
发送者
ack参数
0:啥都不管,发出去就好了
1:消息持久化到磁盘,返回确认
-1/all:发到leader,所有副本都同步成功
不是全部,可以配置的 min.insync.replicas
重试参数
retries_config:
存在的问题,重复发送的问题,消费端保证幂等即可
重试间隔:
批量发送参数
buffer.memory :先发到缓存区,然后在发到网络
默认32M,
linger:默认10ms,就是buffer没满,也会发送
消费端:
指定的broker列表
消费组名称
自动提交
同步提交
异步提交
序列化器
定义主题
指定分区消费
回溯消费
指定offset消费
指定时间点消费
消费之前一个小时的消息
consumer.offsetForTime()
都是先根据时间找到偏移量,再根据偏移量去消费
依赖底层的时间日志*.timeindex文件
**.index
*.log
三个文件
日志分段存储
log.segment.bytes:指定一个文件的大小,
最大1GB,
三个文件
.index
.log
.timeindex
log:顺序文件
index:索引文件,索引位置,每4k,会放顺序文件的offset值,指针,稀疏索引
timeindex: 存时间点,偏移量,也是稀疏索引
max.poll.records:
一次最大拉取多少条
max_poll_interval_ms_config
如果两次poll消费的时间间隔大于这个参数,这个消费组会任务处理能力弱,会被踢掉的
心跳时间间隔
heartbeat interval 心跳包活的
session timeout 超时也会把consumer剔除,
AUTO_OFFSET_REST_COFIG
针对新加入消费组的,是否消费老的消费
latest,针对新消费组消费
earliest:新消费组,会从头消费
设计原理:
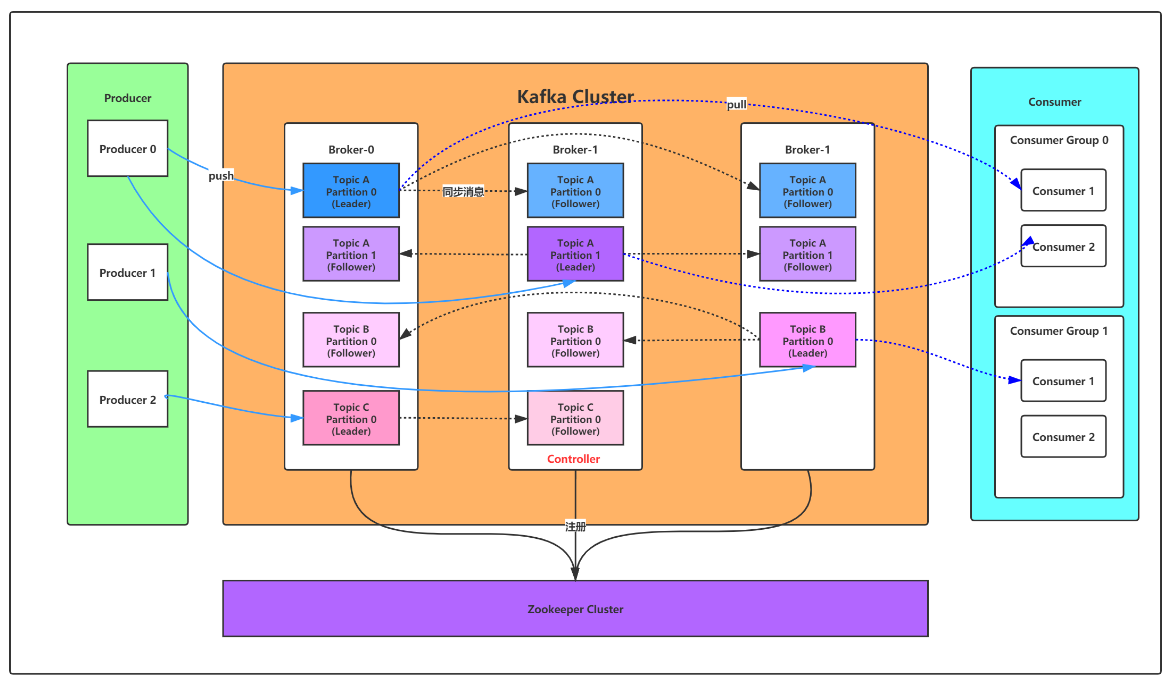
总控制器,controller
选举一个broker充当,只是负责管理集群所有分区和副本状态的
只有一个,类似broker负责broker之间的通信,
依赖的是zk的临时结点,对同一把锁的加锁
职责:
- 监听broker的变化,
- 监听topic的变化
- 从zk获取所有topic,partitions以及broker相关信息
- 更新集群元数据信息,同步到其他broker
partitions的副本选举leader选举机制
controller 知道分区的leader挂了,
就会从ISR中选取第一个broker作为leader,:因为第一个可能同步数据最多
通过zk watcher监听,更新irs列表中的broker
irs机器:
unclean.leader.election: true 从isr列表中选对应的broker作为
副本进图ISR的条件
- 副本结点不能产生分区,必须与zk保持回话
- 副本能复制leader上所有写操作,但不能落后太多
消费消息的offset记录机制
每个consumer会定期把自己消费分区的offset提交给一个内存topic : comsuer_offsets
key:consumerGroupId+topic+ 分区号
value:offset值
kafka会定期清除topic的信息,因为有用的就是最新的一条
_consumer_offsets默认给50个分区,抵抗大并发
可以算出offset提交到了哪个分区:
hash(consumerGroupId) % __consumer_offsets主题的分区数

若有收获,就点个赞吧
0 人点赞
