1:持久化:
RDB快照
配置:
指定文件名 dbfilename dump.rdb .rdb文件 二进制 指定目录 dir ./ 满足60秒,1000个键被改动时触发 save 60 1000
客户端还可以指定同步,执行命令 save 或bgsave, 只会有一个rdb文件,每次都会覆盖
save: 同步
bgsave : 异步
写时复制机制(COW):
copy on write,
bgsave子进程是 主线程fork,可以共享主线线程的数据
读不受影响
当注主线程修改一个数据时,数据会被复制一份,bgsave把这个副本写入rdb文件
save与bgsave对比:
| 命令 | save | bgsave |
|---|---|---|
| IO类型 | 同步 | 异步 |
| 是否阻塞redis其它命令 | 是 | 否(在生成子进程执行调用fork函数时会有短暂阻塞) |
| 复杂度 | O(n) | O(n) |
| 优点 | 不会消耗额外内存 | 不阻塞客户端命令 |
| 缺点 | 阻塞客户端命令 | 需要fork子进程,消耗内存 |
配置自动生成rdb文件后台使用的是bgsave方式。
缺点:
AOF
append only file
每修改一条,就会写入appendonly.aof文件
配置:
appendonly yes #开启
appendonly.aof文件内容:
执行命令: set zhuge 666” 3 $3 set $5 zhuge $3 666 3:总共几个参数 $3: 参数的长度
带过期时间命令的时间戳不一样
set adbce 888 ex 1000 3 $3 set $6 adbce
$3 888 3 $9 PEXPIREAT $6 adbce $13 1604249786301
其他同步的配置
appendfsync always:每次有新命令追加到 AOF 文件时就执行一次 fsync ,非常慢,也非常安全。 appendfsync everysec:每秒 fsync 一次,足够快,并且在故障时只会丢失 1 秒钟的数据。 默认 appendfsync no:从不 fsync ,将数据交给操作系统来处理。更快,也更不安全的选择。
AOF重写
比如incr命令造成中间很多的incr可以忽略,所以需要对aof重做
重做的配置
auto-aof-rewrite-min-size 64mb //aof文件至少要达到64M才会自动重写, 文件太小恢复速度本来就很快,重写的意义不大 auto-aof-rewrite-percentage 100 //aof文件自上一次重写后文件大小增长了100%则再次触发重写
客户端手动执行重写的命:
bgrewriteaof 也是fork的子线程,不影响主线程
RDB VS AOF的比较
| 命令 | RDB | AOF |
|---|---|---|
| 启动优先级 | 低 | 高 |
| 体积 | 小 | 大 |
| 恢复速度 | 快 | 慢 |
| 数据安全性 | 容易丢数据 | 根据策略决定 |
混合
redis4.0之后支持
开启配置:
aof-use-rdb-preamble yes
过程: 就是在aop重写的时候,写的不是aof ,先写RDB
- 先把原来生成rdb 处理
- 把生成rdb的增量也存在 上面的rdb中,
- 合成一个先的appendonly.aof, 就搞定了
就是一部分rdb,一部分aof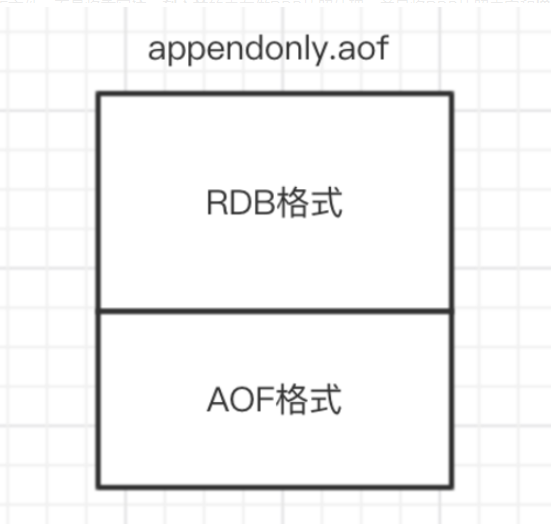
客户端也可以执行命令主动发起持久化
关闭redis会生成一个aof文件
Redis数据备份策略:
- 写crontab定时调度脚本,每小时都copy一份rdb或aof的备份到一个目录中去,仅仅保留最近48小时的备份
- 每天都保留一份当日的数据备份到一个目录中去,可以保留最近1个月的备份
- 每次copy备份的时候,都把太旧的备份给删了
- 每天晚上将当前机器上的备份复制一份到其他机器上,以防机器损坏
2:主从
搭建过程:
1、复制一个redis-6380.conf 2、修改配置 3:修改端口 port 6380 4::修改pid pidfile /var/run/redis_6380.pid 5: 修改log file 名称: logfile “6380.log” 6: 修改dir 路径 数据的存放目录 dir /usr/local/redis-5.0.3/data/6380 7: 注释 bing 127.0.0.1 8:配置主从普复制 replicaof ip port replica-read-only yes # 从节点配置只读 9:启动从节点 redis-server redis-6380.conf
不管slave是否是第一次都会发送psync命令给master
1:slave 想master 发送psync
2: master通过bgsave生成rdb,
3: master 生成rdb期间的数据放在repl buffer
4: master 把 rdb发给slave
5:save把rdb加载到内存
6: maste 把repl buffer 发给slave
如果是端口重连,master会受到多次请求,但只会合并发送一次持久化
主从复制流程图
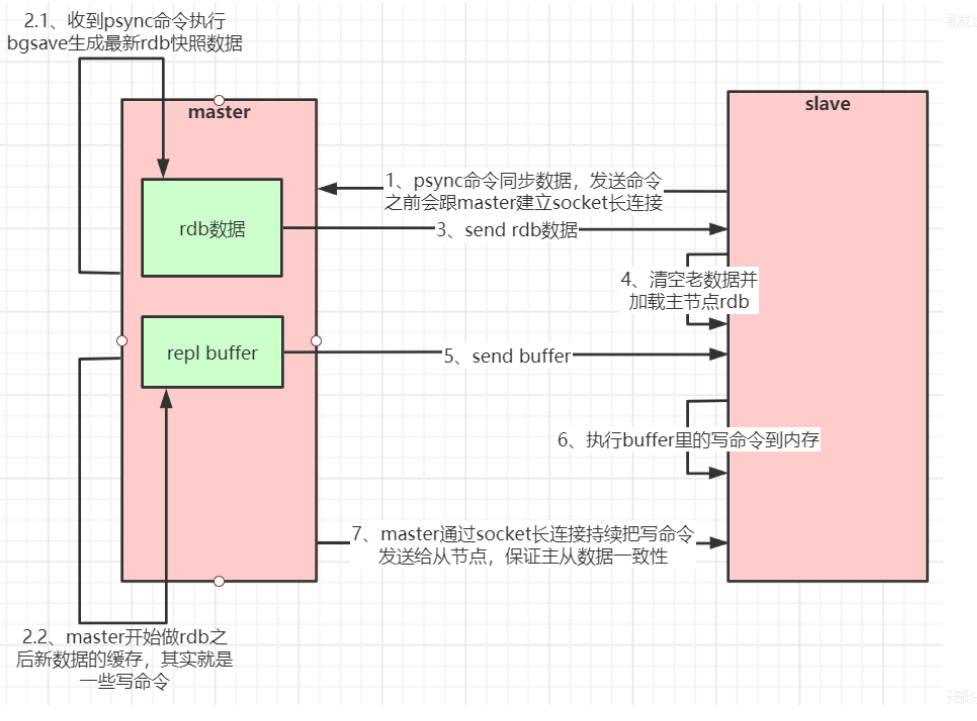
数据恢复
1:slave 会发送psync(offset)
2: master就判断这个offset是否在 repl blacklog buff 中
3: 如果不在,就类似第一次链接,全量同步
4:如果在,就从offset位置发送后面的数据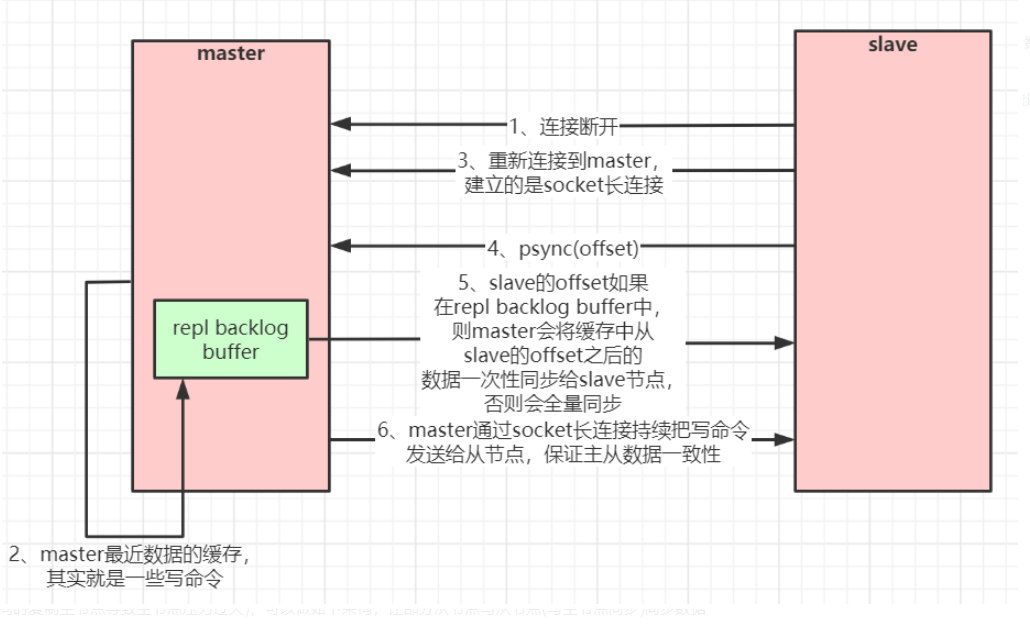
主从复制风暴:
一主多从,主节点压力就会过大,可以让从节点从从节点中读数据
如实: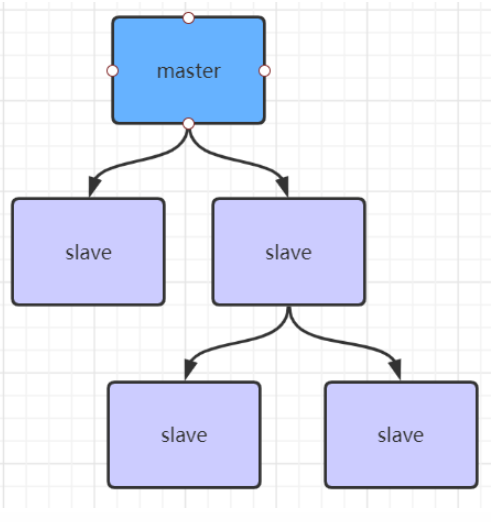
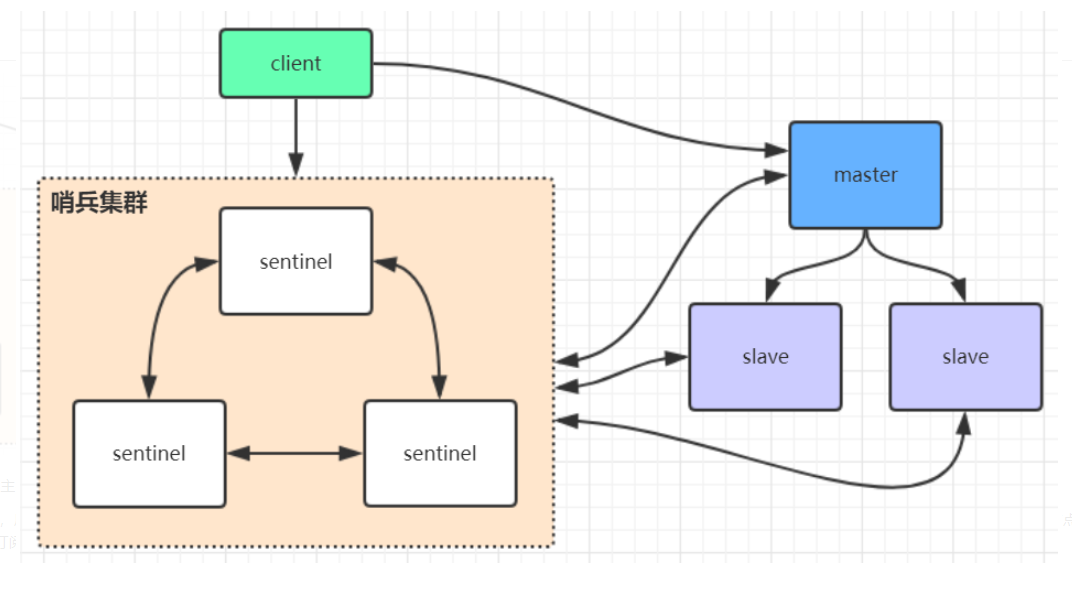
3:哨兵
sentine哨兵不提供服务只是监控示例数据
client会第一次从哨兵找master ,后续就访问master 不在通过sentinel了
master发生变化后,哨兵会选出新的master 告诉client
涉及订阅模式,client订阅sentinel发布的节点变动消息
哨兵搭建步骤
1:复制sentinel.conf文件 cp sentinel.conf sentinel-26379.conf 2:修改端口号 port 26379 daemonize yes pidfile “/var/run/redis-sentinel-26379.pid” logfile “26379.log” dir “/usr/local/redis-5.0.3/data”
quorum是一个数字,指明当有多少个sentinel认为一个master失效时(值一般为:sentinel总数/2 + 1),
master才算真正失效 sentinel monitor mymaster 192.168.0.60 6379 2 # mymaster这个名字随便取,客户端访问时会用到 3:启动 src/redis-sentinel sentinel-26379.conf
4: 依次在配置两台sentinel 端口26380 ,26381
哨兵集群启动后 哨兵信息会被写入conf中
信息如下:
sentinel known-replica mymaster 192.168.0.60 6380 #代表redis主节点的从节点信息sentinel known-replica mymaster 192.168.0.60 6381 #代表redis主节点的从节点信息sentinel known-sentinel mymaster 192.168.0.60 26380 52d0a5d70c1f90475b4fc03b6ce7c3c56935760f #代表感知到的其它哨兵节点sentinel known-sentinel mymaster 192.168.0.60 26381 e9f530d3882f8043f76ebb8e1686438ba8bd5ca6 #代表感知到的其它哨兵节点
4:jedis使用
1:引入依赖:
<dependency><groupId>redis.clients</groupId><artifactId>jedis</artifactId><version>2.9.0</version></dependency>
2:代码
public class JedisSingleTest {public static void main(String[] args) throws IOException {JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();jedisPoolConfig.setMaxTotal(20);jedisPoolConfig.setMaxIdle(10);jedisPoolConfig.setMinIdle(5);// timeout,这里既是连接超时又是读写超时,从Jedis 2.8开始有区分connectionTimeout和soTimeout的构造函数JedisPool jedisPool = new JedisPool(jedisPoolConfig, "192.168.0.60", 6379, 3000, null);Jedis jedis = null;try {//从redis连接池里拿出一个连接执行命令jedis = jedisPool.getResource();System.out.println(jedis.set("single", "zhuge"));System.out.println(jedis.get("single"));//管道示例//管道的命令执行方式:cat redis.txt | redis-cli -h 127.0.0.1 -a password - p 6379 --pipe/*Pipeline pl = jedis.pipelined();for (int i = 0; i < 10; i++) {pl.incr("pipelineKey");pl.set("zhuge" + i, "zhuge");}List<Object> results = pl.syncAndReturnAll();System.out.println(results);*///lua脚本模拟一个商品减库存的原子操作//lua脚本命令执行方式:redis-cli --eval /tmp/test.lua , 10/*jedis.set("product_count_10016", "15"); //初始化商品10016的库存String script = " local count = redis.call('get', KEYS[1]) " +" local a = tonumber(count) " +" local b = tonumber(ARGV[1]) " +" if a >= b then " +" redis.call('set', KEYS[1], a-b) " +" return 1 " +" end " +" return 0 ";Object obj = jedis.eval(script, Arrays.asList("product_count_10016"), Arrays.asList("10"));System.out.println(obj);*/} catch (Exception e) {e.printStackTrace();} finally {//注意这里不是关闭连接,在JedisPool模式下,Jedis会被归还给资源池。if (jedis != null)jedis.close();}}}
管道pipeline
管道中一个命令失败不影响其他名称,无事务
Lua脚本事务
5:StringRedisTemplate& RedisTemplate使用
StringRedisTemplate
spring封装的,支持的是redis原生SQL
继承自RedisTemplate
默认采用Strring序列化策略,保存的key value
常用接口
private ValueOperations<K, V> valueOps;private HashOperations<K, V> hashOps;private ListOperations<K, V> listOps;private SetOperations<K, V> setOps;private ZSetOperations<K, V> zSetOps
RedisTemplate
默认是JDK的序列化策略
Redis客户端命令对应的RedisTemplate中的方法列表:
| String类型结构 | |
|---|---|
| Redis | RedisTemplate rt |
| set key value | rt.opsForValue().set(“key”,”value”) |
| get key | rt.opsForValue().get(“key”) |
| del key | rt.delete(“key”) |
| strlen key | rt.opsForValue().size(“key”) |
| getset key value | rt.opsForValue().getAndSet(“key”,”value”) |
| getrange key start end | rt.opsForValue().get(“key”,start,end) |
| append key value | rt.opsForValue().append(“key”,”value”) |
| Hash结构 | |
| hmset key field1 value1 field2 value2… | rt.opsForHash().putAll(“key”,map) //map是一个集合对象 |
| hset key field value | rt.opsForHash().put(“key”,”field”,”value”) |
| hexists key field | rt.opsForHash().hasKey(“key”,”field”) |
| hgetall key | rt.opsForHash().entries(“key”) //返回Map对象 |
| hvals key | rt.opsForHash().values(“key”) //返回List对象 |
| hkeys key | rt.opsForHash().keys(“key”) //返回List对象 |
| hmget key field1 field2… | rt.opsForHash().multiGet(“key”,keyList) |
| hsetnx key field value | rt.opsForHash().putIfAbsent(“key”,”field”,”value” |
| hdel key field1 field2 | rt.opsForHash().delete(“key”,”field1”,”field2”) |
| hget key field | rt.opsForHash().get(“key”,”field”) |
| List结构 | |
| lpush list node1 node2 node3… | rt.opsForList().leftPush(“list”,”node”) |
| rt.opsForList().leftPushAll(“list”,list) //list是集合对象 | |
| rpush list node1 node2 node3… | rt.opsForList().rightPush(“list”,”node”) |
| rt.opsForList().rightPushAll(“list”,list) //list是集合对象 | |
| lindex key index | rt.opsForList().index(“list”, index) |
| llen key | rt.opsForList().size(“key”) |
| lpop key | rt.opsForList().leftPop(“key”) |
| rpop key | rt.opsForList().rightPop(“key”) |
| lpushx list node | rt.opsForList().leftPushIfPresent(“list”,”node”) |
| rpushx list node | rt.opsForList().rightPushIfPresent(“list”,”node”) |
| lrange list start end | rt.opsForList().range(“list”,start,end) |
| lrem list count value | rt.opsForList().remove(“list”,count,”value”) |
| lset key index value | rt.opsForList().set(“list”,index,”value”) |
| Set结构 | |
| sadd key member1 member2… | rt.boundSetOps(“key”).add(“member1”,”member2”,…) |
| rt.opsForSet().add(“key”, set) //set是一个集合对象 | |
| scard key | rt.opsForSet().size(“key”) |
| sidff key1 key2 | rt.opsForSet().difference(“key1”,”key2”) //返回一个集合对象 |
| sinter key1 key2 | rt.opsForSet().intersect(“key1”,”key2”)//同上 |
| sunion key1 key2 | rt.opsForSet().union(“key1”,”key2”)//同上 |
| sdiffstore des key1 key2 | rt.opsForSet().differenceAndStore(“key1”,”key2”,”des”) |
| sinter des key1 key2 | rt.opsForSet().intersectAndStore(“key1”,”key2”,”des”) |
| sunionstore des key1 key2 | rt.opsForSet().unionAndStore(“key1”,”key2”,”des”) |
| sismember key member | rt.opsForSet().isMember(“key”,”member”) |
| smembers key | rt.opsForSet().members(“key”) |
| spop key | rt.opsForSet().pop(“key”) |
| srandmember key count | rt.opsForSet().randomMember(“key”,count) |
| srem key member1 member2… | rt.opsForSet().remove(“key”,”member1”,”member2”,…) |

若有收获,就点个赞吧
0 人点赞
