数据结构
由 Segment数组 + HashEntry 数组 构成 HashEntry 存键值对
一个concurrentHashMap 饱和Segment数组
一个Segmengt包含一个HashEntry数组
一个HashEntry元素是一个链表
锁的获取时在 segment 上的竞争
图示: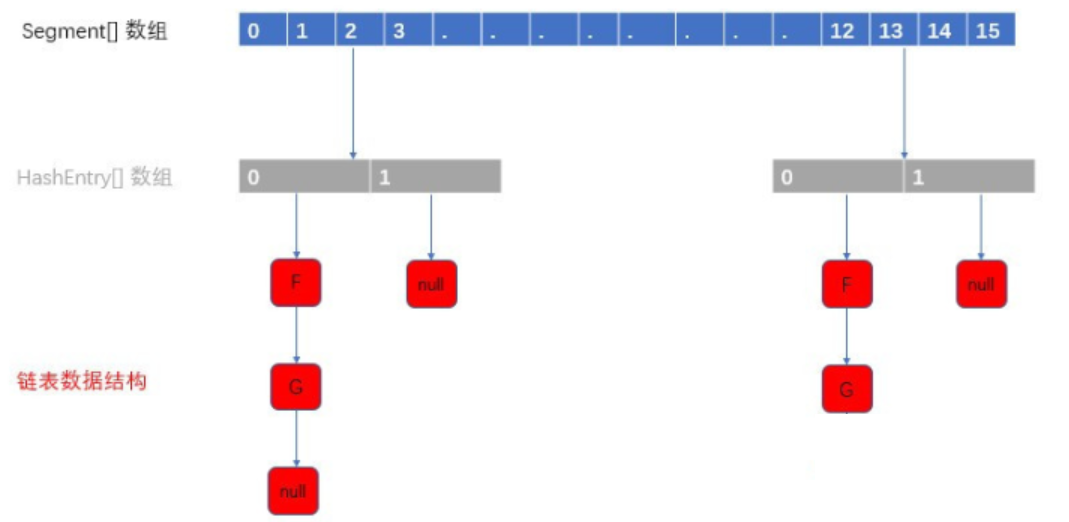
HashEntry
static final class HashEntry<K,V> {final int hash;final K key;volatile V value;volatile HashEntry<K,V> next;HashEntry(int hash, K key, V value, HashEntry<K,V> next) {this.hash = hash;this.key = key;this.value = value;this.next = next;}
put操作
public V put(K key, V value) {Segment<K,V> s;if (value == null)throw new NullPointerException();int hash = hash(key);// 通过位运算确定哪个segment,int j = (hash >>> segmentShift) & segmentMask;// 通过unsafe 获取if ((s = (Segment<K,V>)UNSAFE.getObject(segments, (j << SSHIFT) + SBASE)) == null)s = ensureSegment(j);//初始化一个segment//调用Segment的put方法return s.put(key, hash, value, false);}
- 先算hash
- 确定segment的下表
-
Segment的put方法
```java final V put(K key, int hash, V value, boolean onlyIfAbsent) { //对segment加锁 HashEntry
scanAndLockForPut(key, hash, value);
V oldValue; try {
//HashEntry<K,V>[] tab = table;int index = (tab.length - 1) & hash;//获取头结点HashEntry<K,V> first = entryAt(tab, index);for (HashEntry<K,V> e = first;;) {//开始遍历first为头结点的链表if (e != null) {//<1>////依据onlyIfAbsent来判断是否覆盖已有的value值K k;if ((k = e.key) == key ||(e.hash == hash && key.equals(k))) {oldValue = e.value;if (!onlyIfAbsent) {e.value = value;++modCount;}break;}e = e.next;//说明当前e节点对应的key不是需要的}else {//头插法if (node != null)node.setNext(first);elsenode = new HashEntry<K,V>(hash, key, value, first);int c = count + 1;if (c > threshold && tab.length < MAXIMUM_CAPACITY)//判断是否需要进行扩容//扩容,node插入到新的数组中。rehash(node);elsesetEntryAt(tab, index, node);++modCount;count = c;oldValue = null;break;}}
} finally {
unlock();
} return oldValue; }
```
- 先获取segment的锁
- 找到k所在HashEntry 数组的下表
- 获取这个HashEntry 的头节点
- 开始遍历
- 采用头插法

若有收获,就点个赞吧
0 人点赞
