阿里巴巴Arthas
简介
java诊断工具 支持JDK6+,命令交互式
官方地址:https://arthas.aliyun.com/doc/
场景
- 全视角查看系统运行状态
- 查看cpu运行状态
- 查看线程状态,死锁,堵塞
- 程序耗时监测
- jar加载,报错Exception
- 反编译源码
- 线上debug?
- 监测jvm实时运行状态
Arthas的使用
下载
#github 下载wget https://alibaba.github.io//arthas/arthas-boot.jar# 或国内镜像wget https://arthas.gitee.io/arthas-boot.jar
使用
1:启动java -jar arthas-boot.jar #启动
启动会会监测到当前服务器上的java进程
2:按对应的编号进入对应的进程监测
3:输入dashboard可以查看整个进程的运行情况,线程,内存,gc,运行环境信息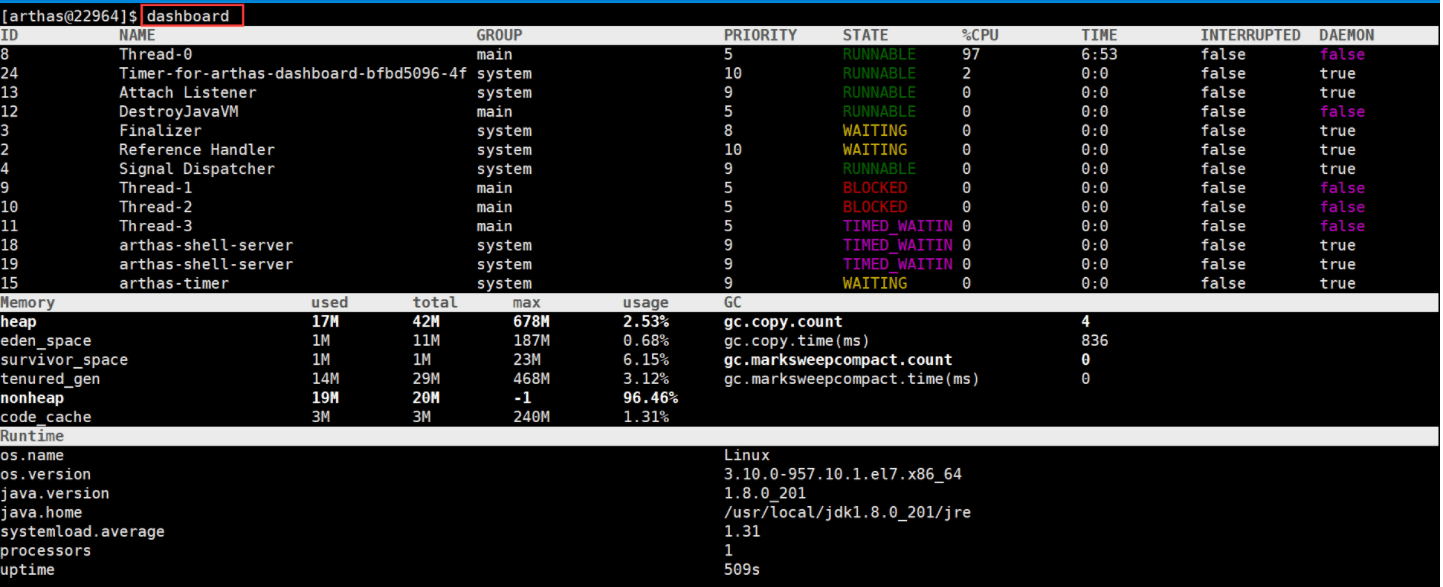
4:输入thread id 查看线程详情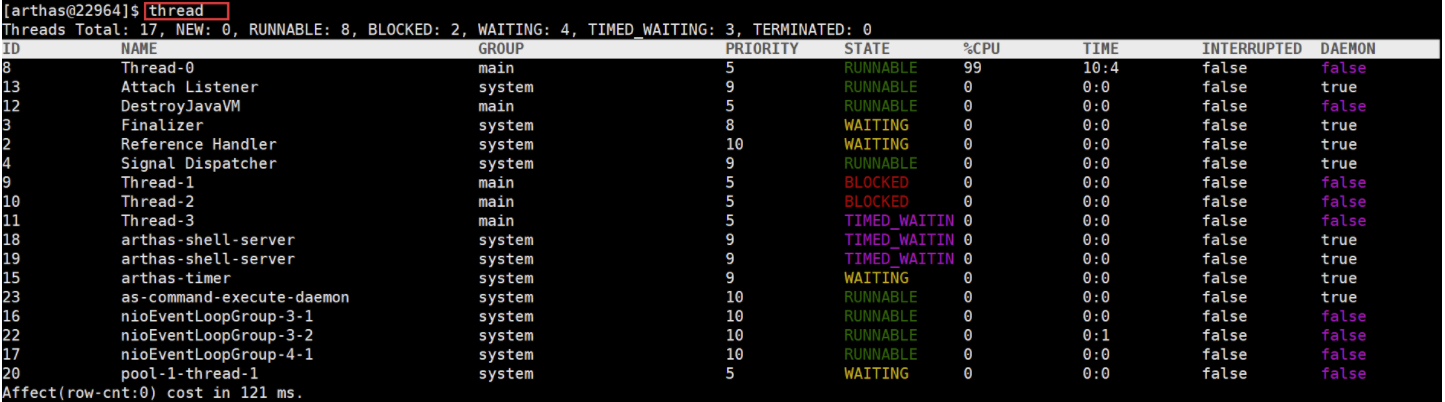
5:thread -b 查看线程死锁
6:jad <类全限定名> 反编译,查看源码
7:ognl 查看对象的值,或者执行命令
ognl ‘@com.xxx.jvm.Arthas@hashMap.put(“key”,”value”)’
看文档:https://alibaba.github.io/arthas/commands.html#arthas
GC日志详解
1:打印日志的jvm 配置:这是是补在java -jar 后面
-Xloggc:./gc-%t.log -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCTimeStamps -XX:+PrintGCCause-XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=100M
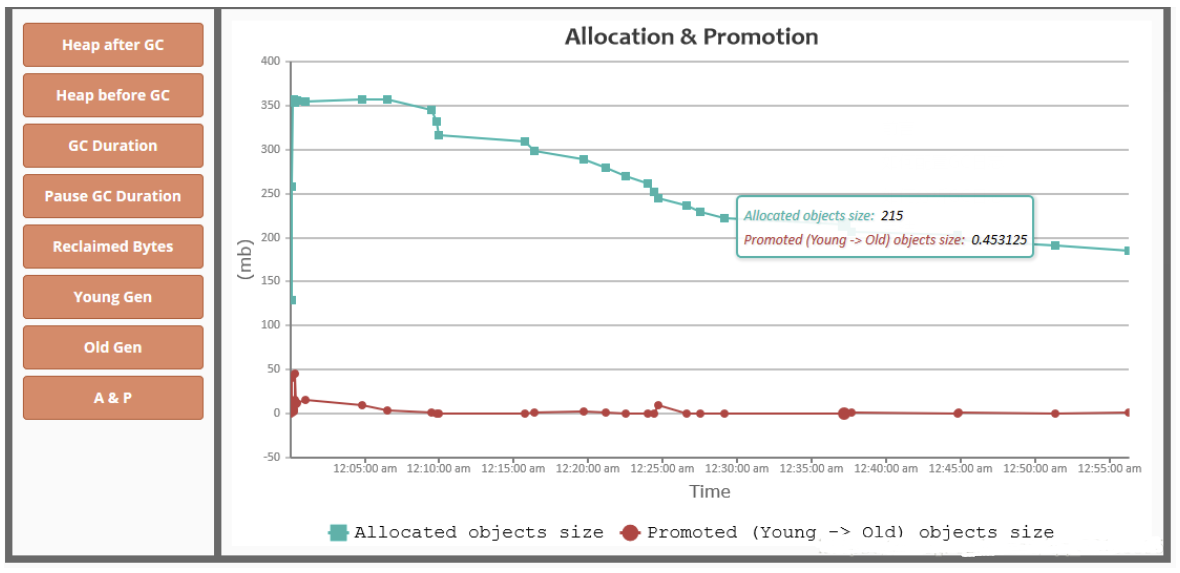
DOMO: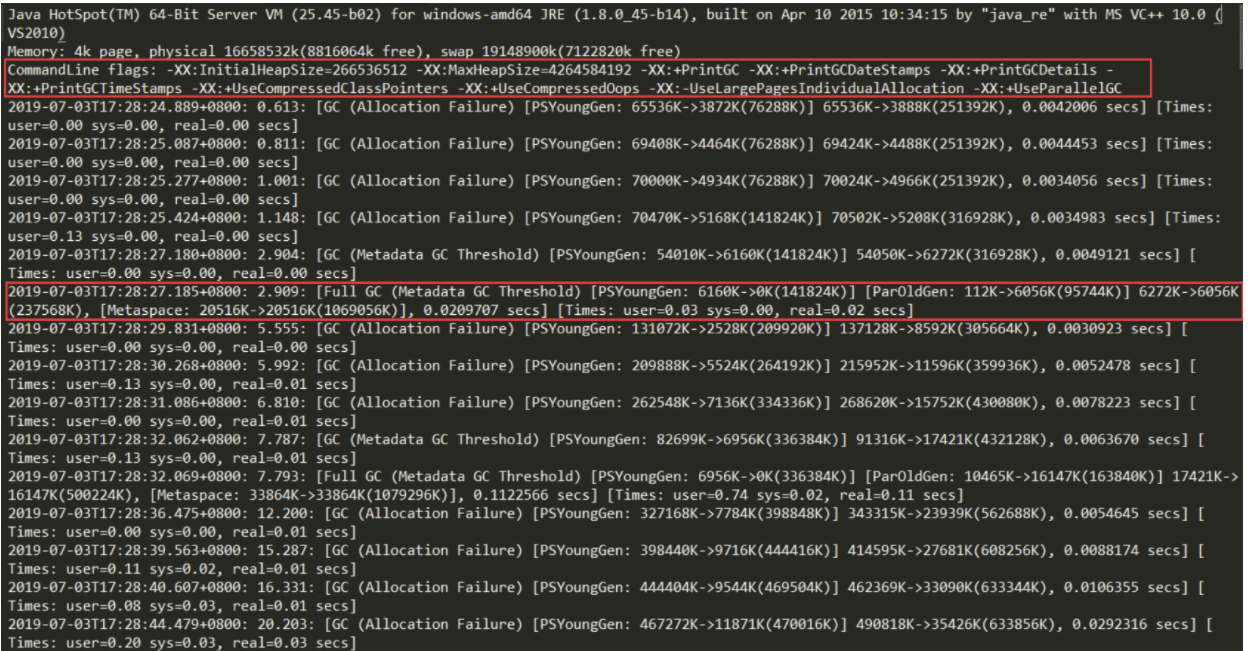
上图实例的gc日志
commandline flags: 对应的事配置参数
红框下面的就是gc日志
解释说明:
1::2.909:启动到gc发生经过的时间
2:Full GC (MetaDat GC Threshold) —> 一次full gc
3、 6160K->0K(141824K),这三个数字分别对应GC之前占用年轻代的大小,GC之后年轻代占用,以及整个年轻代的大小。
4、112K->6056K(95744K),这三个数字分别对应GC之前占用老年代的大小,GC之后老年代占用,以及整个老年代的大小。
5、6272K->6056K(237568K),这三个数字分别对应GC之前占用堆内存的大小,GC之后堆内存占用,以及整个堆内存的大小。
6、20516K->20516K(1069056K),这三个数字分别对应GC之前占用元空间内存的大小,GC之后元空间内存占用,以及整个元空间内存的大小。
7、0.0209707是该时间点GC总耗费时间。
CMS 收集器对应的日志参数
-Xloggc:d:/gc-cms-%t.log -Xms50M -Xmx50M -XX:MetaspaceSize=256M -XX:MaxMetaspaceSize=256M -XX:+PrintGCDetails -XX:+PrintGCDateStamps-XX:+PrintGCTimeStamps -XX:+PrintGCCause -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=100M-XX:+UseParNewGC -XX:+UseConcMarkSweepGC
G1收集器对应的参数
-Xloggc:d:/gc-g1-%t.log -Xms50M -Xmx50M -XX:MetaspaceSize=256M -XX:MaxMetaspaceSize=256M -XX:+PrintGCDetails -XX:+PrintGCDateStamps-XX:+PrintGCTimeStamps -XX:+PrintGCCause -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=100M -XX:+UseG1GC
日志分析工具gceasy(https://gceasy.io)
将gc 日志导入对应的界面,gceasy 会给出对应的模型,日志分析以及优化建议,这个是付费的
相关截图: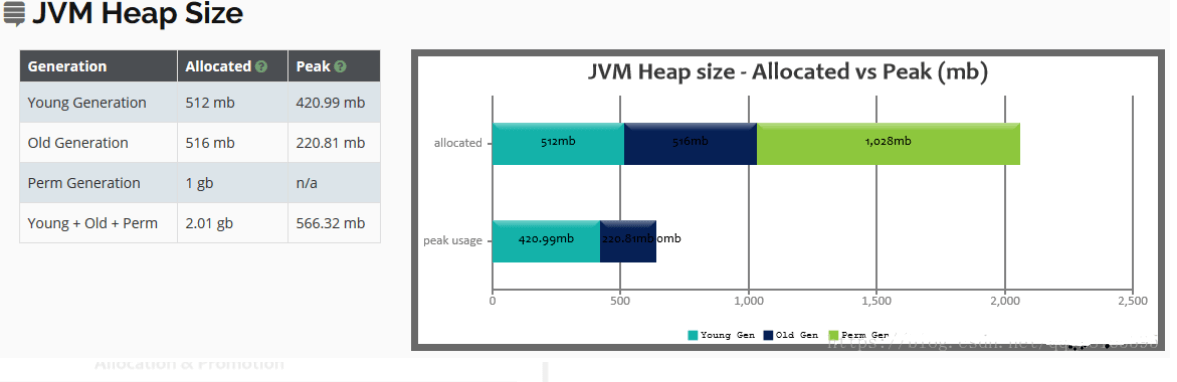

JVM参数汇总查看命令
java -XX:+PrintFlagsInitial 表示打印出所有参数选项的默认值
java -XX:+PrintFlagsFinal 表示打印出所有参数选项在运行程序时生效的值
Class常量池与运行时常量池
常量池的理解:class文件的资源仓库,
用于存放编译期生成的各种 字面量(Literal)和 符号引用(Symbolic References)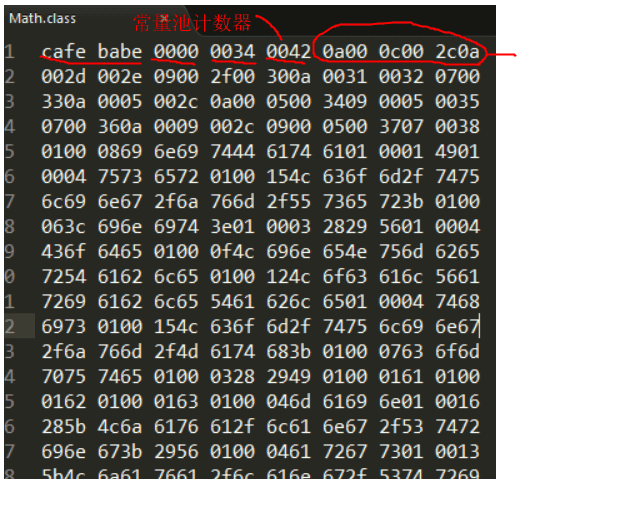
javap -v Math.class # 反编译字节码文件成为下图所示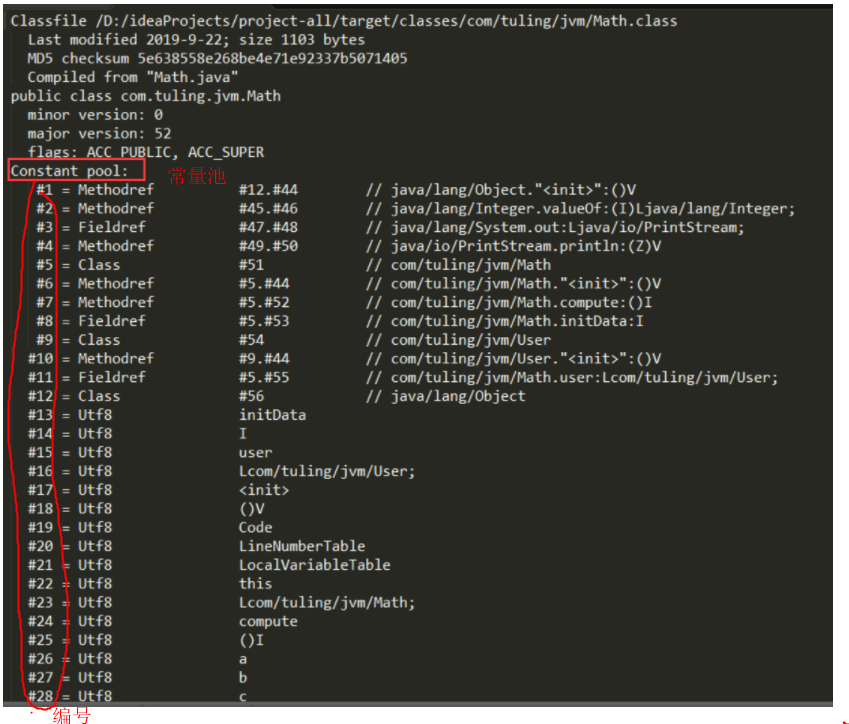
字面量
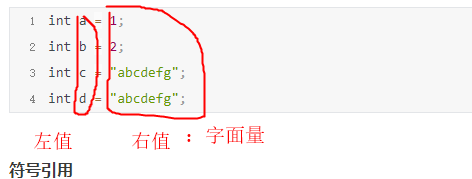
符号引用
包含以下三类常量
- 类和接口的全限定名
- 字段的名称和描述符
- 方法的名称和描述符
a,b,符号引用,
Lcom/tuling/jvm/Math ::全限定名
()是一种UTF8的描述符,也是符号引用
静态信息 , 加载到内存后,这些符号会对应内存的地址新,就会被装载如内存,变成运行时常量池
加载后符号会变成代码的直接引用——-动态链接
例如,compute()这个符号引用在运行时就会被转变为compute()方法具体代码在内存中的地址,主要通过对象头里的类型指针去转换直接引用
字符串常量池
设计思想:
1:字符串的使用频繁,影响程序性能
2:jvm提供性能,减少内存开销,会对字符串常量优化
1:字符串常量池,相当于缓存
2:创建字符串常量时,先去字符串常量池查询
3:存在返回引用的示例,不存在,就实例化两个,一个在堆,一个放常量池
三种字符串操作比较
1:直接复制String s = "zhangsan" # s指向常量池的引用,此时只会创建一个对象
创建时,jvm 回去常量池 使用equals 判断是否存在
如有,返回
如没,在常量池中创建一个对象,并返回
2:new String()String s1 = new String("zhangsan") #会创建两个,一个在堆new的那个,一个在常量池""这个 s1 指堆中的对象引用
3:intern方法
String s1 = new String("zhuge");String s2 = s1.intern();System.out.println(s1 == s2); //false
intern是一个native方法,先从池里判断是否有,有返回,无:返回堆里面的那个s1
字符串常量池的位置
JDK1.6之前:在永久代
JDK1.7:堆里
JDK1.8:运行时常量池在元空间,字符串常量池仍在堆里
证明的demo
/*** jdk6:-Xms6M -Xmx6M -XX:PermSize=6M -XX:MaxPermSize=6M* jdk8:-Xms6M -Xmx6M -XX:MetaspaceSize=6M -XX:MaxMetaspaceSize=6M*/public class RuntimeConstantPoolOOM{public static void main(String[] args) {ArrayList<String> list = new ArrayList<String>();for (int i = 0; i < 10000000; i++) {String str = String.valueOf(i).intern();list.add(str);}}}运行结果:jdk7及以上:Exception in thread "main" java.lang.OutOfMemoryError: Java heap spacejdk6:Exception in thread "main" java.lang.OutOfMemoryError: PermGen space
字符串常量池设计原理
类型HashTable
看例子:
String s1 = new String("he") + new String("llo");String s2 = s1.intern();System.out.println(s1 == s2);// 在 JDK 1.6 下输出是 false,创建了 6 个对象// 在 JDK 1.7 及以上的版本输出是 true,创建了 5 个对象 都是指向堆里面的那个// 当然我们这里没有考虑GC,但这些对象确实存在或存在过
1.6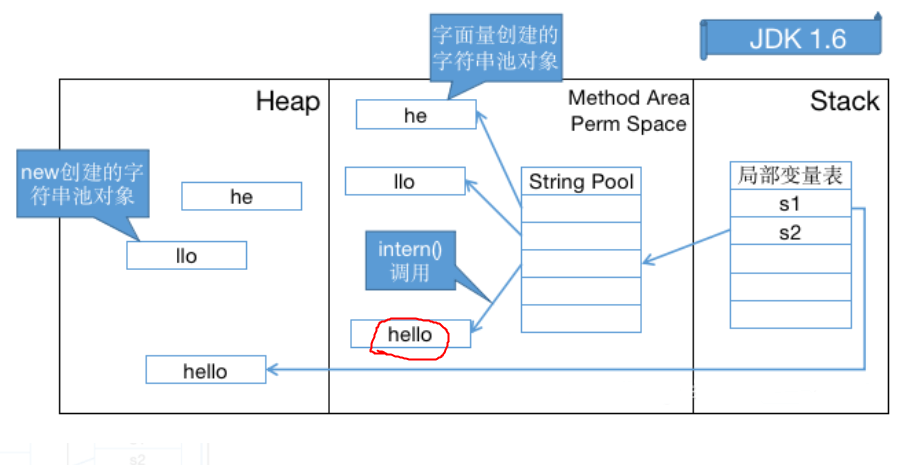
1.7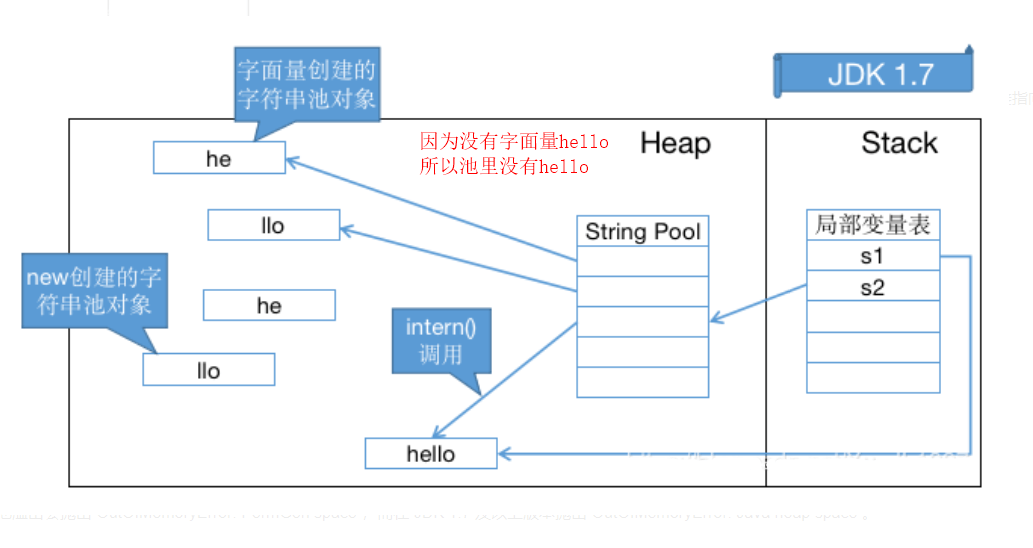
JDK 1.6 字符串池溢出会抛出 OutOfMemoryError: PermGen space ,而在 JDK 1.7 及以上版本抛出 OutOfMemoryError: Java heap space
示例1:
String s0="zhuge";String s1="zhuge";String s2="zhu" + "ge";System.out.println( s0==s1 ); //trueSystem.out.println( s0==s2 ); //true// + 前后都是字面量会优化掉
示例2:
String s0="zhuge";String s1=new String("zhuge");String s2="zhu" + new String("ge");System.out.println( s0==s1 ); // falseSystem.out.println( s0==s2 ); // falseSystem.out.println( s1==s2 ); // false//s0-常量池,s1-堆,s2的+ 不识别符号引用,s2是一个新对象
String a = "a1";String b = "a" + 1;System.out.println(a == b); // trueString a = "atrue";String b = "a" + "true";System.out.println(a == b); // trueString a = "a3.4";String b = "a" + 3.4;System.out.println(a == b); // true//数值也是字面量,会被编译器优化
示例4:
String a = "ab";String bb = "b";String b = "a" + bb;System.out.println(a == b); // false// + 不会优化符号引用,bb是符号引用不是字面量,
示例5:
String a = "ab";final String bb = "b";String b = "a" + bb;System.out.println(a == b); // true// fianl 编译是会解析为常量值得一个本地拷贝到字节码中,
示例6:
String a = "ab";final String bb = getBB();String b = "a" + bb;System.out.println(a == b); // falseprivate static String getBB(){return "b";}// bb对应的是引用,不是字面量,编译期无法确定,还是会动态链接分配
示例7
String s = "a" + "b" + "c"; //就等价于String s = "abc";String a = "a";String b = "b";String c = "c";String s1 = a + b + c;
示例8:关键字的缓存
//字符串常量池:"计算机"和"技术" 堆内存:str1引用的对象"计算机技术"//堆内存中还有个StringBuilder的对象,但是会被gc回收,StringBuilder的toString方法会new String(),这个String才是真正返回的对象引用String str2 = new StringBuilder("计算机").append("技术").toString(); //没有出现"计算机技术"字面量,所以不会在常量池里生成"计算机技术"对象System.out.println(str2 == str2.intern()); //true//"计算机技术" 在池中没有,但是在heap中存在,则intern时,会直接返回该heap中的引用//字符串常量池:"ja"和"va" 堆内存:str1引用的对象"java"//堆内存中还有个StringBuilder的对象,但是会被gc回收,StringBuilder的toString方法会new String(),这个String才是真正返回的对象引用String str1 = new StringBuilder("ja").append("va").toString(); //没有出现"java"字面量,所以不会在常量池里生成"java"对象System.out.println(str1 == str1.intern()); //false//java是关键字,在JVM初始化的相关类里肯定早就放进字符串常量池了String s1=new String("test");System.out.println(s1==s1.intern()); //false//"test"作为字面量,放入了池中,而new时s1指向的是heap中新生成的string对象,s1.intern()指向的是"test"字面量之前在池中生成的字符串对象String s2=new StringBuilder("abc").toString();System.out.println(s2==s2.intern()); //false//同上
八种基本类型的包装类和对象池缓存
Byte ,Short,Integer ,Long,Character,Boolean Double没有,
public class Test {public static void main(String[] args) {//5种整形的包装类Byte,Short,Integer,Long,Character的对象,//在值小于127时可以使用对象池Integer i1 = 127; //这种调用底层实际是执行的Integer.valueOf(127),里面用到了IntegerCache对象池Integer i2 = 127;System.out.println(i1 == i2);//输出true//值大于127时,不会从对象池中取对象Integer i3 = 128;Integer i4 = 128;System.out.println(i3 == i4);//输出false//用new关键词新生成对象不会使用对象池Integer i5 = new Integer(127);Integer i6 = new Integer(127);System.out.println(i5 == i6);//输出false//Boolean类也实现了对象池技术Boolean bool1 = true;Boolean bool2 = true;System.out.println(bool1 == bool2);//输出true//浮点类型的包装类没有实现对象池技术Double d1 = 1.0;Double d2 = 1.0;System.out.println(d1 == d2);//输出false}}
示例: Intege的 IntegeCache
private static class IntegerCache {static final int low = -128;static final int high;static final Integer cache[];static {// high value may be configured by propertyint h = 127;String integerCacheHighPropValue =sun.misc.VM.getSavedProperty("java.lang.Integer.IntegerCache.high");if (integerCacheHighPropValue != null) {try {int i = parseInt(integerCacheHighPropValue);i = Math.max(i, 127);// Maximum array size is Integer.MAX_VALUEh = Math.min(i, Integer.MAX_VALUE - (-low) -1);} catch( NumberFormatException nfe) {// If the property cannot be parsed into an int, ignore it.}}high = h;cache = new Integer[(high - low) + 1];int j = low;for(int k = 0; k < cache.length; k++)cache[k] = new Integer(j++);// range [-128, 127] must be interned (JLS7 5.1.7)assert IntegerCache.high >= 127;}private IntegerCache() {}}

若有收获,就点个赞吧
0 人点赞
