消费者Rebalance机制
时机:
消费者数量,分区数量发生变化是才会rebalance,
且只针对subscribe这种不指定分区的消费,如果是指定分区assign的方式不会rebalance
rebalance时消费者无法从kafka消费消息了,会影响TPS,一般建议避免高峰重平衡
rebalance过程
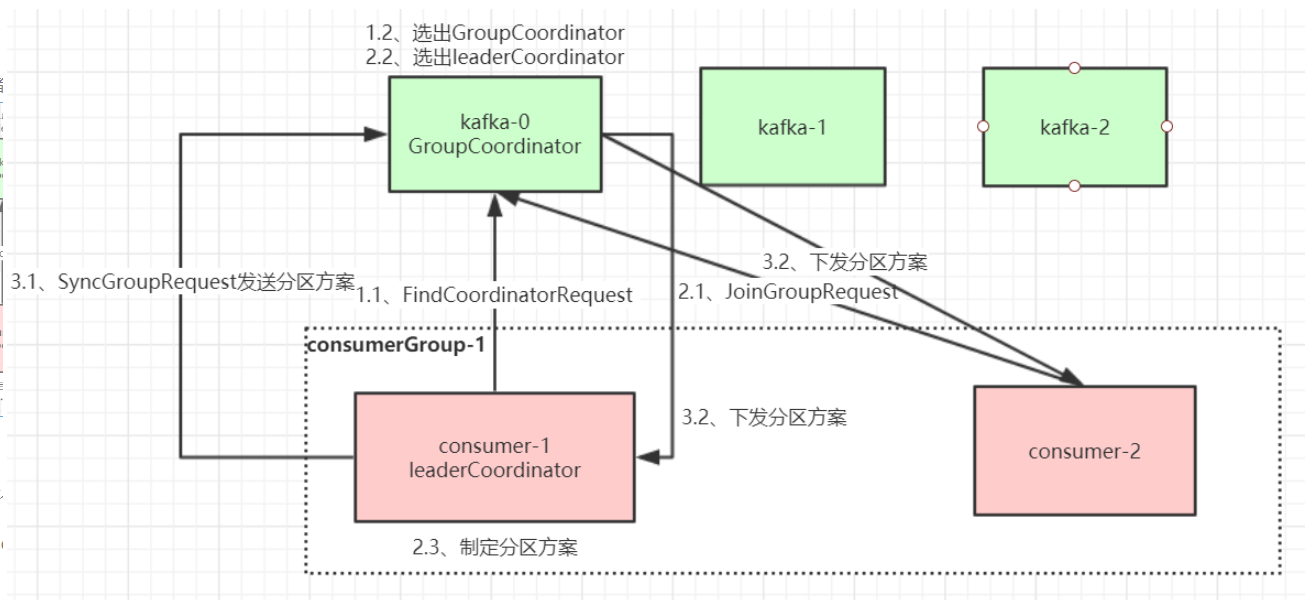
- 选择组协调器
消费组会选一个broker作为组的协调器,
负责健康消费组的心跳,判断是否存活
消费者rebalance时,每个consumer都会向kafka,发送请求。
消费者消费的offset提交到哪个分区,对应分区的broker就是这个协调器
- 加入消费组
找到协调器后, - sync group
协调者会同步分区方案给consumer,指定的broker消费
消费者rebalance分区分配策略
- range:
根据分区号顺序平均分,竟可能的平均分配 - round-robin
依次轮训分配, - sticky
与round-robin类似,在rebalance时候,需要准守下面的原则
1:分区尽可能平均
2:分区分配尽可能和上次分配的相同
producer发布消息机制
1:写入方式
push模式推送到broker,消息被append到partition,顺序写磁盘的方式
2:消息路由
消息发送到broker,会根据分区算法存储到哪个partition
- 如果指定了partition,直接使用
- 未指定partition,但是有key,会根据key,valese hash一个partition
- 如果都没有,就轮训
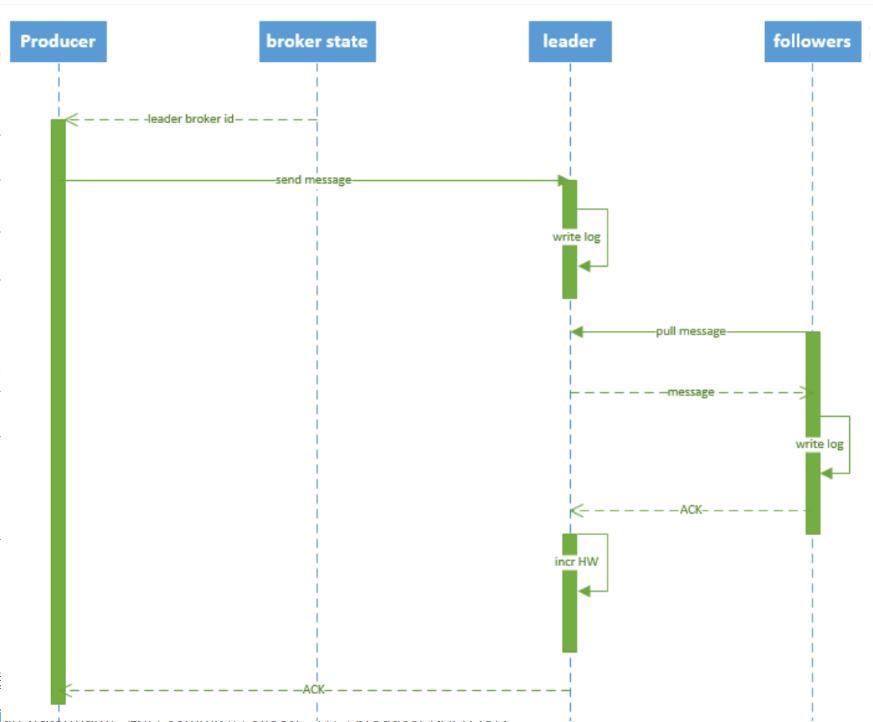
3:写入流程
- 生产者从zk上找到对应partition的leader
- 消息发给该leader
- leader写入本地log
- follower从pull消息,写入本地,发送ack
- leader收到ISR的副本ack,增加HW,向生产ACK
HW高水位,LEO
取一个partition对应的ISR中最小的LEO(log-end-offset)作为HW
就是在leader记录一个offset位置,消费者只消费到这个offset
新消息来了之后,只有副本的offset也确定写入了消息,
leader才确定更新高水位,消费者就可以消费了
Kafka的复制机制既不是完全的同步复制,也不是单纯的异步复制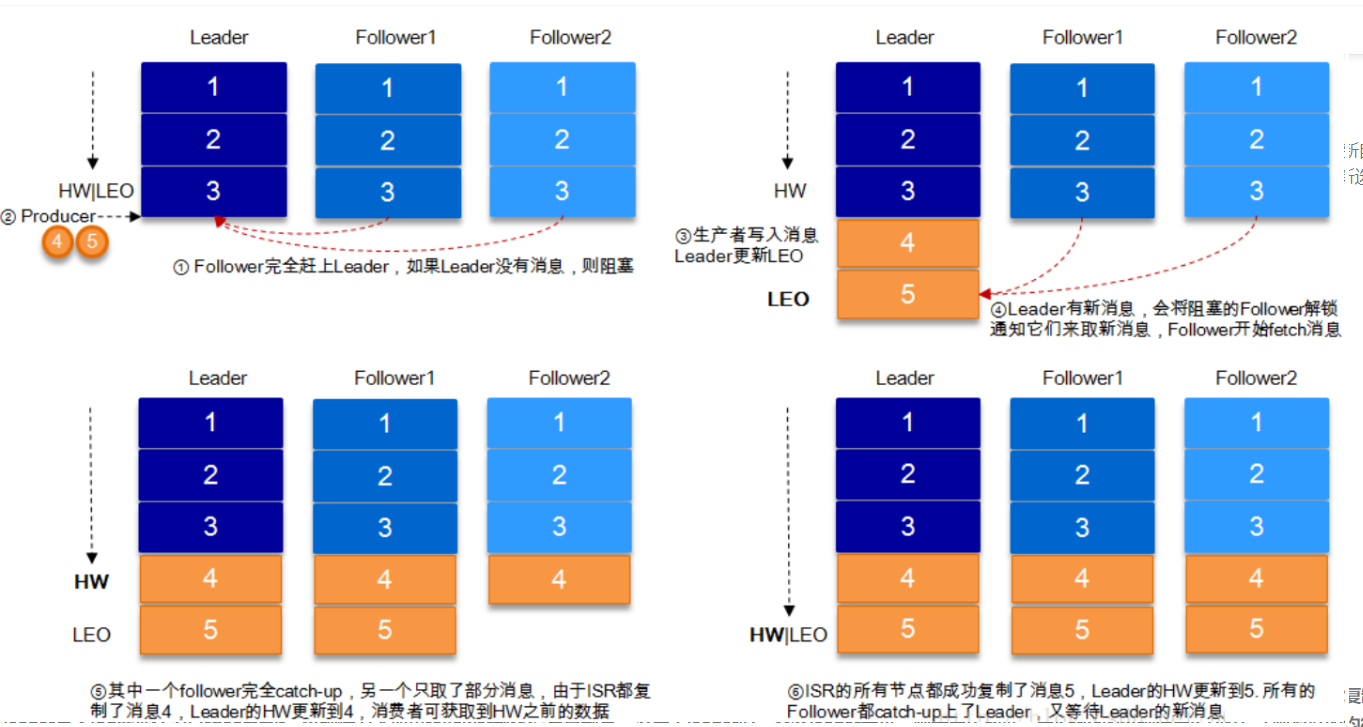
日志分段存储
一个分区的消息数据对应存储在一个文件夹下,以topic名称+分区号命名
消息在分区内是分段(segment)存储,每个段的消息都存储在不一样的log文件里
方便old segment file快速被删除
最多1G
部分消息的offset索引文件,kafka每次往分区发4K(可配置)消息就会记录一条当前消息的offset到index文件,
如果要定位消息的offset会先在这个文件里快速定位,再去log文件里找具体消息
00000000000000000000.index
消息存储文件,主要存offset和消息体
00000000000000000000.log
消息的发送时间索引文件,kafka每次往分区发4K(可配置)消息就会记录一条当前消息的发送时间戳与对应的offset到timeindex文件,
如果需要按照时间来定位消息的offset,会先在这个文件里查找
00000000000000000000.timeindex 00000000000005367851.index 00000000000005367851.log 00000000000005367851.timeindex 00000000000009936472.index 00000000000009936472.log 00000000000009936472.timeindex
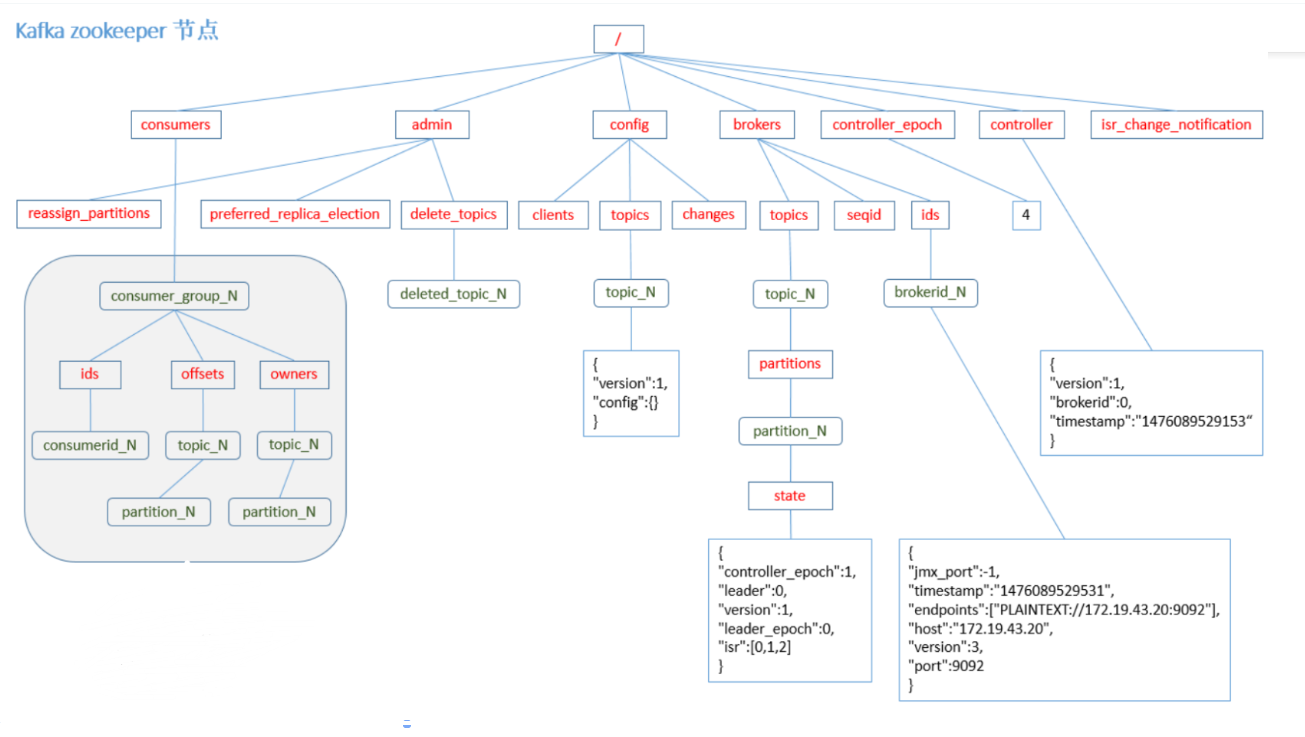
zk结点数据信息

若有收获,就点个赞吧
0 人点赞
