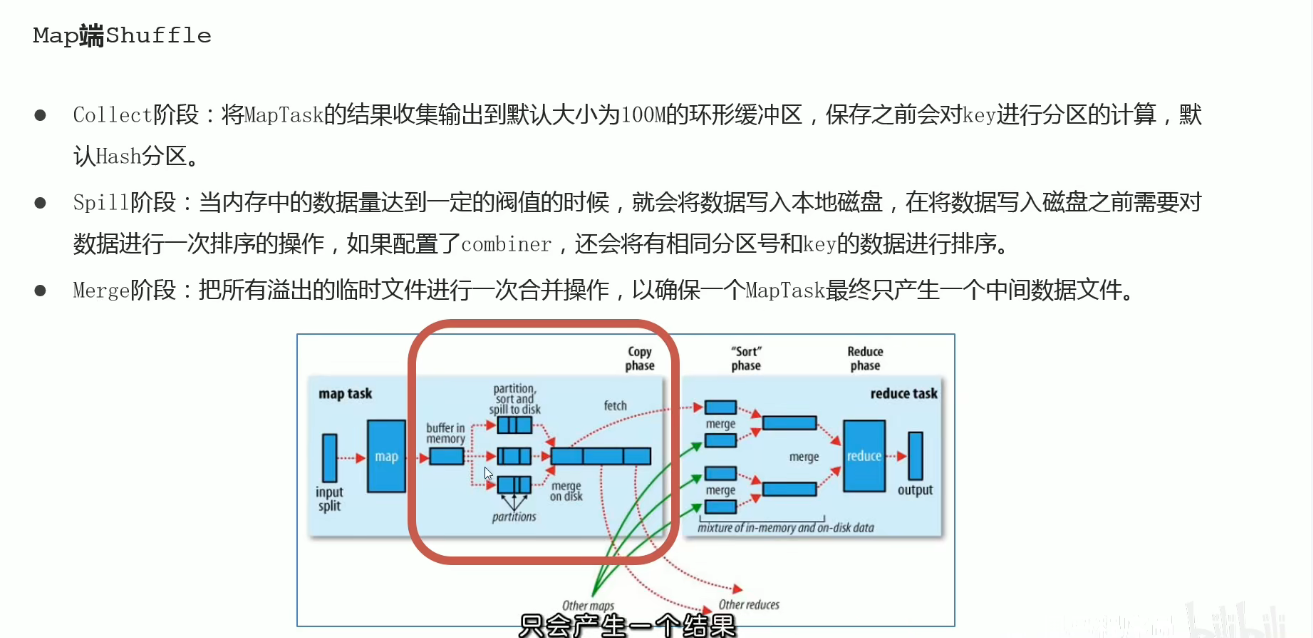
Shuffle过程:



若有收获,就点个赞吧
0 人点赞
