import pandas as pdimport sklearn.tree as treeimport graphviz #画图from sklearn.feature_extraction import DictVectorizer# 将字符串替换为数字
导入数据
train_data=pd.read_csv('./train.csv')test_data=pd.read_csv('./test.csv')
数据加载
print(train_data.info())
<class 'pandas.core.frame.DataFrame'>RangeIndex: 891 entries, 0 to 890Data columns (total 12 columns):PassengerId 891 non-null int64Survived 891 non-null int64Pclass 891 non-null int64Name 891 non-null objectSex 891 non-null objectAge 714 non-null float64SibSp 891 non-null int64Parch 891 non-null int64Ticket 891 non-null objectFare 891 non-null float64Cabin 204 non-null objectEmbarked 889 non-null objectdtypes: float64(2), int64(5), object(5)memory usage: 83.7+ KBNone
train_data.describe()
| PassengerId | Survived | Pclass | Age | SibSp | Parch | Fare | |
|---|---|---|---|---|---|---|---|
| count | 891.000000 | 891.000000 | 891.000000 | 714.000000 | 891.000000 | 891.000000 | 891.000000 |
| mean | 446.000000 | 0.383838 | 2.308642 | 29.699118 | 0.523008 | 0.381594 | 32.204208 |
| std | 257.353842 | 0.486592 | 0.836071 | 14.526497 | 1.102743 | 0.806057 | 49.693429 |
| min | 1.000000 | 0.000000 | 1.000000 | 0.420000 | 0.000000 | 0.000000 | 0.000000 |
| 25% | 223.500000 | 0.000000 | 2.000000 | 20.125000 | 0.000000 | 0.000000 | 7.910400 |
| 50% | 446.000000 | 0.000000 | 3.000000 | 28.000000 | 0.000000 | 0.000000 | 14.454200 |
| 75% | 668.500000 | 1.000000 | 3.000000 | 38.000000 | 1.000000 | 0.000000 | 31.000000 |
| max | 891.000000 | 1.000000 | 3.000000 | 80.000000 | 8.000000 | 6.000000 | 512.329200 |
train_data.describe(include=['O'])
| Name | Sex | Ticket | Cabin | Embarked | |
|---|---|---|---|---|---|
| count | 891 | 891 | 891 | 204 | 889 |
| unique | 891 | 2 | 681 | 147 | 3 |
| top | Heininen, Miss. Wendla Maria | male | CA. 2343 | G6 | S |
| freq | 1 | 577 | 7 | 4 | 644 |
train_data.head()
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th… | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
train_data.tail()
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 886 | 887 | 0 | 2 | Montvila, Rev. Juozas | male | 27.0 | 0 | 0 | 211536 | 13.00 | NaN | S |
| 887 | 888 | 1 | 1 | Graham, Miss. Margaret Edith | female | 19.0 | 0 | 0 | 112053 | 30.00 | B42 | S |
| 888 | 889 | 0 | 3 | Johnston, Miss. Catherine Helen “Carrie” | female | NaN | 1 | 2 | W./C. 6607 | 23.45 | NaN | S |
| 889 | 890 | 1 | 1 | Behr, Mr. Karl Howell | male | 26.0 | 0 | 0 | 111369 | 30.00 | C148 | C |
| 890 | 891 | 0 | 3 | Dooley, Mr. Patrick | male | 32.0 | 0 | 0 | 370376 | 7.75 | NaN | Q |
print(test_data.info())
<class 'pandas.core.frame.DataFrame'>RangeIndex: 418 entries, 0 to 417Data columns (total 11 columns):PassengerId 418 non-null int64Pclass 418 non-null int64Name 418 non-null objectSex 418 non-null objectAge 332 non-null float64SibSp 418 non-null int64Parch 418 non-null int64Ticket 418 non-null objectFare 417 non-null float64Cabin 91 non-null objectEmbarked 418 non-null objectdtypes: float64(2), int64(4), object(5)memory usage: 36.0+ KBNone
我们发现 Age、Fare 和 Cabin 这三个字段的数据有所缺失
数据清洗
利用平均值填充连续型数据段
train_data['Age'].fillna(train_data['Age'].mean(),inplace=True)test_data['Age'].fillna(test_data['Age'].mean(),inplace=True)
train_data['Fare'].fillna(train_data['Fare'].mean(),inplace=True)test_data['Fare'].fillna(test_data['Fare'].mean(),inplace=True)
字符型数据以众数填充
train_data['Embarked'].value_counts()
S 644C 168Q 77Name: Embarked, dtype: int64
train_data['Embarked'].fillna('S',inplace=True)
特征值选取
cabin存在太多缺失数据无法补全,予以舍去
features=['Pclass','Sex','Age','SibSp','Parch','Fare','Embarked']train_features=train_data[features]test_features=test_data[features]train_labels=train_data['Survived']
# 字符串替换为数字dvec=DictVectorizer(sparse=False)train_features=dvec.fit_transform(train_features.to_dict(orient='record'))
print(dvec.feature_names_)
['Age', 'Embarked=C', 'Embarked=Q', 'Embarked=S', 'Fare', 'Parch', 'Pclass', 'Sex=female', 'Sex=male', 'SibSp']
train_features=pd.DataFrame(train_features,columns=[dvec.feature_names_])train_features.head()
| Age | Embarked=C | Embarked=Q | Embarked=S | Fare | Parch | Pclass | Sex=female | Sex=male | SibSp | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 22.0 | 0.0 | 0.0 | 1.0 | 7.2500 | 0.0 | 3.0 | 0.0 | 1.0 | 1.0 |
| 1 | 38.0 | 1.0 | 0.0 | 0.0 | 71.2833 | 0.0 | 1.0 | 1.0 | 0.0 | 1.0 |
| 2 | 26.0 | 0.0 | 0.0 | 1.0 | 7.9250 | 0.0 | 3.0 | 1.0 | 0.0 | 0.0 |
| 3 | 35.0 | 0.0 | 0.0 | 1.0 | 53.1000 | 0.0 | 1.0 | 1.0 | 0.0 | 1.0 |
| 4 | 35.0 | 0.0 | 0.0 | 1.0 | 8.0500 | 0.0 | 3.0 | 0.0 | 1.0 | 0.0 |
构建ID3决策树
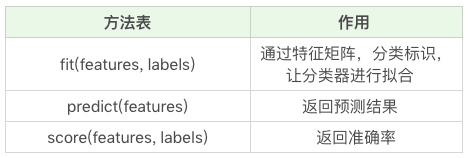
clf=tree.DecisionTreeClassifier(criterion='entropy')clf.fit(train_features,train_labels)
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='entropy',max_depth=None, max_features=None, max_leaf_nodes=None,min_impurity_decrease=0.0, min_impurity_split=None,min_samples_leaf=1, min_samples_split=2,min_weight_fraction_leaf=0.0, presort='deprecated',random_state=None, splitter='best')
test_features=dvec.fit_transform(test_features.to_dict(orient='record'))clf.predict(test_features)
array([0, 0, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 1, 0, 1, 1, 0, 1, 1,1, 0, 1, 0, 1, 1, 1, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 1,1, 0, 0, 0, 1, 1, 0, 0, 1, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 1, 1, 1,0, 0, 0, 1, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 1, 0,0, 1, 1, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 0, 0, 0, 1, 0, 0, 0, 1, 0,0, 0, 1, 0, 1, 0, 0, 1, 1, 1, 1, 0, 1, 0, 0, 1, 0, 1, 0, 0, 1, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1,0, 0, 1, 1, 0, 0, 0, 1, 1, 0, 0, 1, 1, 0, 1, 0, 0, 0, 0, 0, 0, 1,1, 1, 1, 1, 0, 0, 1, 0, 1, 0, 1, 0, 0, 0, 0, 0, 1, 1, 1, 0, 1, 0,0, 0, 1, 1, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0,1, 0, 1, 1, 1, 0, 0, 0, 0, 0, 0, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 1,0, 0, 0, 0, 1, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 1,0, 0, 0, 0, 0, 0, 1, 0, 1, 1, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 1,0, 0, 0, 1, 0, 0, 1, 1, 1, 0, 0, 0, 0, 0, 0, 1, 1, 0, 1, 0, 0, 0,1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 1, 1, 0,0, 0, 0, 0, 1, 0, 0, 1, 0, 1, 1, 1, 1, 0, 0, 1, 1, 1, 0, 1, 0, 0,1, 1, 0, 0, 0, 0, 0, 0, 1, 1, 0, 1, 0, 0, 1, 0, 1, 1, 0, 0, 0, 1,0, 1, 0, 0, 1, 0, 1, 0, 0, 1, 0, 0, 0, 1, 0, 1, 0, 0, 1, 0, 0, 0])
clf.score(train_features,train_labels)
0.9820426487093153
import pydotplus
from sklearn import tree
import collections
from PIL import Image
dot_data = tree.export_graphviz(clf, feature_names=['年龄', '登陆港C', '登陆港Q', '登陆港S', '船票价格', '父母子女数', '船票等级', '女性', '男性', '兄妹,配偶数'], out_file=None,filled=True, rounded=True)
# graph = pydotplus.graph_from_dot_data(dot_data)
# colors = ( 'lightblue','orange')
# edges = collections.defaultdict(list)
# for edge in graph.get_edge_list():
# edges[edge.get_source()].append(int(edge.get_destination()))
# for edge in edges:
# edges[edge].sort()
# for i in range(2):
# dest = graph.get_node(str(edges[edge][i]))[0]
# dest.set_fillcolor(colors[i])
# graph.write_png('tree.png')
# from IPython.display import Image
# Image("tree.png")
graphviz.Source(dot_data)

数据集

若有收获,就点个赞吧
0 人点赞
