可视化安装工具kafka-manager
https://www.cnblogs.com/dadonggg/p/8205302.html
线上环境规划
计算设计参数流程图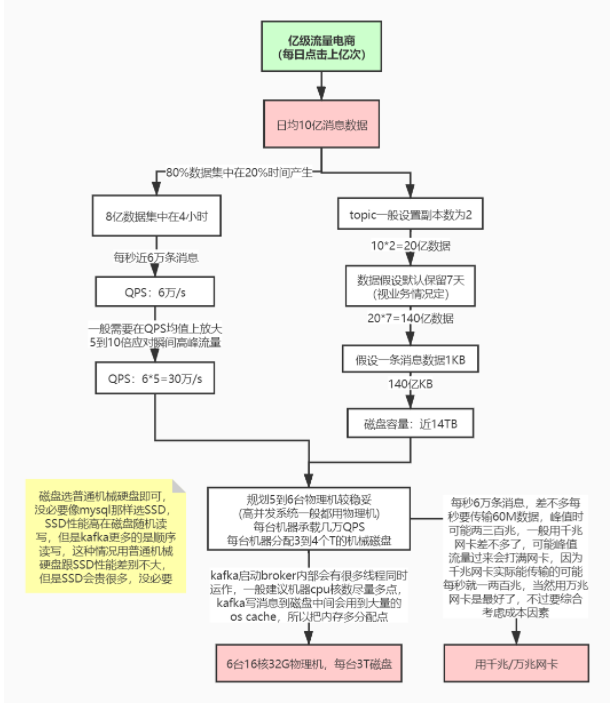
JVM参数
可以在bin/kafka-start-server.sh 中配置jvm参数
export KAFKA_HEAP_OPTS=”-Xmx16G -Xms16G -Xmn10G -XX:MetaspaceSize=256M -XX:+UseG1GC -XX:MaxGCPauseMillis=50 -XX:G1HeapRegionSize=16M”
线上问题及优化
1、消息丢失情况:
生产者:
- acks= 0 : 生产者不需要收到broker的确认,最容易丢数据,
- acks=1 :至少等待leader一个成功,leader挂了,也会丢数据
- acks=-1/all : 保证所有备份都写入日志,最强保证,但是性能不高
消费者:
如果配置自动提交会出现还没消费就提交了
一般设置手动确认
2、消息重复消费
发送端:
发送端重试机制,会出现
但是高版本会有幂等的控制
消费端:
一般在消费端手动做幂等处理
3、消息乱序
根据业务需要可以把指定发送到同一个分区,用同一个消费者消费
但是效率比较低
可以用内存队列保存有序的队列保证顺序
4、消息积压
1:生产者过快,或消费者太慢,会出现broker挤压
可以把消息转发到其他topic,启动多个消费者去消费新主题的不同分区
2:由于消费逻辑,或bug导致的消费不成功导致的挤压,需要自己把消息转发到其他队列
kafka没有自己实现死信队列
5、延时队列
同样,kafka也没有实现延迟队列
需要自己手动设计实现
设计:
根据不同的延迟时间,区分不同的主题,
先发到延迟主题,消费寻轮是否可以消费了,如果可以就把消息转发给对应的业务主题立即消费即可
6、消息回溯
可以利用consumer的offsetForTimes .seek 方法从指定的offset开始消费
7、分区数越多吞吐量越高吗
当然不是,需要自己压测,判断最佳的分区大小
bin/kafka-producer-perf-test.sh —topic test —num-records 1000000 —record-size 1024 —throughput -1 —producer-props bootstrap.servers=192.168.65.60:9092 acks=1 kafka提供的压测脚本
往test里发送一百万消息,每条设置1KB
throughput 用来进行限流控制,当设定的值小于 0 时不限流,当设定的值大于 0 时,
当发送的吞吐量大于该值时就会被阻塞一段时间
跟磁盘,文件系统,IO等因素有关
如果过大比如 10000,可能会报错,”java.io.IOException : Too many open files”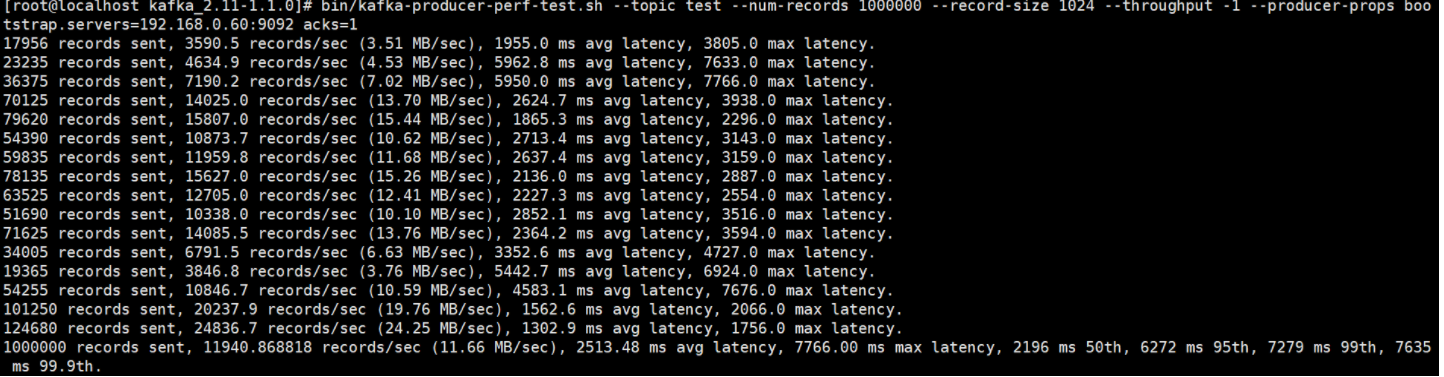
8、消息传递保障
- at most once(消费者最多收到一次消息,0—1次):acks = 0 可以实现。
- at least once(消费者至少收到一次消息,1—多次):ack = all 可以实现。
- exactly once(消费者刚好收到一次消息):at least once 加上消费者幂等性可以实现,还可以用kafka生产者的幂等性来实现。
生产者幂等, 只保证重复的消息只接受一次
props.put(“enable.idempotence”, true) 即可,默认是false不开启
具体实现:发送消息会分配一个pid和 sequence number ,
broker会把pid ,跟sequence number跟消息绑定,根据这两个值判断是否已存在
PID:对应每个producer初始化时分配的唯一pid
sequencenumber : 对每个pid ,该producer 发送到每个parititonde 数据的对应的序列化从0开始递增的
9、kafka的事务
类似本地事务,只保证同一个批量的消息事务
不能保证,发送者更broker的事务
一般流式计算中,把消息发送不同的下游消费,需要保证事务
不能保证类似rockerMQ的事务
文档:
https://kafka.apache.org/24/javadoc/index.html?org/apache/kafka/clients/producer/KafkaProducer.html
Properties props = new Properties();props.put("bootstrap.servers", "localhost:9092");props.put("transactional.id", "my-transactional-id");Producer<String, String> producer = new KafkaProducer<>(props, new StringSerializer(), new StringSerializer());//初始化事务producer.initTransactions();try {//开启事务producer.beginTransaction();for (int i = 0; i < 100; i++){//发到不同的主题的不同分区producer.send(new ProducerRecord<>("hdfs-topic", Integer.toString(i), Integer.toString(i)));producer.send(new ProducerRecord<>("es-topic", Integer.toString(i), Integer.toString(i)));producer.send(new ProducerRecord<>("redis-topic", Integer.toString(i), Integer.toString(i)));}//提交事务producer.commitTransaction();} catch (ProducerFencedException | OutOfOrderSequenceException | AuthorizationException e) {// We can't recover from these exceptions, so our only option is to close the producer and exit.producer.close();} catch (KafkaException e) {// For all other exceptions, just abort the transaction and try again.//回滚事务producer.abortTransaction();}producer.close();
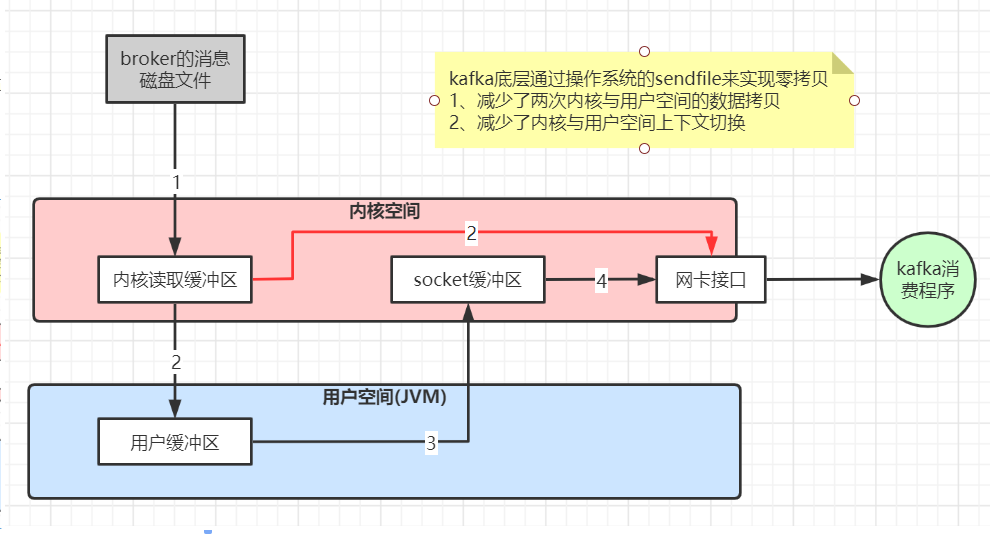
10、kafka高性能的原因
- 磁盘顺序读写,在尾部追加,保证局部顺序,不是全部保证顺序
- 数据传输零拷贝
- 读写数据的批量Barche处理以及数据压缩传输

若有收获,就点个赞吧
0 人点赞
