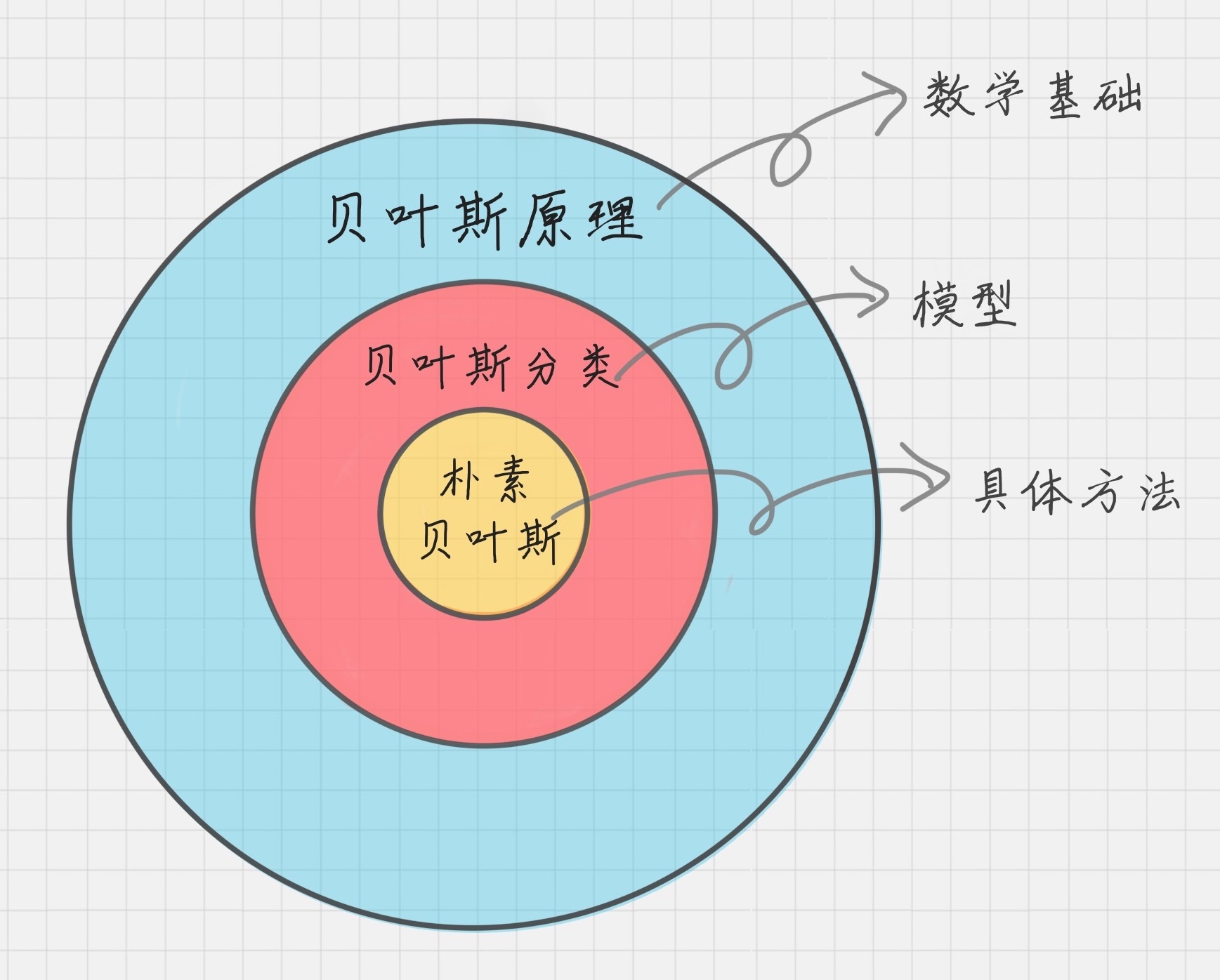
贝叶斯原理
联合概率
由多个随机变量决定的概率叫联合概率,它的概率分布就是联合概率分布。随机变量 x 和 y 的联合概率使用 P(x, y) 表示。
边缘概率
- 对于离散型随机变量,我们可以通过通过联合概率 P(x, y) 在 y 上求和,就可以得到 P(x)。
- 对于连续型随机变量,我们可以通过联合概率 P(x, y) 在 y 上的积分,推导出概率 P(x)。这个时候,我们称 P(x) 为边缘概率。
条件概率
条件概率也是由多个随机变量决定,但是和联合概率不同的是,它计算了给定某个(或多个)随机变量的情况下,另一个(或多个)随机变量出现的概率,其概率分布叫做条件概率分布。
给定随机变量 x,随机变量 y 的条件概率使用 P(y | x) 表示。
%3DP(x%7Cy)*P(y)%0A#card=math&code=%E8%81%94%E5%90%88%E6%A6%82%E7%8E%87%3D%E6%9D%A1%E4%BB%B6%E6%A6%82%E7%8E%87%2A%E6%A6%82%E7%8E%87%5C%5CP%28x%2Cy%29%3DP%28x%7Cy%29%2AP%28y%29%0A)
同理可得:
%3DP(y%7Cx)*P(x)%0A#card=math&code=P%28y%2Cx%29%3DP%28y%7Cx%29%2AP%28x%29%0A)
贝叶斯定理
%3DP(x%7Cy)P(y)%5C%5C%20P(y%2Cx)%3DP(y%7Cx)P(x)%0A#card=math&code=P%28x%2Cy%29%3DP%28x%7Cy%29%2AP%28y%29%5C%5C%20P%28y%2Cx%29%3DP%28y%7Cx%29%2AP%28x%29%0A)
得:
P(y)%3DP(x%2Cy)%3DP(y%2Cx)%3DP(y%7Cx)P(x)%20%5C%5CP(x%7Cy)%3D%5Cfrac%7BP(y%7Cx)*P(x)%7D%7BP(y)%7D%20%0A#card=math&code=P%28x%7Cy%29%2AP%28y%29%3DP%28x%2Cy%29%3DP%28y%2Cx%29%3DP%28y%7Cx%29%2AP%28x%29%20%5C%5CP%28x%7Cy%29%3D%5Cfrac%7BP%28y%7Cx%29%2AP%28x%29%7D%7BP%28y%29%7D%20%0A)
这就是非常经典的贝叶斯法则。
- 把 P(x) 称为先验概率(Prior Probability)。之所以称为“先验”,是因为它是从数据资料统计得到的,不需要经过贝叶斯定理的推算。
#card=math&code=P%28y%7Cx%29)是给定x之后y出现的条件概率。统计学也把
#card=math&code=L%28x%7Cy%29)
在数学里,似然函数和概率是有区别的
- 概率是指已经知道模型的参数来预测结果
- 似然函数是根据观测到的结果数据,来预估模型的参数
当y值给定的时候,两者在数值上是相等的,在应用中可不用细究。
- P(x|y)为后验概率(Posterior Probability)
P(y)可以通过联合概率
#card=math&code=P%28x%2Cy%29)计算边缘概率得来,而联合概率
%3D%5Csum_yP(x%2Cy)%20%5C%5C%20%E8%BF%9E%E7%BB%AD%E5%9E%8B%E8%BE%B9%E7%BC%98%E6%A6%82%E7%8E%87%EF%BC%9AP(x)%3D%5Cint%20P(x%2Cy)dy%0A#card=math&code=%E7%A6%BB%E6%95%A3%E5%9E%8B%E8%BE%B9%E7%BC%98%E6%A6%82%E7%8E%87%EF%BC%9AP%28x%29%3D%5Csum_yP%28x%2Cy%29%20%5C%5C%20%E8%BF%9E%E7%BB%AD%E5%9E%8B%E8%BE%B9%E7%BC%98%E6%A6%82%E7%8E%87%EF%BC%9AP%28x%29%3D%5Cint%20P%28x%2Cy%29dy%0A)
朴素贝叶斯
它是一种简单但极为强大的预测建模算法。“朴素”因为模型假设每个输入变量是独立的。
朴素贝叶斯的核心思想
%3D%5Cfrac%7BP(f%7Cc)*P(c)%7D%7BP(f)%7D%0A#card=math&code=P%28c%7Cf%29%3D%5Cfrac%7BP%28f%7Cc%29%2AP%28c%29%7D%7BP%28f%29%7D%0A)
- c 表示一个分类(class)
- f 表示属性对应的数据字段(field)
- 等号左边的
#card=math&code=P%28c%7Cf%29)就是待分类样本中,出现属性值 f 时,样本属于类别 c 的概率
- 等号右边的
#card=math&code=P%28f%7Cc%29)是根据训练数据统计,得到分类 c 中出现属性 f 的概率
#card=math&code=P%28c%29)是分类c在训练数据中出现的概率
#card=math&code=P%28f%29)是属性f在训练样本中出现的概率
这里的贝叶斯公式如果含有多个属性
- 一个简单假设建立的一种贝叶斯方法
- 假定数据对象的不同属性对其归类影响时是相互独立的
- 若数据对象 o 中同时出现属性
与
,则对象o属于类别 c 的概率为
%3DP(c%7Cf_i%2Cf_j)%3DP(c%7Cf_i)P(c%7Cf_j)%5C%5C%3D%5Cfrac%7BP(f_i%7Cc)P(c)%7D%7BP(f_i)%7D%5Cfrac%7BP(f_j%7Cc)P(c)%7D%7BP(f_j)%7D%0A#card=math&code=P%28c%7Co%29%3DP%28c%7Cf_i%2Cf_j%29%3DP%28c%7Cf_i%29%2AP%28c%7Cf_j%29%5C%5C%3D%5Cfrac%7BP%28f_i%7Cc%29%2AP%28c%29%7D%7BP%28f_i%29%7D%2A%5Cfrac%7BP%28f_j%7Cc%29%2AP%28c%29%7D%7BP%28f_j%29%7D%0A)
如果数据是连续型分布,可以假设服从正态分布,求出
,从而计算概率
sklearn实现
- 高斯朴素贝叶斯:特征变量是连续变量,符合高斯分布,比如说人的身高,物体的长度。
- 多项式朴素贝叶斯:特征变量是离散变量,符合多项分布,在文档分类中特征变量体现在一个单词出现的次数,或者是单词的 TF-IDF 值等。
- 伯努利朴素贝叶斯:特征变量是布尔变量,符合 0/1 分布,在文档分类中特征是单词是否出现。
from sklearn.naive_bayes import GaussianNBclf = GaussianNB()clf.fit(X_train, y_train)clf.score(X_test, y_test)# from sklearn.naive_bayes import BernoulliNB, MultinomialNB # 伯努利模型和多项式模型

若有收获,就点个赞吧
0 人点赞
