任务类型
- CPU密集型:计算密集,, 比如加密,解密,计算类型,需要用到CPU, 一般设置为CPU核数的 1- 2 倍。
过多:线程上下文切换耗时
过少:CPU 浪费 - IO 密集型: 比如读写操作,网络通信之类,不会特别消耗CPU,,IO操作耗时。
可以设置为核数的多倍,IO 操作设计的CPU处理较少,
线程数计算方法
线程数 = CPU 核心数 *(1+平均等待时间/平均工作时间)
如果任务平均等待时间长,线程数可以越多,——-IO密集型
如果任务平均工作时间长,线程数就少 ——————CPU密集型
最准确的是压测,确定线程数
分治思想
归并,把规模为N的问题分解成K个小规模的子问题。求出子问题,归并总结就是原来的大问题
步骤
- 分解
- 求解
- 合并
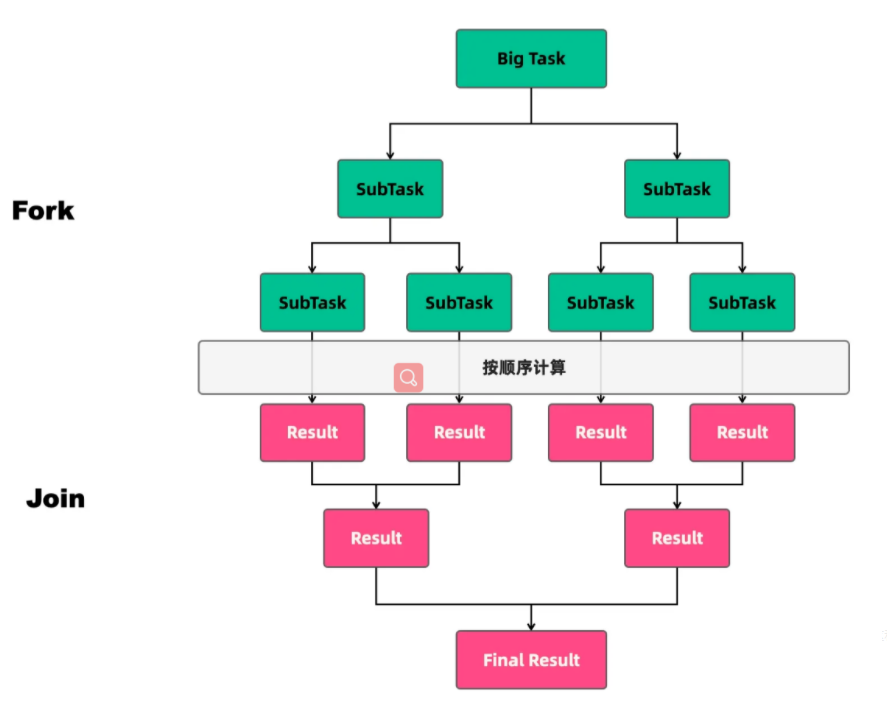
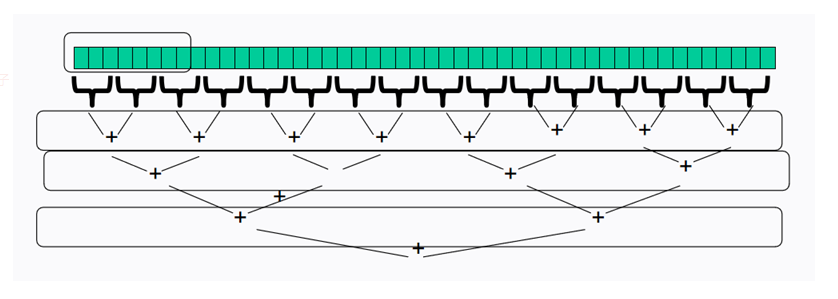
应用场景
归并排序
快速排序
二分查找
大数据-MapReduce
Fork/Join
Fork/Join框架介绍
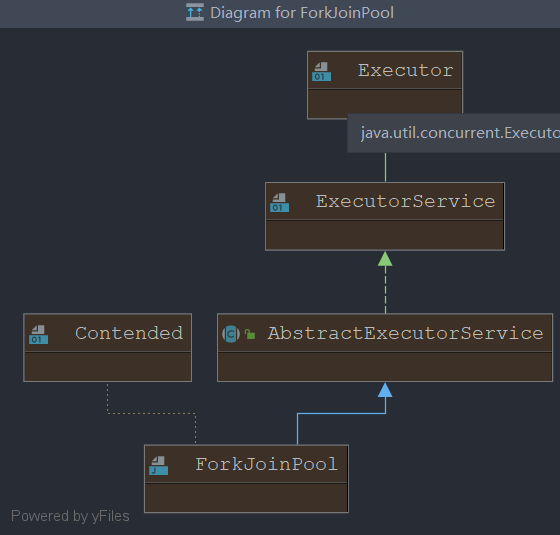
ThreadPoolExecutor的确定
- 大任务无法分解,只能串行
- 工作线程从队列获取任务存在竞争
核心类:ForkJoinPool类
是对ThreadPoolExecutor的补充,仅针对计算密集型的场景加强,
使用时需要对:任务总数,单任务执行耗时,并行数评估性能
结构: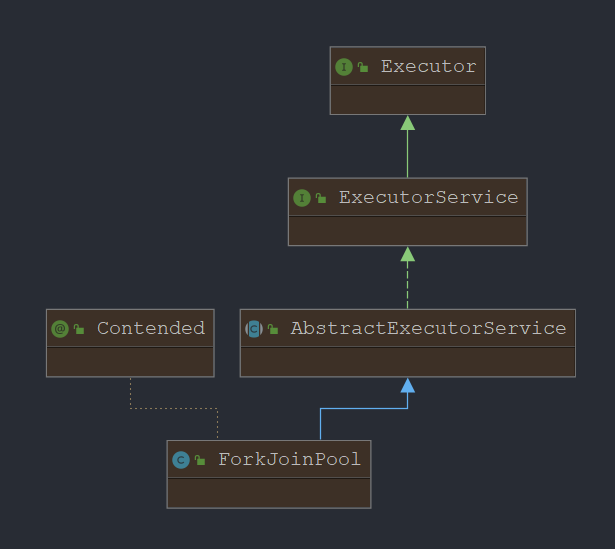
Fork/Join的使用
Fork/Join 计算框架主要包含两部分,
- 分治任务的线程池 ForkJoinPool,
- 分治任务 ForkJoinTask
ForkJoinPool
用于执行ForkJoinTask任务的执行线程池。维护队列数据 WorkQueue(WorkQueue[])
目的:减少提交任务的碰撞
ForkJoinPool构造器

//public ForkJoinPool(int parallelism,ForkJoinWorkerThreadFactory factory,UncaughtExceptionHandler handler,boolean asyncMode) {this(checkParallelism(parallelism),checkFactory(factory),handler,asyncMode ? FIFO_QUEUE : LIFO_QUEUE,"ForkJoinPool-" + nextPoolId() + "-worker-");checkPermission();}
ForkJoinPool的四个核心参数
- parallelism:并行级别,决定工作线程的数量,默认缺省:Runtime.getRuntime().availableProcessors()
- ForkJoinWorkerThreadFactory:创建线程,缺省:DefaultForkJoinWorkerThreadFactory创建线程
- UncaughtExceptionHandler:异常处理器
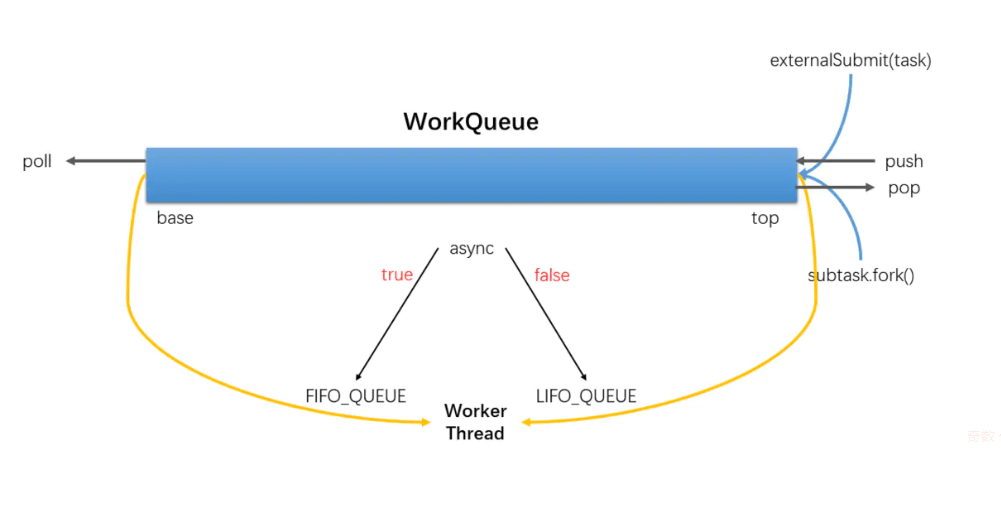
- _boolean _asyncMode :队列工作模式,asyncMode ? FIFO_QUEUE : LIFO_QUEUE, 先进先出,后进先出
按类型提交不同任务
任务提交是ForkJoinPool的核心能力之一,提交任务有三种方式:
| 返回值 | 方法 | ||
|---|---|---|---|
| 提交异步执行 | void | execute(ForkJoinTask task) execute(Runnable task) |
普通不可分割的任务 仅有任务窃取的性能提升 |
| 等待并获取结果 | T | invoke(ForkJoinTask task) | 任务结束后发挥泛型结果, 如果task = null 报错 |
| 提交执行获取Future结果 | ForkJoinTask | submit(ForkJoinTask task) submit(Callabletask) submit(Runnable task) submit(Runnable task, T result) |
//递归任务 用于计算数组总和LongSum ls = new LongSum(array, 0, array.length);// 构建ForkJoinPoolForkJoinPool fjp = new ForkJoinPool(12);//ForkJoin计算数组总和ForkJoinTask<Long> result = fjp.submit(ls);
ForkJoinTask
任务的实际载体
定义任务执行是的具体逻辑和拆分逻辑,
各个任务独立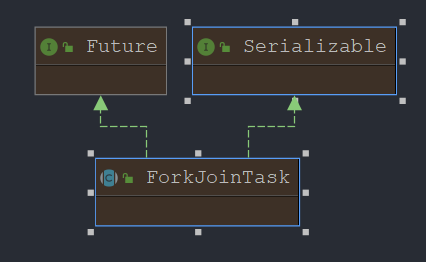
ForkJoinPool 的工作原理
- 内部维护多个工作队列,invoke,submit提交
- 每个线程对应一个工作线程WorkQueue, 双端队列,存放对象是任务ForkJoinTask
- 当每个线程产生新任务时,会放入工作队列的top,并且工作线程会处理自己队列里的任务是LIFO,从top取
- 窃取任务时从队列的base位置,窃取别的线程的任务时FIFO
- join时,如果join的任务未完成,会先处理其他任务,等待完成
- 如果自己的完成,也没有窃取,会休眠
工作窃取
性能保证的关键之一,窃取繁忙线程的任务,减少线程竞争的可能性
work-strealing queues 窃取对了
内部类WorkQueue实现
// Instance fieldsvolatile int scanState; // versioned, <0: inactive; odd:scanningint stackPred; // pool stack (ctl) predecessorint nsteals; // number of stealsint hint; // randomization and stealer index hintint config; // pool index and modevolatile int qlock; // 1: locked, < 0: terminate; else 0volatile int base; // index of next slot for pollint top; // index of next slot for pushForkJoinTask<?>[] array; // the elements (initially unallocated)final ForkJoinPool pool; // the containing pool (may be null)final ForkJoinWorkerThread owner; // owning thread or null if sharedvolatile Thread parker; // == owner during call to park; else nullvolatile ForkJoinTask<?> currentJoin; // task being joined in awaitJoinvolatile ForkJoinTask<?> currentSteal; // mainly used by helpStealer
Deques的特殊形式
支持三种操作
- push 当前线程
- pop 当前线程
- poll 窃取 其他线程
工作窃取的运行流畅取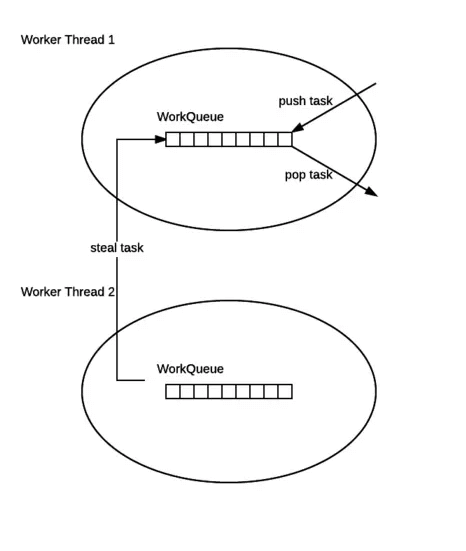
- 优点:充分利用线程,进行并行计算,减少线程间的竞争
- 缺点:只有一个任务时poll 与 pop竞争,多个线程,多个队列资源要求较高
思考:为什么这么设计,工作线程总是从头部获取任务,窃取线程从尾部获取任务?
自己取任务,取最近的,任务可能还在CPU缓存中,处理效率高,
而偷,为了避免竞争,从尾部降低竞争的可能性,
另外:由于任务时可分割的,较早的任务可能粒度较大,还未分割,交给空闲线程更适合
工作队列WorkQueue
- 双向链表,
- 每个ForkJoinWorkThread 线程都有属于自己的WorkQueue,但不是每个WorkQueue都有对应的线程
- 没有ForkJoinWorkThread的WorkQueue保存的是 subminnion,l来自外部的提交,队列中下标是偶数位
ForkJoinWorkerThread
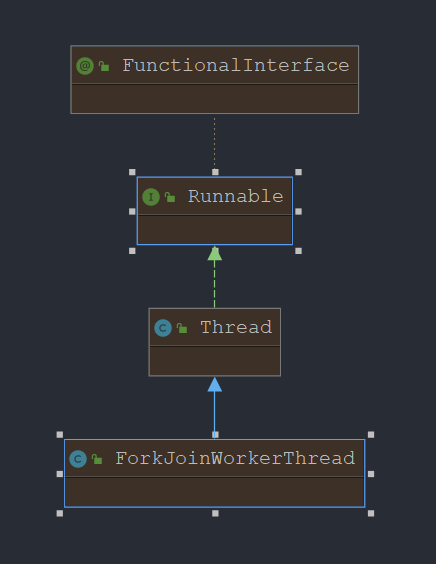
用来执行任务的线程,用来区分非ForkJoinWorkerThread线程提交的task 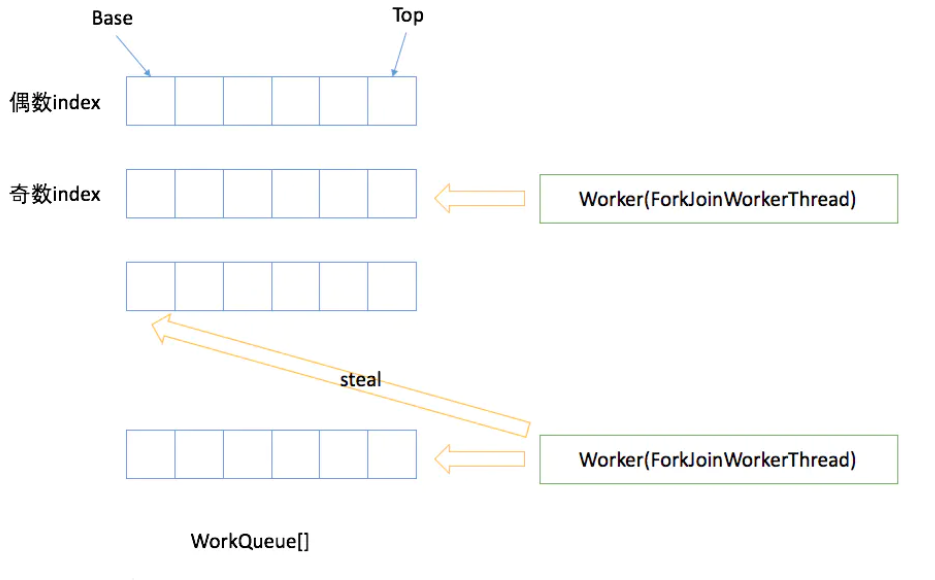
流程图:
https://www.processon.com/view/link/5db81f97e4b0c55537456e9a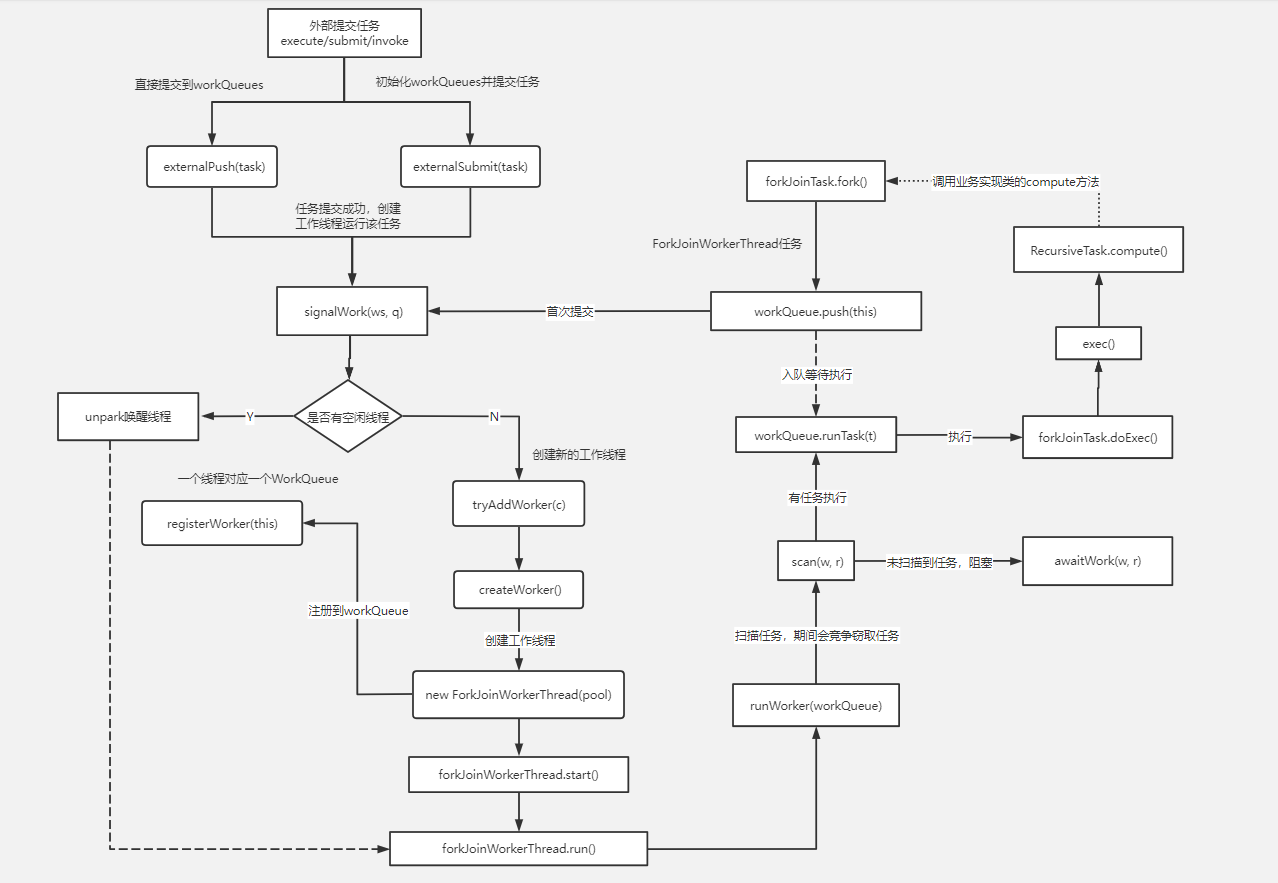
总结
Fork/Join是一种基于分治算法的模型,在并发处理计算型任务时有着显著的优势。其效率的提升主要得益于两个方面:
- 任务切分:将大的任务分割成更小粒度的小任务,让更多的线程参与执行;
- 任务窃取:通过任务窃取,充分地利用空闲线程,并减少竞争。
在使用ForkJoinPool时,需要特别注意任务的类型是否为纯函数计算类型,也就是这些任务不应该关心状态或者外界的变化,这样才是最安全的做法。如果是阻塞类型任务,那么你需要谨慎评估技术方案。虽然ForkJoinPool也能处理阻塞类型任务,但可能会带来复杂的管理成本。
ForkJOinPool.common.externaPush 并行流用的是个,注意点
使用示例
LongSum ls = new LongSum(array, 0, array.length);ForkJoinPool fjp = new ForkJoinPool(NCPU);ForkJoinTask<Long> result = fjp.submit(ls);public class LongSum extends RecursiveTask<Long> {// 任务拆分最小阈值static final int SEQUENTIAL_THRESHOLD = 10000000;int low;int high;int[] array;LongSum(int[] arr, int lo, int hi) {array = arr;low = lo;high = hi;}//需要写逻辑@Overrideprotected Long compute() {//当任务拆分到小于等于阀值时开始求和if (high - low <= SEQUENTIAL_THRESHOLD) {long sum = 0;for (int i = low; i < high; ++i) {sum += array[i];}return sum;} else { // 任务过大继续拆分int mid = low + (high - low) / 2;LongSum left = new LongSum(array, low, mid);LongSum right = new LongSum(array, mid, high);// 提交任务left.fork();right.fork();//获取任务的执行结果,将阻塞当前线程直到对应的子任务完成运行并返回结果long rightAns = right.compute();long leftAns = left.join();return leftAns + rightAns;}}}

若有收获,就点个赞吧
0 人点赞
