下载下来文件后打开
根据内容搜索到是ICD-10的文本,
每个条目还有编号,猜测应该是每条对应一个字母或数字或特殊字符,最有可能的应该就是base系列的编码。
然后把每条去和题目对比,结果只有30多条对上,和base中的哪一种都对不上。
遂去找wp,看了wp恍然大悟,之所以只匹配到30多条,是因为即使是base64,也不一定所有字符全用上了。
所以正确思路是直接去ICD-10下面弄下来65条(a-z,A-z,0-9,+,-,=),然后对照Base64索引表替换即可。
import csvimport reimport base64with open('in.txt', 'r', newline='',encoding="utf-8") as csv_file:lines=csv.reader(csv_file)with open('out.txt','r') as out:text=out.read()for line in lines:text=re.sub(line[1],line[0],text)with open('data','wb') as file:file.write(bytes.fromhex(base64.b64decode(text).decode('utf-8')))
最后得到一张图片。
stegsolve可以看到三个通道的0,1位都有数据,但是提不出来。
wp中说要用imagemask来提取:https://github.com/kingthy/imagemask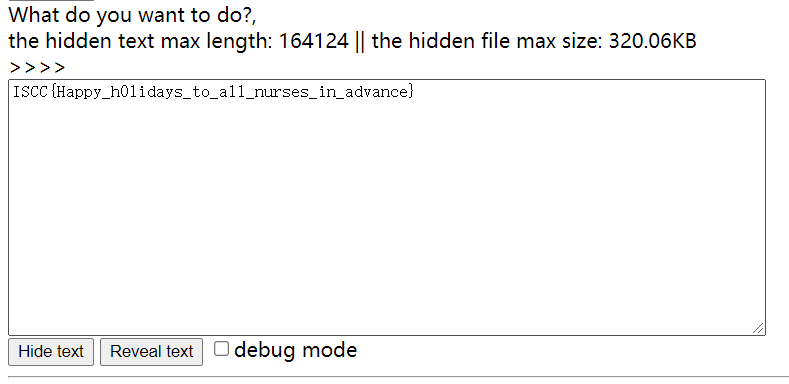

若有收获,就点个赞吧
0 人点赞
