Apache Hive元数据 :
什么是元数据:
元数据(Metadata),又称中介数据、中继数据,为描述数据的数据(data about data),主要是描述数据属性(property)的信息,用来支持如指示存储位置、历史数据、资源查找、文件记录等功能。
Hive Metadata :
(1)Hive Metadata即Hive的元数据。
(2)包含用Hive创建的database、 table、表的位置、类型、属性,字段顺序类型等元信息。
(3)元数据存储在关系型数据库中。如hive内置的Derby、或者第三方如MySQL等。
Hive Metastore :
(1)Metastore即元数据服务。 Metastore服务的作用是管理metadata元数据,对外暴露服务地址,让各种客户端通过连接metastore服务,由metastore再去连接MySQL数据库来存取元数据。
(2)有了metastore服务,就可以有多个客户端同时连接,而且这些客户端不需要知道MySQL数据库的用户名和密码,只需要连接metastore 服务即可。某种程度上也保证了hive元数据的安全。 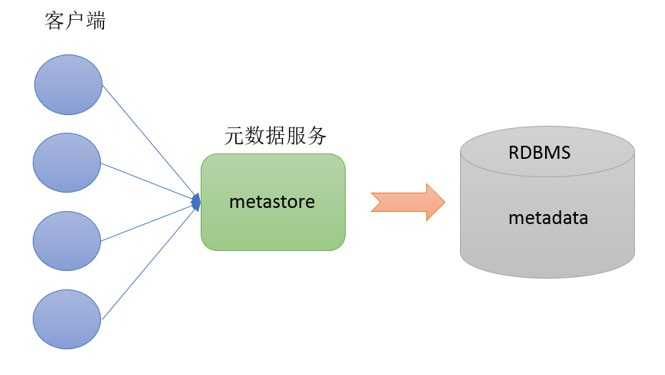
metastore配置方式:
metastore服务配置有3种模式: 内嵌模式、本地模式、 远程模式。
区分3种配置方式的关键是弄清楚两个问题:
Metastore服务是否需要单独配置、单独启动?
Metadata是存储在内置的derby中,还是第三方RDBMS,比如MySQL。
本系列课程中使用企业推荐模式—远程模式部署。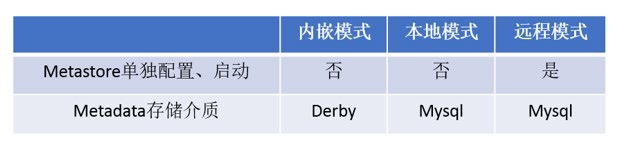
metastore远程模式 :
在生产环境中,建议用远程模式来配置Hive Metastore。在这种情况下,其他依赖hive的软件都可以通过Metastore访问hive。由于还可以完全屏蔽数据库层,因此这也带来了更好的可管理性/安全性。 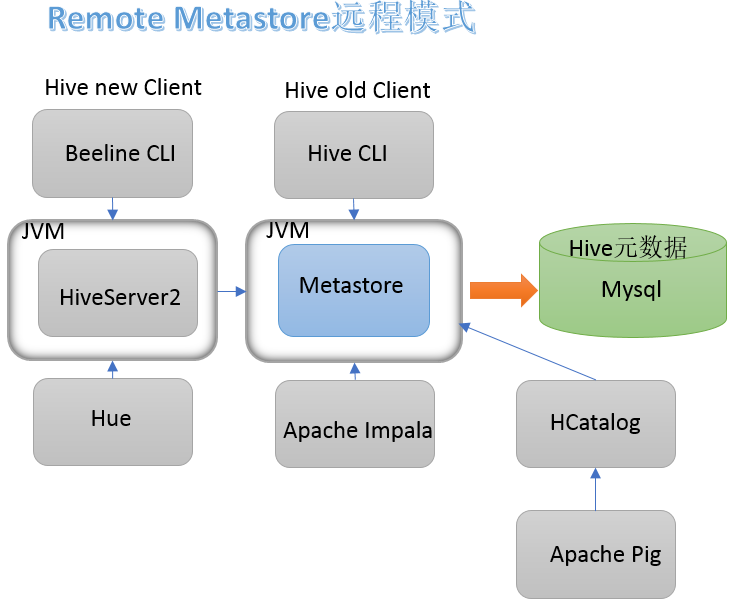
Apache Hive部署实战
安装前准备 :
(1)由于Apache Hive是一款基于Hadoop的数据仓库软件,通常部署运行在Linux系统之上。因此不管使用何种方式配置Hive Metastore,必须要先保证服务器的基础环境正常, Hadoop集群健康可用。
(2)服务器基础环境
集群时间同步、防火墙关闭、主机Host映射、免密登录、 JDK安装
(3)Hadoop集群健康可用
启动Hive之前必须先启动Hadoop集群。特别要注意,需等待HDFS安全模式关闭之后再启动运行Hive。
Hive不是分布式安装运行的软件,其分布式的特性主要借由Hadoop完成。包括分布式存储、分布式计算。
Hadoop与Hive整合 :
(1)因为Hive需要把数据存储在HDFS上,并且通过MapReduce作为执行引擎处理数据;
(2)因此需要在Hadoop中添加相关配置属性,以满足Hive在Hadoop上运行。
(3)修改Hadoop中core-site.xml,并且Hadoop集群同步配置文件,重启生效。同步到hadoop其他集群,本次在安装hadoop已配置
<!-- 整合hive --><property><name>hadoop.proxyuser.root.hosts</name><value>*</value></property><property><name>hadoop.proxyuser.root.groups</name><value>*</value></property>
Step1: MySQL安装 MySQL本地 172.31.10.132 Docker
详细参考课程附件资料。
注意MySQL只需要在一台机器安装并且需要授权远程访问。
Step2:上传解压Hive安装包(node1安装即可) E:\文档\大数据\hadoop\04_数据仓库基础与Apache Hive入门\2、课程资料\hive 3.1.2
tar zxvf apache-hive-3.1.2-bin.tar.gz
mv apache-hive-3.1.2-bin apache-hive-3.1.2
# 解决Hive与Hadoop之间guava版本差异
cd /export/server/apache-hive-3.1.2
rm -rf lib/guava-19.0.jar
cp /export/server/hadoop-3.3.0/share/hadoop/common/lib/guava-27.0-jre.jar ./lib/
Step3:修改hive-env.sh
cd /export/server/apache-hive-3.1.2/conf
cp hive-env.sh.template hive-env.sh.template.bak
mv hive-env.sh.template hive-env.sh
vim hive-env.sh
export HADOOP_HOME=/export/server/hadoop-3.3.0
export HIVE_CONF_DIR=/export/server/apache-hive-3.1.2/conf
export HIVE_AUX_JARS_PATH=/export/server/apache-hive-3.1.2/lib
Step4:新增hive-site.xml ,vim hive-site.xml
<configuration>
<!-- 存储元数据mysql相关配置 -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://172.31.10.132:3306/hive3?createDatabaseIfNotExist=true&useSSL=false&useUnicode=true&characterEncoding=UTF-8</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property> <!--Mysql用户-->
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property> <!--Mysql密码-->
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<!-- H2S运行绑定host -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>node1</value>
</property>
<!-- 远程模式部署metastore metastore地址 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://node1:9083</value>
</property>
<!-- 关闭元数据存储授权 -->
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
</configuration>
Step5:添加驱动、初始化 :/export/server/apache-hive-3.1.2/lib
上传MySQL JDBC驱动到Hive安装包lib路径下 mysql-connector-java-5.1.47.jar
MySQL版本5.7.34 驱动安装5.1.47 E:\文档\大数据\hadoop\04_数据仓库基础与Apache Hive入门\2、课程资料
cd /export/server/apache-hive-3.1.2/
bin/schematool -initSchema -dbType mysql -verbos
hive安装成功标志:
Step6:在hdfs创建hive存储目录(如存在则不用操作)
hadoop fs -mkdir /tmp
hadoop fs -mkdir -p /user/hive/warehouse
hadoop fs -chmod g+w /tmp
hadoop fs -chmod g+w /user/hive/warehouse
两种方式启动MetaStore服务:
(1)前台启动:/export/server/apache-hive-3.1.2/bin/hive —service metastore
(2)前台启动开启debug日志
/export/server/apache-hive-3.1.2/bin/hive —service metastore —hiveconf hive.root.logger=DEBUG,console
#前台启动关闭方式 ctrl+c结束进程
(3)后台启动, 输出日志信息在/root目录下nohup.out
nohup /export/server/apache-hive-3.1.2/bin/hive —service metastore &
#后台挂起启动 结束进程
使用jps查看进程 使用kill -9 杀死进程
Apache Hive客户端使用
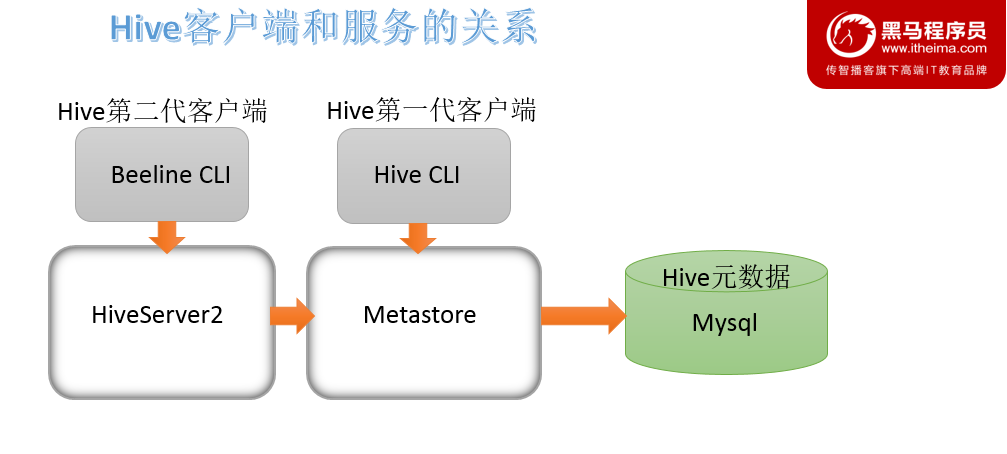
(1) Hive自带客户端 Hive发展至今,总共历经了两代客户端工具。
bin/hive、 bin/beeline
第一代客户端(deprecated不推荐使用): $HIVE_HOME/bin/hive, 是一个 shellUtil。主要功能:一是可用于以交互或批处理模式运行Hive查询;二是用于Hive相关服务的启动,比如metastore服务。
第二代客户端(recommended 推荐使用): $HIVE_HOME/bin/beeline,是一个JDBC客户端,是官方强烈推荐使用的Hive命令行工具,和第一代客户端相比,性能加强安全性提高。 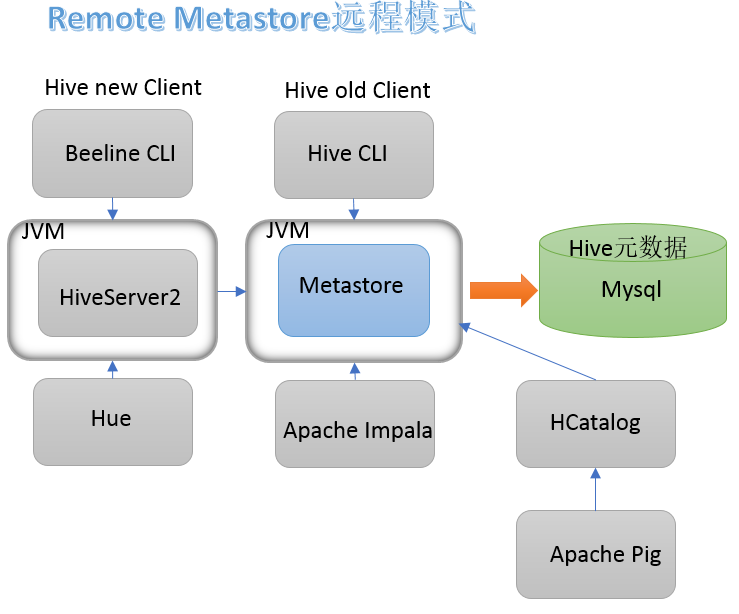
(2)HiveServer2服务介绍 :
远程模式下beeline通过 Thrift 连接到单独的HiveServer2服务上,这也是官方推荐在生产环境中使用的模式。
HiveServer2支持多客户端的并发和身份认证,旨在为开放API客户端如JDBC、 ODBC提供更好的支持。
HiveServer2通过Metastore服务读写元数据。所以在远程模式下, 启动HiveServer2之前必须先首先启动metastore服务。
特别注意:远程模式下, Beeline客户端只能通过HiveServer2服务访问Hive。 而bin/hive是通过Metastore服务访问的。具体关系如下:
(3)bin/beeline客户端使用
模拟客户端服务端使用,将node3机器作为客户端,node1作为服务端: 总共两台
将hive安装包上传到node3机器:scp -r apache-hive-3.1.2/ root@node3:/export/server/
前台启动metastore服务:前提启动服务端 /export/server/apache-hive-3.1.2/bin/hive —service metastore
/export/server/apache-hive-3.1.2/bin/hive
上面是node3启动客户端,但是使用metastore不推荐
binline启动:
在hive安装的服务器上node1, 首先启动metastore服务,然后启动hiveserver2服务。
nohup /export/server/apache-hive-3.1.2/bin/hive —service metastore &
nohup /export/server/apache-hive-3.1.2/bin/hive —service hiveserver2 >> hiveserver2.out &
在node3上使用beeline客户端进行连接访问。需要注意hiveserver2服务启动之后需要稍等一会才可以对外提供服务。
Beeline是JDBC的客户端,通过JDBC协议和Hiveserver2服务进行通信,协议的地址是:
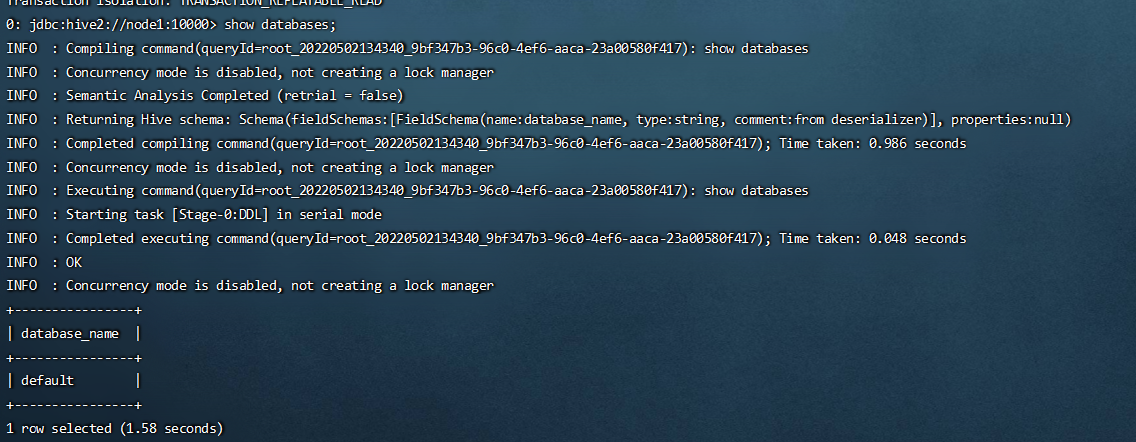
jdbc:hive2://node1:10000
连接方式:
/export/server/apache-hive-3.1.2/bin/beeline
beeline> ! connect jdbc:hive2://node1:10000
beeline> root
beeline> 直接回车
Hive可视化客户端启动:
使用DataGrip连接Hive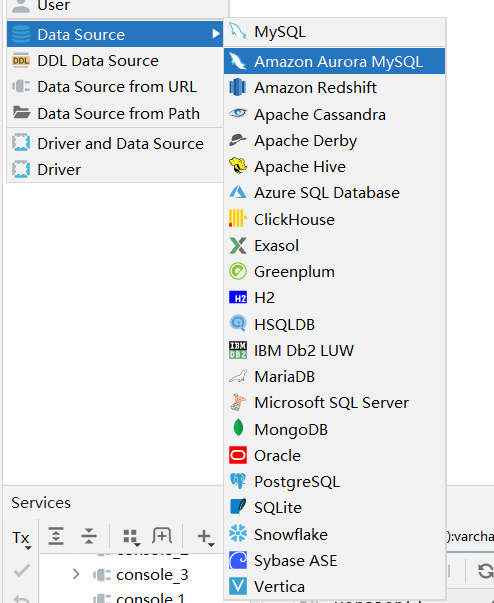
DataGrip使用教程 :
step1: windows创建工程文件夹 , E:\zbigdata\example-hive
step2: DataGrip中创建新Project
step3:关联本地工程文件夹 ,以后写的sql都会在这个目录下面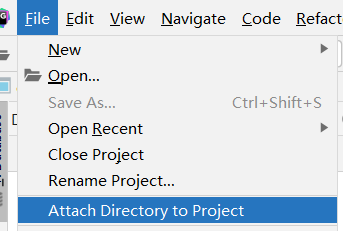
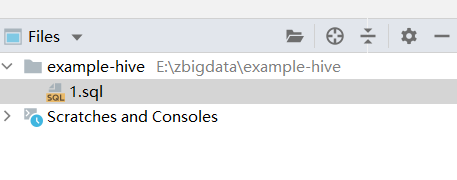
step4: DataGrip连接Hive ,使用自己的hive驱动: E:\zbigdata\hive-jdbc-3.1.2-standalone.jar
也可以使用 节点方式 Host可以将172.31.10.23改成node1,因为我们的win10的hosts列表做了转换 密码 root
若连接失败,则需要等一会,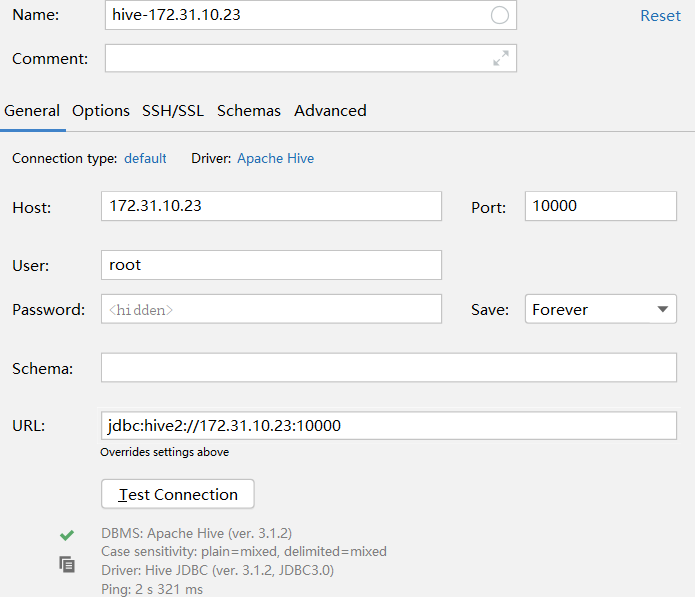

若有收获,就点个赞吧
0 人点赞
