2.3 复用对象
stream.apply(new WindowFunction<WikipediaEditEvent, Tuple2<String, Long>, String, TimeWindow>() {@Overridepublic void apply(String userName, TimeWindow timeWindow, Iterable<WikipediaEditEvent> iterable,Collector<Tuple2<String, Long>> collector) throws Exception {long changesCount = ...// A new Tuple instance is created on every executioncollector.collect(new Tuple2<>(userName, changesCount));}}
可以看出,apply函数每执行一次,都会新建一个Tuple2类的实例,因此增加了对垃圾收集器的压力。解决这个问题的一种方法是反复使用相同的实例:
stream.apply(new WindowFunction<WikipediaEditEvent, Tuple2<String, Long>, String, TimeWindow>() {// Create an instance that we will reuse on every callprivate Tuple2<String, Long> result = new Tuple<>();@Overridepublic void apply(String userName, TimeWindow timeWindow, Iterable<WikipediaEditEvent> iterable, Collector<Tuple2<String, Long>> collector) throws Exception {long changesCount = ...// Set fields on an existing object instead of creating a new oneresult.f0 = userName;// Auto-boxing!! A new Long value may be createdresult.f1 = changesCount;// Reuse the same Tuple2 objectcollector.collect(result);}}
这种做法其实还间接创建了Long类的实例。
为了解决这个问题,Flink有许多所谓的value class:IntValue、LongValue、StringValue、FloatValue等。下面介绍一下如何使用它们:
stream.apply(new WindowFunction<WikipediaEditEvent, Tuple2<String, Long>, String, TimeWindow>() {// Create a mutable count instanceprivate LongValue count = new LongValue();// Assign mutable count to the tupleprivate Tuple2<String, LongValue> result = new Tuple<>("", count);@Override// Notice that now we have a different return typepublic void apply(String userName, TimeWindow timeWindow, Iterable<WikipediaEditEvent> iterable, Collector<Tuple2<String, LongValue>> collector) throws Exception {long changesCount = ...// Set fields on an existing object instead of creating a new oneresult.f0 = userName;// Update mutable count valuecount.setValue(changesCount);// Reuse the same tuple and the same LongValue instancecollector.collect(result);}}
2.4 数据倾斜
我们的flink程序中如果使用了keyBy等分组的操作,很容易就出现数据倾斜的情况,数据倾斜会导致整体计算速度变慢,有些子节点甚至接受不到数据,导致分配的资源根本没有利用上。
带有窗口的操作
○ 带有窗口的每个窗口中所有数据的分布不平均,某个窗口处理数据量太大导致速率慢
○ 导致Source数据处理过程越来越慢
○ 再导致所有窗口处理越来越慢
不带有窗口的操作
○ 有些子节点接受处理的数据很少,甚至得不到数据,导致分配的资源根本没有利用上
WebUI体现: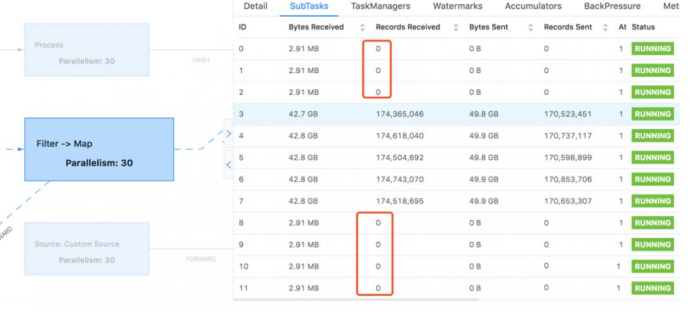
WebUI中Subtasks中打开每个窗口可以看到每个窗口进程的运行情况:如上图,数据分布很不均匀,导致部分窗口数据处理缓慢;
l 优化方式:
- 对key进行均匀的打散处理(hash,加盐等)
- 自定义分区器
- 使用Rebalabce
- 异步IO
- 合理调整并行度(数据过滤之后可以减少并行度)
- 数据合并之后 再处理之前可以增加并行度
- 大量小文件写入到HDFS 可以减少并行度
注意:Rebalance是在数据倾斜的情况下使用,不倾斜不要使用,否则会因为shuffle产生大量的网络开销;
3. Flink-内存管理
3.1 问题引入
Flink本身基本是以Java语言完成的,理论上说,直接使用JVM的虚拟机的内存管理就应该更简单方便,但Flink还是单独抽象出了自己的内存管理
因为Flink是为大数据而产生的,而大数据使用会消耗大量的内存,而JVM的内存管理管理设计是兼顾平衡的,不可能单独为了大数据而修改,这对于Flink来说,非常的不灵活,而且频繁GC会导致长时间的机器暂停应用,这对于大数据的应用场景来说也是无法忍受的。
JVM在大数据环境下存在的问题:
1.Java 对象存储密度低。在HotSpot JVM中,每个对象占用的内存空间必须是8的倍数,那么一个只包含 boolean 属性的对象就要占用了16个字节内存:对象头占了8个,boolean 属性占了1个,对齐填充占了7个。而实际上我们只想让它占用1个bit。
2.在处理大量数据尤其是几十甚至上百G的内存应用时会生成大量对象,Java GC可能会被反复触发,其中Full GC或Major GC的开销是非常大的,GC 会达到秒级甚至分钟级。
3.OOM 问题影响稳定性。OutOfMemoryError是分布式计算框架经常会遇到的问题,当JVM中所有对象大小超过分配给JVM的内存大小时,就会发生OutOfMemoryError错误,导致JVM崩溃,分布式框架的健壮性和性能都会受到影响。

3.2 内存划分
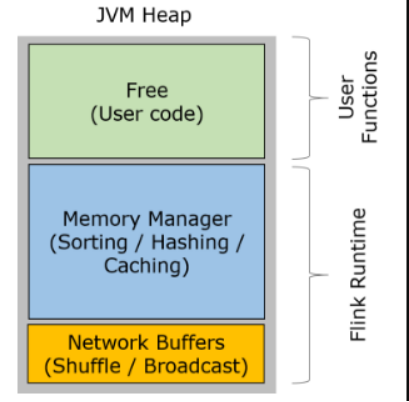
注意:Flink的内存管理是在JVM的基础之上,自己进行的管理,但是还没有逃脱的JVM,具体怎么实现,现阶段我们搞不定
1. 网络缓冲区Network Buffers:这个是在TaskManager启动的时候分配的,这是一组用于缓存网络数据的内存,每个块是32K,默认分配2048个,可以通过“taskmanager.network.numberOfBuffers”修改
2. 内存池Memory Manage pool:大量的Memory Segment块,用于运行时的算法(Sort/Join/Shufflt等),这部分启动的时候就会分配。默认情况下,占堆内存的70% 的大小。
3. 用户使用内存Remaining (Free) Heap: 这部分的内存是留给用户代码以及 TaskManager的数据使用的。
1.1 堆外内存
除了JVM之上封装的内存管理,还会有个一个很大的堆外内存,用来执行一些IO操作
启动超大内存(上百GB)的JVM需要很长时间,GC停留时间也会很长(分钟级)。
使用堆外内存可以极大地减小堆内存(只需要分配Remaining Heap),使得 TaskManager 扩展到上百GB内存不是问题。
进行IO操作时,使用堆外内存(可以理解为使用操作系统内存)可以zero-copy,使用堆内JVM内存至少要复制一次(需要在操作系统和JVM直接进行拷贝)。
堆外内存在进程间是共享的。
总结:
Flink相对于Spark,堆外内存该用还是用, 堆内内存管理做了自己的封装,不受JVM的GC影响;
3.4 序列化与反序列化
Flink除了对堆内内存做了封装之外,还实现了自己的序列化和反序列化机制
序列化与反序列化可以理解为编码与解码的过程。序列化以后的数据希望占用比较小的空间,而且数据能够被正确地反序列化出来。为了能正确反序列化,序列化时仅存储二进制数据本身肯定不够,需要增加一些辅助的描述信息。此处可以采用不同的策略,因而产生了很多不同的序列化方法。
Java本身自带的序列化和反序列化的功能,但是辅助信息占用空间比较大,在序列化对象时记录了过多的类信息。
Flink实现了自己的序列化框架,使用TypeInformation表示每种数据类型,所以可以只保存一份对象Schema信息,节省存储空间。又因为对象类型固定,所以可以通过偏移量存取。
l TypeInformation 支持以下几种类型:
- BasicTypeInfo: 任意Java 基本类型或 String 类型。
- BasicArrayTypeInfo: 任意Java基本类型数组或 String 数组。
- WritableTypeInfo: 任意 Hadoop Writable 接口的实现类。
- TupleTypeInfo: 任意的 Flink Tuple 类型(支持Tuple1 to Tuple25)。Flink tuples 是固定长度固定类型的Java Tuple实现。
- CaseClassTypeInfo: 任意的 Scala CaseClass(包括 Scala tuples)。
- PojoTypeInfo: 任意的 POJO (Java or Scala),例如,Java对象的所有成员变量,要么是 public 修饰符定义,要么有 getter/setter 方法。
- GenericTypeInfo: 任意无法匹配之前几种类型的类。(除了该数据使用kyro序列化.上面的其他的都是用二进制)

针对前六种类型数据集,Flink皆可以自动生成对应的TypeSerializer,能非常高效地对数据集进行序列化和反序列化。对于最后一种数据类型,Flink会使用Kryo进行序列化和反序列化。每个TypeInformation中,都包含了serializer,类型会自动通过serializer进行序列化,然后用Java Unsafe接口(具有像C语言一样的操作内存空间的能力)写入MemorySegments。
Flink通过自己的序列化和反序列化,可以将数据进行高效的存储,不浪费内存空间

若有收获,就点个赞吧
0 人点赞
