adaboost自适应提升算法
AdaBoost 算法与随机森林算法一样都属于分类算法中的集成算法。
集成的含义就是集思广益,博取众长,当我们做决定的时候,我们先听取多个专家的意见,再做决定。集成算法通常有两种方式,分别是投票选举(bagging)和再学习(boosting)。
- 投票选举的场景类似把专家召集到一个会议桌前,当做一个决定的时候,让 K 个专家(K 个模型)分别进行分类,然后选择出现次数最多的那个类作为最终的分类结果。
- 再学习相当于把 K 个专家(K 个分类器)进行加权融合,形成一个新的超级专家(强分类器),让这个超级专家做判断。
AdaBoost 的工作原理
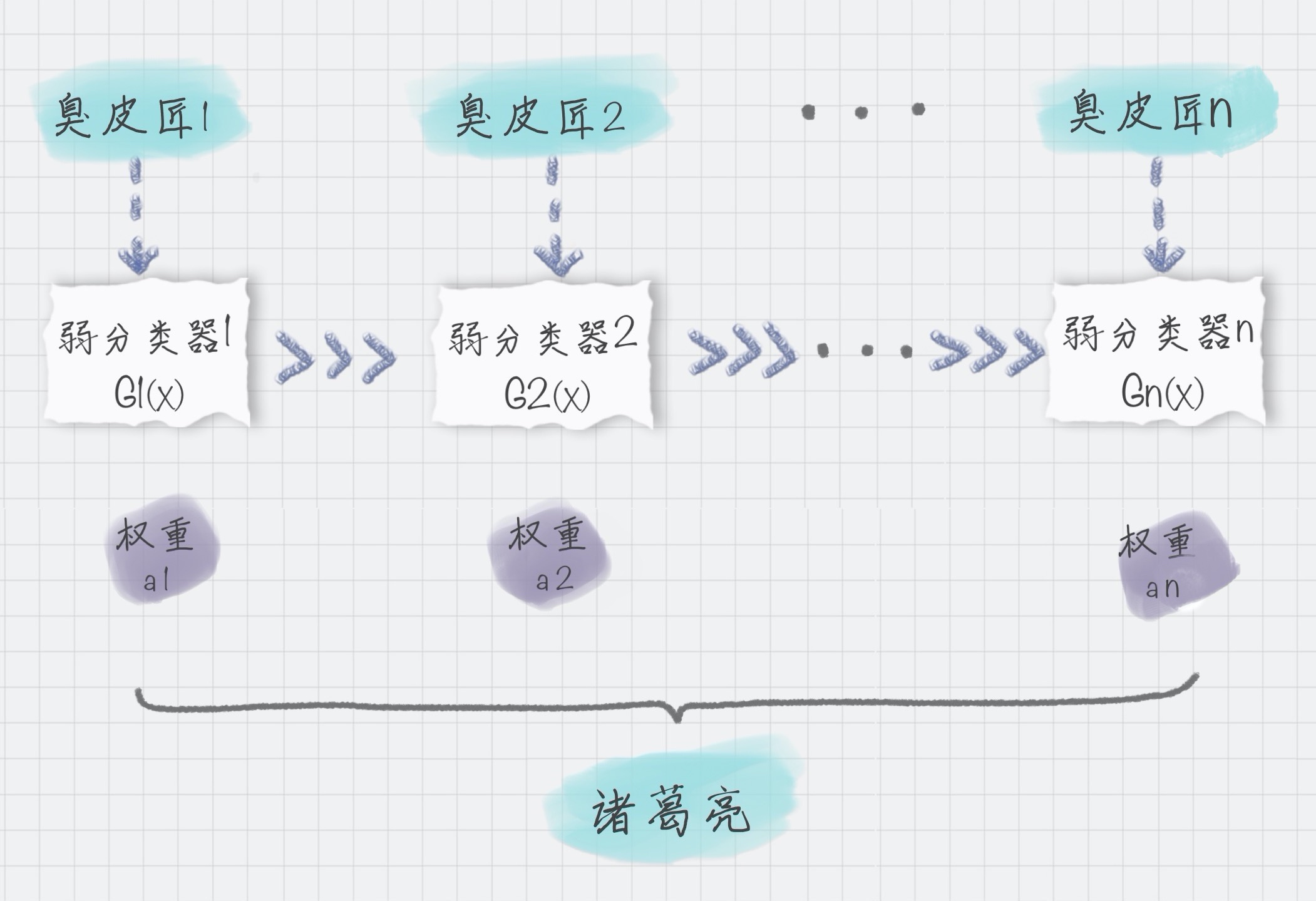
我可以用上面的图来表示最终得到的强分类器,你能看出它是通过一系列的弱分类器根据不同的权重组合而成的。
假设弱分类器为 Gi(x),它在强分类器中的权重 αi,那么就可以得出强分类器 f(x):
%3D%5Csum%7Bi%3D1%7D%5Ena_iG_i(x)%0A#card=math&code=f%28x%29%3D%5Csum%7Bi%3D1%7D%5Ena_iG_i%28x%29%0A)
权重计算
基于这个弱分类器对样本的分类错误率来决定它的权重,用公式表示就是:
代表第 i 个分类器的分类错误率
最优的弱分类器的选择
AdaBoost 算法是通过改变样本的数据分布来实现的。
- 判断每次训练的样本是否正确分类
- 对于正确分类的样本,降低它的权重
- 对于被错误分类的样本,增加它的权重
- 基于上一次得到的分类准确率,来确定这次训练样本中每个样本的权重。
- 将修改过权重的新数据集传递给下一层的分类器进行训练。
这样做的好处就是,通过每一轮训练样本的动态权重,可以让训练的焦点集中到难分类的样本上,最终得到的弱分类器的组合更容易得到更高的分类准确率。
- 用
代表第 k+1 轮训练中样本的权重集合
代表第 k+1 轮中第一个样本的权重
- 以此类推
代表第 k+1 轮中第 N 个样本的权重
%0A#card=math&code=D%7Bk%2B1%7D%3D%28W%7Bk%2B1%2C1%7D%2CW%7Bk%2B1%2C2%7D%2C%5Cdots%2CW%7Bk%2B1%2CN%7D%29%0A)
第 k+1 轮中的样本权重,是根据该样本在第 k 轮的权重以及第 k 个分类器的准确率而定,具体的公式为:
)%5Cquad%20i%3D1%2C2%2C%5Cdots%20%2CN%20%0A#card=math&code=w%7Bk%2B1%2Ci%7D%3D%5Cfrac%7Bw%7Bk%2Ci%7D%7D%7BZ_k%7Dexp%28-a_ky_iG_k%28x_i%29%29%5Cquad%20i%3D1%2C2%2C%5Cdots%20%2CN%20%0A)
sklearn实现
from sklearn.ensemble import AdaBoostClassifierAdaBoostClassifier(base_estimator=None, n_estimators=50, learning_rate=1.0, algorithm=’SAMME.R’, random_state=None)
- base_estimator:代表的是弱分类器。在 AdaBoost 的分类器和回归器中都有这个参数,在 AdaBoost 中默认使用的是决策树,一般我们不需要修改这个参数,当然你也可以指定具体的分类器。
- n_estimators:算法的最大迭代次数,也是分类器的个数,每一次迭代都会引入一个新的弱分类器来增加原有的分类器的组合能力。默认是 50。
- learning_rate:代表学习率,取值在 0-1 之间,默认是 1.0。如果学习率较小,就需要比较多的迭代次数才能收敛,也就是说学习率和迭代次数是有相关性的。当你调整 learning_rate 的时候,往往也需要调整 n_estimators 这个参数。
- algorithm:代表我们要采用哪种 boosting 算法,一共有两种选择:SAMME 和 SAMME.R。默认是 SAMME.R。这两者之间的区别在于对弱分类权重的计算方式不同。
- random_state:代表随机数种子的设置,默认是 None。随机种子是用来控制随机模式的,当随机种子取了一个值,也就确定了一种随机规则,其他人取这个值可以得到同样的结果。如果不设置随机种子,每次得到的随机数也就不同。
AdaBoost回归
AdaBoostRegressor(base_estimator=None, n_estimators=50, learning_rate=1.0, loss=‘linear’, random_state=None)
不同点:
- 回归算法里没有 algorithm 这个参数
- 多了一个 loss 参数
loss 代表损失函数的设置,一共有 3 种选择,分别为 linear、square 和 exponential,它们的含义分别是线性、平方和指数。默认是线性。
一般采用线性就可以得到不错的效果。

若有收获,就点个赞吧
0 人点赞
