构建逻辑回归分类器
逻辑回归,也叫作 logistic 回归。虽然名字中带有“回归”,但它实际上是分类方法,主要解决的是二分类问题,当然它也可以解决多分类问题,只是二分类更常见一些。
在逻辑回归中使用了 Logistic 函数,也称为 Sigmoid 函数。Sigmoid 函数是在深度学习中经常用到的函数之一,函数公式为:
%3D%5Cfrac%7B1%7D%7B1-e%5E%7B-z%7D%7D%0A#card=math&code=g%28z%29%3D%5Cfrac%7B1%7D%7B1-e%5E%7B-z%7D%7D%0A)
函数的图形如下所示,类似 S 状: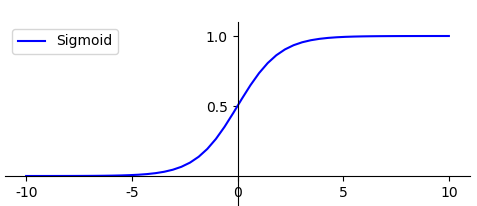
- g(z) 的结果在 0-1 之间,当 z 越大的时候,g(z) 越大,当 z 趋近于无穷大的时候,g(z) 趋近于 1。同样当 z 趋近于无穷小的时候,g(z) 趋近于 0。同时,函数值以 0.5 为中心。
sklearn实现
LogisticRegression()
- penalty:惩罚项,取值为 l1 或 l2,默认为 l2。当模型参数满足高斯分布的时候,使用 l2,当模型参数满足拉普拉斯分布的时候,使用 l1;
- solver:代表的是逻辑回归损失函数的优化方法。有 5 个参数可选,分别为 liblinear、lbfgs、newton-cg、sag 和 saga。默认为 liblinear,适用于数据量小的数据集,当数据量大的时候可以选用 sag 或 saga 方法。
- max_iter:算法收敛的最大迭代次数,默认为 10。
- n_jobs:拟合和预测的时候 CPU 的核数,默认是 1,也可以是整数,如果是 -1 则代表 CPU 的核数。
模型评估指标
我们之前对模型做评估时,通常采用的是准确率 (accuracy),它指的是分类器正确分类的样本数与总体样本数之间的比例。这个指标对大部分的分类情况是有效的,不过当分类结果严重不平衡的时候,准确率很难反应模型的好坏。
数据预测的四种情况
TP:预测为正,判断正确;
FP:预测为正,判断错误;
TN:预测为负,判断正确;
FN:预测为负,判断错误。
- 样本总数 =TP+FP+TN+FN,
- 预测正确的样本数为 TP+TN
- 准确率 Accuracy = (TP+TN)/(TP+TN+FN+FP)
指标
精确率 P = TP/ (TP+FP)
召回率 R = TP/ (TP+FN)
查全率。代表的是被正确识别出来的个数与负总数的比例。
F1指标
F1 作为精确率 P 和召回率 R 的调和平均,数值越大代表模型的结果越好。

若有收获,就点个赞吧
0 人点赞
