KNeighborsClassifier(n_neighbors=5, weights=‘uniform’, algorithm=‘auto’, leaf_size=30)
1.n_neighbors:即 KNN 中的 K 值,代表的是邻居的数量。K 值如果比较小,会造成过拟合。如果 K 值比较大,无法将未知物体分类出来。一般我们使用默认值 5。
2.weights:是用来确定邻居的权重,有三种方式:weights=uniform,代表所有邻居的权重相同;weights=distance,代表权重是距离的倒数,即与距离成反比;自定义函数,你可以自定义不同距离所对应的权重。大部分情况下不需要自己定义函数。
3.algorithm:用来规定计算邻居的方法,它有四种方式:algorithm=auto,根据数据的情况自动选择适合的算法,默认情况选择 auto;
- algorithm=kd_tree,也叫作 KD 树,是多维空间的数据结构,方便对关键数据进行检索,不过 KD 树适用于维度少的情况,一般维数不超过 20,如果维数大于 20 之后,效率反而会下降;
- algorithm=ball_tree,也叫作球树,它和 KD 树一样都是多维空间的数据结果,不同于 KD 树,球树更适用于维度大的情况;
- algorithm=brute,也叫作暴力搜索,它和 KD 树不同的地方是在于采用的是线性扫描,而不是通过构造树结构进行快速检索。当训练集大的时候,效率很低。
4.leaf_size:代表构造 KD 树或球树时的叶子数,默认是 30,调整 leaf_size 会影响到树的构造和搜索速度。
import matplotlib.pyplot as pltfrom sklearn.model_selection import train_test_splitfrom sklearn import preprocessingfrom sklearn.metrics import accuracy_scorefrom sklearn.datasets import load_digitsfrom sklearn.neighbors import KNeighborsClassifier
digits=load_digits()data=digits.datadata.shape
(1797, 64)
print(digits.images[0])
print('--'*30)
print(digits.target[0])
[[ 0. 0. 5. 13. 9. 1. 0. 0.]
[ 0. 0. 13. 15. 10. 15. 5. 0.]
[ 0. 3. 15. 2. 0. 11. 8. 0.]
[ 0. 4. 12. 0. 0. 8. 8. 0.]
[ 0. 5. 8. 0. 0. 9. 8. 0.]
[ 0. 4. 11. 0. 1. 12. 7. 0.]
[ 0. 2. 14. 5. 10. 12. 0. 0.]
[ 0. 0. 6. 13. 10. 0. 0. 0.]]
------------------------------------------------------------
0
plt.gray()
plt.imshow(digits.images[0])
plt.show()
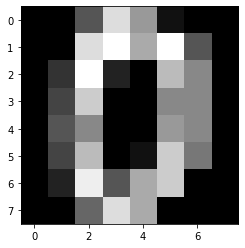
train_x,test_x,train_y,test_y=train_test_split(data,digits.target,test_size=0.25,random_state=33)
ss=preprocessing.StandardScaler()
train_x=ss.fit_transform(train_x)
test_x=ss.fit_transform(test_x)
knn=KNeighborsClassifier()
knn.fit(train_x,train_y)
prediction=knn.predict(test_x)
score=accuracy_score(prediction,test_y)
print(score)
0.9755555555555555

若有收获,就点个赞吧
0 人点赞
