高可用集群模式
特性:
复制,高可用,分片
无中心,可水平扩展,(不超过1000个)
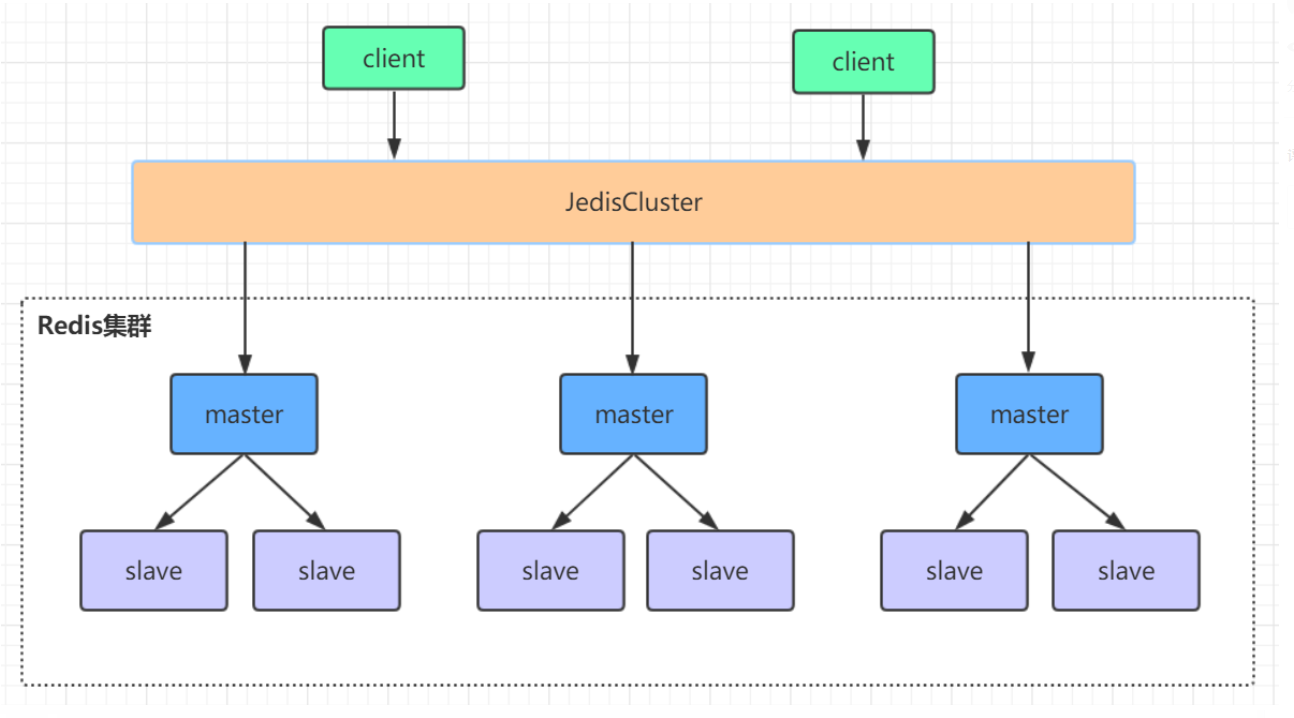
高可用集群的搭建
集群需要至少三个master ,一住一从
搭建步骤:
1 : 创建一个redis_cluster目录 2: 在分别建对应端口的目录 8001 8002 8003 …. 3: 把redis-conf ,分别复制到对应的目录中 4:修改redis.conf (1)daemonize yes (2)port 8001 不同文件不同端口 (3)pidfile /var/run/redis_8001.pid # 把pid进程号写入pidfile配置的文件 (4)dir /usr/local/redis-cluster/8001/(指定数据文件存放位置,必须要指定不同的目录位置,不然会丢失数据) (5)cluster-enabled yes(启动集群模式) (6)cluster-config-file nodes-8001.conf(集群节点信息文件,这里800x最好和port对应上) (7)cluster-node-timeout 10000 (8)# bind 127.0.0.1(bind绑定的是自己机器网卡的ip,如果有多块网卡可以配多个ip,代表允许客户端通过机器的哪些网卡ip去访问,内网一般可以不配置bind,注释掉即可) (9)protected-mode no (关闭保护模式) (10)appendonly yes 如果要设置密码需要增加如下配置: (11)requirepass zhuge (设置redis访问密码) (12)masterauth zhuge (设置集群节点间访问密码,跟上面一致) 其他redis.conf 配置对应的端口即可 vim 命令: :%s/源字符串/目的字符串/g 字符串替换 5: 分别都启动这个六个示例 src/redis-server /8001/redis.cof 其他端口同样方式启动 6: redis-cli f方式创建集群
下面命令里的1代表为每个创建的主服务器节点创建一个从服务器节点
要确定不同机器是否鞥呢相互访问,
systemctl stop firewalld # 临时关闭防火墙
systemctl disable firewalld # 禁止开机启动
/usr/local/redis-5.0.3/src/redis-cli -a wyx—cluster create —cluster-replicas 1 127.0.0.1:8001 127.0.0.1:8002 ……………… 7: 验证: ./redis-cli -c -h -p (-a访问服务端密码,-c表示集群模式,指定ip地址和端口号) 访问任意一个端口即可 关闭集群需要逐个关闭 redis-cli -a wyx -c -p 8001 shutdown 依次关闭其他端口实例
Java操作redis集群
jedis
<dependency><groupId>redis.clients</groupId><artifactId>jedis</artifactId><version>2.9.0</version></dependency>
jedis代码
public class JedisClusterTest {public static void main(String[] args) throws IOException {JedisPoolConfig config = new JedisPoolConfig();config.setMaxTotal(20);config.setMaxIdle(10);config.setMinIdle(5);Set<HostAndPort> jedisClusterNode = new HashSet<HostAndPort>();jedisClusterNode.add(new HostAndPort("192.168.0.61", 8001));jedisClusterNode.add(new HostAndPort("192.168.0.62", 8002));jedisClusterNode.add(new HostAndPort("192.168.0.63", 8003));jedisClusterNode.add(new HostAndPort("192.168.0.61", 8004));jedisClusterNode.add(new HostAndPort("192.168.0.62", 8005));jedisClusterNode.add(new HostAndPort("192.168.0.63", 8006));JedisCluster jedisCluster = null;try {//connectionTimeout:指的是连接一个url的连接等待时间//soTimeout:指的是连接上一个url,获取response的返回等待时间jedisCluster = new JedisCluster(jedisClusterNode, 6000, 5000, 10, "zhuge", config);System.out.println(jedisCluster.set("test", "value"));System.out.println(jedisCluster.get("test"));} catch (Exception e) {e.printStackTrace();} finally {if (jedisCluster != null)jedisCluster.close();}}}
Spring Boot整合
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId></dependency><dependency><groupId>org.apache.commons</groupId><artifactId>commons-pool2</artifactId></dependency>
配置文件
server:port: 8080spring:redis:database: 0timeout: 3000password: zhugecluster:nodes: 192.168.0.61:8001,192.168.0.62:8002,192.168.0.63:8003,192.168.0.61:8004,192.168.0.62:8005,192.168.0.63:8006lettuce:pool:max-idle: 50min-idle: 10max-active: 100max-wait: 1000
代码示例
@RestControllerpublic class RedisController {private static final Logger logger = LoggerFactory.getLogger(RedisController.class);@Autowiredprivate StringRedisTemplate stringRedisTemplate;@RequestMapping("/test_cluster")public void testCluster() throws InterruptedException {stringRedisTemplate.opsForValue().set("test", "666");System.out.println(stringRedisTemplate.opsForValue().get("test"));}}
Redis集群原理分析
redis cluster 一共16384个slots 槽位
redis cluster 客户端会缓存一份集群的槽位配置信息
保存时先根据key hasd到对应的槽位,确定槽位对应服务器
槽位定位算法
HASH_SLOT = CRC16(key) mod 16384 得到一个整数曹位数
跳转重定位:
在当前节点执行命令,计算的槽位不在当前节点
就会向客户端发送一个跳转指令到目标节点地址
还会同步风险本地槽位映射表缓存
Redis集群节点间的通信机制
redis cluster节点间采取gossip协议进行通信
集中式:
gossip
gossip协议包含多种消息,包括ping,pong,meet,fail等等。
meet:某个节点发送meet给新加入的节点,让新节点加入集群中,然后新节点就会开始与其他节点进行通信;
ping:每个节点都会频繁给其他节点发送ping,其中包含自己的状态还有自己维护的集群元数据,互相通过ping交换元数据(类似自己感知到的集群节点增加和移除,hash slot信息等);
pong: 对ping和meet消息的返回,包含自己的状态和其他信息,也可以用于信息广播和更新;
fail: 某个节点判断另一个节点fail之后,就发送fail给其他节点,通知其他节点,指定的节点宕机了。
Redis集群选举原理分析
- 主节点挂了,
- slave 会想其他master 广播
- 其他master手动广播给出ack
- 超过半数,slave就升级成master
- salve把成为master广播给其他
slave不会再masterfail后就发起选择
有个延迟计算
DELAY = 500ms + random(0 ~ 500ms) + SLAVE_RANK * 1000ms
•SLAVE_RANK表示此slave已经从master复制数据的总量的rank。Rank越小代表已复制的数据越新。
方便最新slave被选上
集群脑裂数据丢失问题
min-replicas-to-write 1 # 就是在写入是至少有一个slave也写入才算成功
集群是否完整才能对外提供服务
redis.conf cluster-require-full-coverage为no,就是有一个节点挂了还替补提供对外服务
当redis.conf的配置cluster-require-full-coverage为no时,表示当负责一个插槽的主库下线且没有相应的从库进行故障恢复时,集群仍然可用,如果为yes则集群不可用。

若有收获,就点个赞吧
0 人点赞
