事务及其ACID属性
ACID属性
- Atomicity 原子性:要么全部执行,要么全不执行的一操作单元
- Consistend 一致性: 事务开始和完成,数据必须是一致的,所有相关的数据规则必须应用与数据的修改
保证数据的完整性 - Isolation 隔离性:事务不受外部并发操作的影响,事务的中间态对外界不可见
- Durable 持久性:事务完成之后,对于数据的修改是永久的
并发事务处理带来的问题
更新丢失(Lost Update)或脏写
:多个事务修改了同一行数据,都是基于最初值修改,造成最后的修改覆盖了其他事务的修改
脏读(Dirty Reads)
:一个事务读到了另个一事务已经修改但还没提交的数据
不可重读(Non-Repeatable Reads)
:一个事务中,两次读到的数据不一样
幻读(Phantom Reads)
:一个事务中,读到了另一个事务提交的新增数据
事务隔离级别
“脏读”、“不可重复读”和“幻读”,其实都是数据库读一致性问题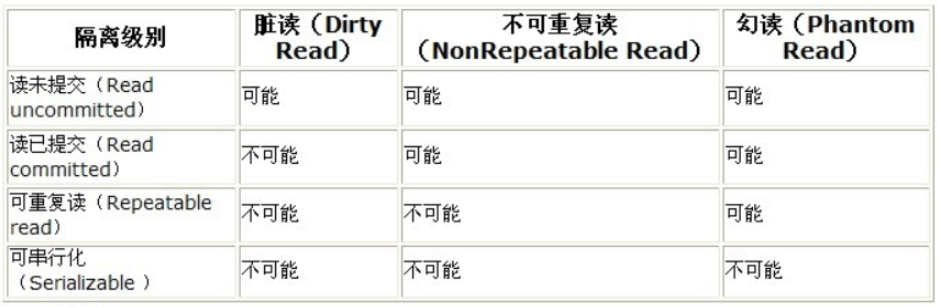
常看当前数据库的事务隔离级别**show variables like 'tx_isolation';**
设置事务隔离级别:set tx_isolation=’REPEATABLE-READ’; 可重复读 设置事务隔离级别:set tx_isolation=’read-uncommitted‘ : 读未提交 设置事务隔离级别:set tx_isolation=’read-committed‘; 读已提交 设置事务隔离级别:set tx_isolation=’serializable‘; 串行化 Spring 可以设置隔离级别
锁详解
锁是计算机协调多个进程或线程并发访问某一资源的机制。
锁分类
- 性能上分:乐观锁悲观锁
- 操作上分:
- 读锁: 共享锁 S锁,shared
- 写锁:排他锁 X锁,exclusive
- 粒度分:
- 表锁
- 行锁
表锁
一般数据迁移的场景使用
开销小,加锁快,不会出现死锁;
并发度较低
lock table mylock read; 当前session和其他session都可以读 当前session cud会报错,其他session等待 lock table mylock write; 当前session都可以 其他session会阻塞
加锁命令:
lock table tableName read(write) ,tableName2 read(write);
查看表上加过的锁
show open tables;
删除表锁
unlock tables;
行锁
开销大,加锁慢,会出现死锁,粒度小,并发高
InnoDB支持 事务,支持行级锁
一个session开启事务不提交,另个session更新同一条数据会被阻塞,不同的记录不会
间隙锁(Gap Lock)
可重复读隔离级别下才会生效
范围操作,会对范围内的行数据都加锁,包括还不存在的间隙
可重复读隔离级别下才会生效
示例: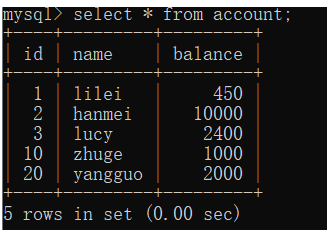
间隙就有 id 为 (3,10),(10,20),(20,正无穷) 这三个区间
执行 update account set name = ‘zhuge’ where id > 8 and id <18;
那么3,10,20 都会被锁,因为8 在(3,10)中,18在(10,20)中
临键锁(Next-key Locks)
Next-Key Locks是行锁与间隙锁的组合。像上面那个例子里的这个(3,20]的整个区间可以叫做临键锁。
范围的临界也会被加锁
不包括起始临界值
无索引行锁会升级为表锁,RR级别会升级为表锁,RC级别不会升级为表锁
锁是加在索引上的,如果对非索引字段更新,行锁可能会变成表表锁
InnoDB的行锁是针对索引加的锁,不是针对记录加的锁。并且该索引不能失效,
否则都会从行锁升级为表锁。
还是lock in share mode(共享锁) for update(排他锁)
select * from test_innodb_lock where a = 2 for update; 其他session只能读,修改则会被阻塞,直到锁定行的session提交
结论:
InnoDB实现了行锁,并发会搞,性能消耗比表级高,高并发下性能较高
行锁与事务隔离级别案例分析
1、读未提交
set tx_isolation=’read-uncommitted’;
A事务会读到B事务 update的值,在commit之前
update account set balance = balance - 50 where id =1 这种字段加减balance 取得是最新的值,
3、读已提交
set tx_isolation=’read-committed’;
A事务在B事务commit之后,才能读到Bupdate的数据
4、可重复读
set tx_isolation=’repeatable-read‘;
A事务后续读到的数据,与第一次select的数据一致,无论B事务是否commit
A事务commit后,再select才能获取B update的数据
update account set balance = balance - 50 where id = 1 , A如果执行这个update,是能用B update后的balance扣减的 select遵守可重复读,MVCC控制的,但是select能查到B事务的insert 但insert ,update ,delete 是对最新的版本操作
5、串行化
set tx_isolation=’serializable‘;
A事务还没commit ,B事务更新同一个Id会阻塞,行锁的模式
如果是范围,间隙锁也会被加锁
事务中,select也会加锁,会被阻塞中
查到的记录也会被加锁,来满足隔离性
select * from table for update == 串行化
分析已经相关命令
show status like ‘innodb_row_lock%’; 分析行锁的争夺情况
状态量:
Innodb_row_lock_current_waits: 当前正在等待锁定的数量 Innodb_row_lock_time: 从系统启动到现在锁定总时间长度 Innodb_row_lock_time_avg: 每次等待所花平均时间 Innodb_row_lock_time_max:从系统启动到现在等待最长的一次所花时间 Innodb_row_lock_waits: 系统启动后到现在总共等待的次数
查看INFORMATION_SCHEMA系统库锁相关数据表
— 查看事务 select from INFORMATION_SCHEMA.INNODB_TRX; — 查看锁 select from INFORMATION_SCHEMA.INNODB_LOCKS; — 查看锁等待 select * from INFORMATION_SCHEMA.INNODB_LOCK_WAITS; — 释放锁, trx_mysql_thread_id可以从INNODB_TRX表里查看到 kill trx_mysql_thread_id — 查看锁等待详细信息 show engine innodb status
死锁:
show engine innodb status\G; 查看死锁日志
锁优化建议:
- 所有检索通过索引完成,避免无索引导致行锁升级为表锁
- 合理设计索引,缩小锁的范围
- 避免间隙锁
- 控制事务大小,减少锁定的资源量和时间,加锁的sql尽量写在最后
- 尽可能降低事务隔离级别

若有收获,就点个赞吧
0 人点赞
