
整体来说,流式数据上的操作可以分为四类。
- 第一类是对于单条记录的操作,比如筛除掉不符合要求的记录(Filter 操作),或者将每条记录都做一个转换(Map 操作)
- 第二类是对多条记录的操作。比如说统计一个小时内的订单总成交量,就需要将一个小时内的所有订单记录的成交量加到一起。为了支持这种类型的操作,就得通过 Window 将需要的记录关联到一起进行处理
- 第三类是对多个流进行操作并转换为单个流。例如,多个流可以通过 Union、Join 或 Connect 等操作合到一起。这些操作合并的逻辑不同,但是它们最终都会产生了一个新的统一的流,从而可以进行一些跨流的操作。
- 最后, DataStream 还支持与合并对称的拆分操作,即把一个流按一定规则拆分为多个流(Split 操作),每个流是之前流的一个子集,这样我们就可以对不同的流作不同的处理。
1.1 基本操作
1.1.1 map
map:将函数作用在集合中的每一个元素上,并返回作用后的结果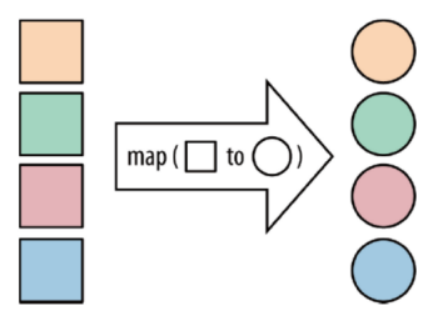
1.1.2 flatMap
flatMap:将集合中的每个元素变成一个或多个元素,并返回扁平化之后的结果
1.1.3 keyBy
按照指定的key来对流中的数据进行分组,流处理中没有groupBy,而是keyBy
1.1.4 filter
filter:按照指定的条件对集合中的元素进行过滤,过滤出返回true/符合条件的元素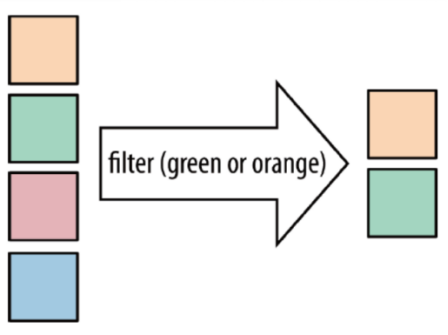
1.1.5 sum
sum:按照指定的字段对集合中的元素进行求和1.1.6 reduce
reduce:对集合中的元素进行聚合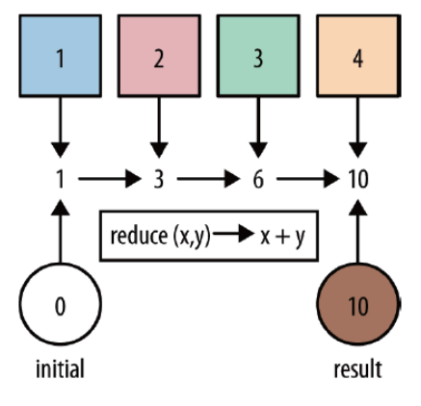
1.2 合并-拆分
1.2.1 union和connect
union:
union算子可以合并多个同类型的数据流,并生成同类型的数据流,即可以将多个DataStream[T]合并为一个新的DataStream[T]。数据将按照先进先出(First In First Out)的模式合并,且不去重。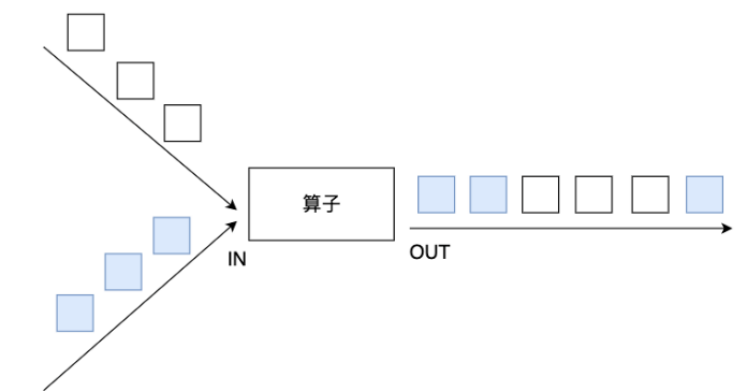
connect:
connect提供了和union类似的功能,用来连接两个数据流,它与union的区别在于:
connect只能连接两个数据流,union可以连接多个数据流。
connect所连接的两个数据流的数据类型可以不一致,union所连接的两个数据流的数据类型必须一致。
两个DataStream经过connect之后被转化为ConnectedStreams,ConnectedStreams会对两个流的数据应用不同的处理方法,且双流之间可以共享状态。
//需求//将两个String类型的流进行union//将一个String类型和一个Long类型的流进行connect
1.2.2 split、select和Side Outputs 拆分
Side Outputs:可以使用process方法对流中数据进行处理,并针对不同的处理结果将数据收集到不同的OutputTag中
//对流中的数据按照奇数和偶数进行分流,并获取分流后的数据//也可以比如将股票进行沪市,深市的拆分等
1.3 分区
1.3.1 rebalance重平衡分区
类似于Spark中的repartition,但是功能更强大,可以直接解决数据倾斜
Flink也有数据倾斜的时候,比如当前有数据量大概10亿条数据需要处理,在处理过程中可能会发生如图所示的状况,出现了数据倾斜,其他3台机器执行完毕也要等待机器1执行完毕后才算整体将任务完成;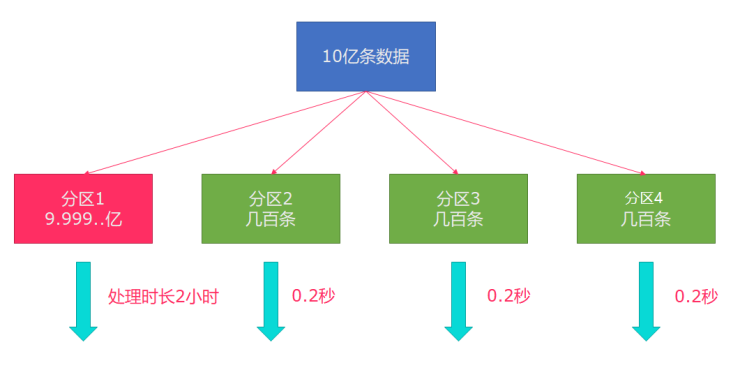
所以在实际的工作中,出现这种情况比较好的解决方案就是rebalance(内部使用round robin方法将数据均匀打散)
//重平衡分区打散
其他的API分区方式: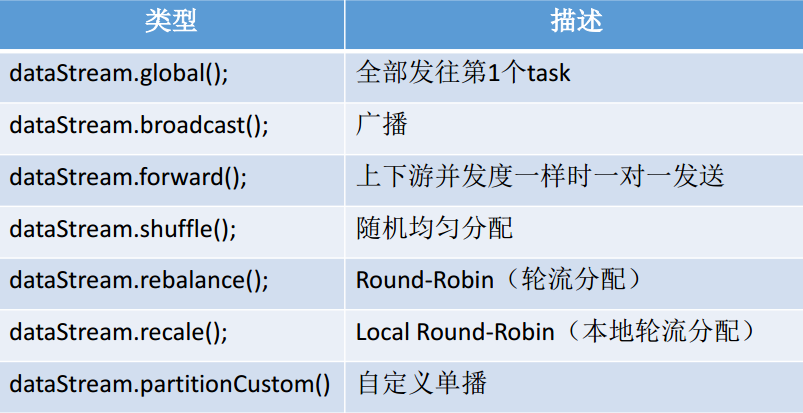
说明:
recale分区。基于上下游Operator的并行度,将记录以循环的方式输出到下游Operator的每个实例。
举例:
上游并行度是2,下游是4,则上游一个并行度以循环的方式将记录输出到下游的两个并行度上;上游另一个并行度以循环的方式将记录输出到下游另两个并行度上。若上游并行度是4,下游并行度是2,则上游两个并行度将记录输出到下游一个并行度上;上游另两个并行度将记录输出到下游另一个并行度上。
1.4 Kafka集成
1.4.1 pom依赖
Flink 里已经提供了一些绑定的 Connector,例如 kafka source 和 sink,Es sink 等。读写 kafka、es、rabbitMQ 时可以直接使用相应 connector 的 api 即可,虽然该部分是 Flink 项目源代码里的一部分,但是真正意义上不算作 Flink 引擎相关逻辑,并且该部分没有打包在二进制的发布包里面。所以在提交 Job 时候需要注意, job 代码 jar 包中一定要将相应的 connetor 相关类打包进去,否则在提交作业时就会失败,提示找不到相应的类,或初始化某些类异常。
1.4.2 参数设置
以下参数都必须/建议设置上
1.订阅的主题
2.反序列化规则
3.消费者属性-集群地址
4.消费者属性-消费者组id(如果不设置,会有默认的,但是默认的不方便管理)
5.消费者属性-offset重置规则,如earliest/latest…
6.动态分区检测(当kafka的分区数变化/增加时,Flink能够检测到!)
7.如果没有设置Checkpoint,那么可以设置自动提交offset,后续学习了Checkpoint会把offset随着做Checkpoint的时候提交到Checkpoint和默认主题中
1.4.3 参数说明
1.4.1 Topic / Partition 订阅
Kafka Source 提供了 3 种 Topic / Partition 的订阅方式:(1)Topic 列表,订阅 Topic 列表中所有 Partition 的消息:KafkaSource.builder().setTopics("topic-a", "topic-b");(2)正则表达式匹配,订阅与正则表达式所匹配的 Topic 下的所有 Partition:KafkaSource.builder().setTopicPattern("topic.*");(3)Partition 列表,订阅指定的 Partition:final HashSet<TopicPartition> partitionSet = new HashSet<>(Arrays.asList(new TopicPartition("topic-a", 0), // Partition 0 of topic "topic-a"new TopicPartition("topic-b", 5))); // Partition 5 of topic "topic-b"KafkaSource.builder().setPartitions(partitionSet);
1.4.2 消息解析 #
https://nightlies.apache.org/flink/flink-docs-release-1.15/zh/docs/connectors/datastream/kafka/
代码中需要提供一个反序列化器(Deserializer)来对 Kafka 的消息进行解析。
反序列化器通过 setDeserializer(KafkaRecordDeserializationSchema) 来指定,其中 KafkaRecordDeserializationSchema 定义了如何解析 Kafka 的 ConsumerRecord。
如果只需要 Kafka 消息中的消息体(value)部分的数据,可以使用 KafkaSource 构建类中的 setValueOnlyDeserializer(DeserializationSchema) 方法,其中 DeserializationSchema 定义了如何解析 Kafka 消息体中的二进制数据。
也可使用 Kafka 提供的解析器 来解析 Kafka 消息体。例如使用 StringDeserializer 来将 Kafka 消息体解析成字符串:
import org.apache.kafka.common.serialization.StringDeserializer;
KafkaSource.<String>builder() .setDeserializer(KafkaRecordDeserializationSchema.valueOnly(StringDeserializer.class));
1.4.3 起始消费位点 #
KafkaSource.builder()// 从消费组提交的位点开始消费,不指定位点重置策略.setStartingOffsets(OffsetsInitializer.committedOffsets())// 从消费组提交的位点开始消费,如果提交位点不存在,使用最早位点.setStartingOffsets(OffsetsInitializer.committedOffsets(OffsetResetStrategy.EARLIEST))// 从时间戳大于等于指定时间的数据开始消费.setStartingOffsets(OffsetsInitializer.timestamp(1592323200L))// 从最早位点开始消费.setStartingOffsets(OffsetsInitializer.earliest())// 从最末尾位点开始消费.setStartingOffsets(OffsetsInitializer.latest());
1.4.4 Kafka命令
● 查看当前服务器中的所有topic
/export/server/kafka/bin/kafka-topics.sh —list —zookeeper node1:2181
● 创建topic
/export/server/kafka/bin/kafka-topics.sh —create —zookeeper node1:2181 —replication-factor 2 —partitions 3 —topic flink_kafka
● 查看某个Topic的详情
/export/server/kafka/bin/kafka-topics.sh —topic flink_kafka —describe —zookeeper node1:2181
● 删除topic
/export/server/kafka/bin/kafka-topics.sh —delete —zookeeper node1:2181 —topic flink_kafka
● 通过shell命令发送消息
/export/server/kafka/bin/kafka-console-producer.sh —broker-list node1:9092 —topic flink_kafka
● 通过shell消费消息
/export/server/kafka/bin/kafka-console-consumer.sh —bootstrap-server node1:9092 —topic flink_kafka —from-beginning
● 修改分区
/export/server/kafka/bin/kafka-topics.sh —alter —partitions 4 —topic flink_kafka —zookeeper node1:2181
Kafka消费:

实际的生产环境中可能有这样一些需求,比如:
- 场景一:有一个 Flink 作业需要将五份数据聚合到一起,五份数据对应五个 kafka topic,随着业务增长,新增一类数据,同时新增了一个 kafka topic,如何在不重启作业的情况下作业自动感知新的 topic。
- 场景二:作业从一个固定的 kafka topic 读数据,开始该 topic 有 10 个 partition,但随着业务的增长数据量变大,需要对 kafka partition 个数进行扩容,由 10 个扩容到 20。该情况下如何在不重启作业情况下动态感知新扩容的 partition?
- 针对上面的两种场景,首先需要在构建FlinkKafkaConsumer 时的 properties 中设置 flink.partition-discovery.interval-millis 参数为非负值,表示开启动态发现的开关,以及设置的时间间隔。此时 FlinkKafkaConsumer 内部会启动一个单独的线程定期去 kafka 获取最新的 meta 信息。
- 针对场景一,还需在构建 FlinkKafkaConsumer 时,topic 的描述可以传一个正则表达式描述的 pattern。每次获取最新 kafka meta 时获取正则匹配的最新 topic 列表。
- 针对场景二,设置前面的动态发现参数,在定期获取 kafka 最新 meta 信息时会匹配新的 partition。为了保证数据的正确性,新发现的 partition 从最早的位置开始读取。

开启 checkpoint 时 offset 是 Flink 通过状态 state 管理和恢复的,并不是从 kafka 的 offset 位置恢复。在 checkpoint 机制下,作业从最近一次checkpoint 恢复,本身是会回放部分历史数据,导致部分数据重复消费,Flink 引擎仅保证计算状态的精准一次,要想做到端到端精准一次需要依赖一些幂等的存储系统或者事务操作。
1.5 其他API
1.5.1 累加器
Flink中的累加器,与Mapreduce counter的应用场景类似,可以很好地观察task在运行期间的数据变化,如在Flink job任务中的算子函数中操作累加器,在任务执行结束之后才能获得累加器的最终结果。
Flink有以下内置累加器,每个累加器都实现了Accumulator接口。
IntCounter
LongCounter
DoubleCounter
1.5.2 广播变量
Flink支持广播。可以将数据广播到TaskManager上就可以供TaskManager中的SubTask/task去使用,数据存储到内存中。这样可以减少大量的shuffle操作,而不需要多次传递给集群节点;
比如在数据join阶段,不可避免的就是大量的shuffle操作,我们可以把其中一个dataSet广播出去,一直加载到taskManager的内存中,可以直接在内存中拿数据,避免了大量的shuffle,导致集群性能下降;
- 可以理解广播就是一个公共的共享变量
- 将一个数据集广播后,不同的Task都可以在节点上获取到
- 每个节点只存一份
- 如果不使用广播,每一个Task都会拷贝一份数据集,造成内存资源浪费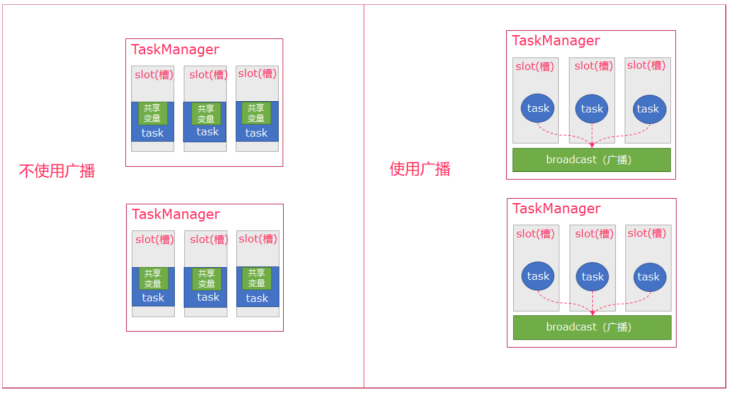
广播变量是要把dataset广播到内存中,所以广播的数据量不能太大,否则会出现OOM
广播变量的值不可修改,这样才能确保每个节点获取到的值都是一致的
1.5.3 分布式缓存
Flink提供了一个类似于Hadoop的分布式缓存,让并行运行实例的函数可以在本地访问。这个功能可以被使用来分享外部静态的数据,例如:机器学习的逻辑回归模型等。
注意:广播变量是将变量分发到各个TaskManager节点的内存上,分布式缓存是将文件缓存到各个TaskManager节点上;

若有收获,就点个赞吧
0 人点赞
