一:基础概念
1:消息模型(Message Model)
Producer:生产消息
Consumer:消费消息
Broker:对应实际部署的一一台服务器
每个broker可以存多个topic的消息,
Topic:同一个topic消息可以分片到不同的Broker
每个topic可以存多个Message Queue
MessageQueue:存储消息的物理地址
ConsumerGroup:有多个Consumer实例组成
2:生产者 producer
一个生产者,会把一个消息发送到一个broker的 MessageQueue中
会把同一topic的消息发给不用的broker, 也可能会在同一个broker的不同MessageQueue中
发送方式:
- 同步 需要broker返回确认消息,不是消费者
- 异步 需要borker返回确认消息,不是消费者
- 顺序
- 单向
生产者组,同一类producer具有同样的发送方式
可以回溯消息
3:消费者Consumer
消费模式
- 拉取
consumer从broker服务器拉取消息的方式 - 推动
broker收到消息后主动推消费者,实时性较高
消费者组,同一个消费逻辑,实现负责均衡
消费者组示例需要订阅完全相同的topic
消息模式:
- 集群消息
相同的consumer group 每个consumer实例平均分摊消息 - 广播消息
相同consumer group 每个consumer实例接受全量的消息4:主题topic
表示一类消息集合,订阅基本单位
同一个topic会分片到不同的broker上
每一个分片单位:messagequeue
5 :代理服务器 brokerServer
消息中转角色
负责消息存储,转发,
存储消息相关的元数据,包括消费者组,消费进度偏移,主题和队列消息等
核心业务
包括的子模块
- Remoting Module:Broker实体,负责处理client的请求
- Client Manager:管理客户端和维护consumer的topic定义信息
- Store Service:提供api接口处理消息存储到硬盘的查询功能
- HA Serice:高可用服务,主从的同步功能
- Index Serive :根据特定messageKey对投递到broker消息进行索引服务,方便查询用的
集群架构模式:
- 主从模式
master负责响应客户端请求,存储消息
slave负责同步保持消息,并响应读请求,同步方式可分为同步,异步
无法做法主从切换 - Dledger高可用集群
4.5引入,可以实现主动切换
技术点:
1:接管broker的commitLog消息存储
2:从集群选举master
3:完成master到slave的消息同步Dledger集群模式
Raft算法选举节点
Raft选举算法:
1:每个节点三个状态
leader:处理客户端所有请求,
follower:只响应leader和candidate的请求,或转发客户端请求给leader
candidate
2:启动时:每个节点都是follower
集群发送timerout信号,
follower会变成candidate拉选票
大多数票数的会成为leader
leader会向其他节点发送心跳确认leader
3:启动定时器
如果指定的时间内没收到leader心跳,会转为candidate,
Raft协议会把任意时间长度的时间分片 term会递增,起到逻辑时钟的作用
6:NameServer
充当路由消息的提供者,
每个broker会向所有NameServer注册自己的服务信息,通过心跳维持实时性
生产者或消费者通过名字服务找对应主题对应的brokerIP列表
多个NameServer实例是独立的,没有信息交换
如果一台NameServer挂了,只要有一台就能用、
7:消息
最小单位,拥有唯一Id ,可以携带key 方便查询
带有tag标识区分同一主题下不同类型消息
详细见: docs/cn/best_practice.md 源码
二:消息存储
1:何时存
持久化的存储时机
- MQ收到一条,需要想生产者返回一个ACK,并存储
- MQpush一个消息给consumer 等待consumer ack响应,如果没有响应,会尝试继续推送
- 定期删一些过期消息
2:消息存储介质
类似kafka文件存储机制,
顺序写:2:零拷贝
加速文件的读写
文件映射,
Mmap映射的方式
固定一个commitlog的文件大小
3:存储的数据结构
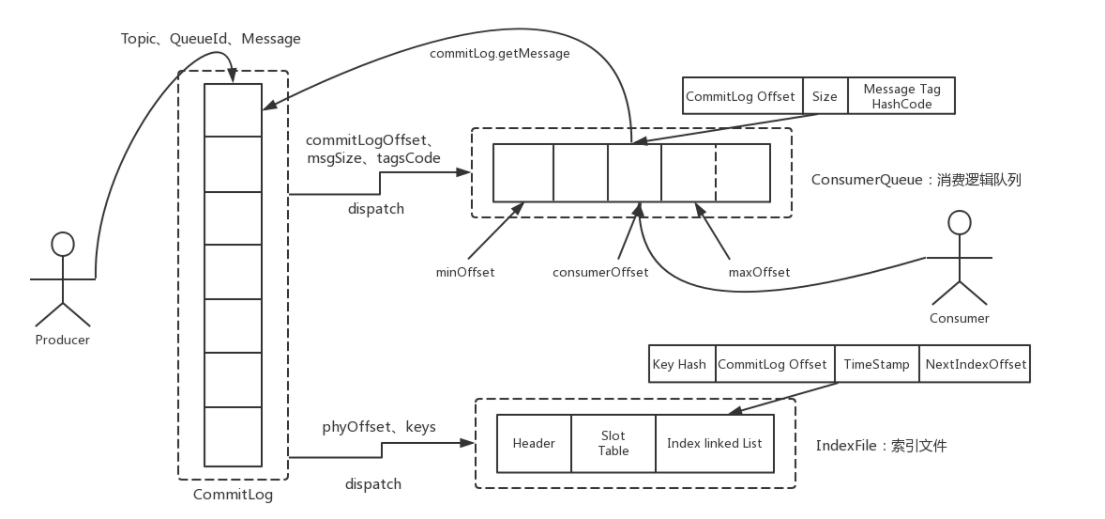
commitlog 文件:所有发过来的消息,
consumerQueue:消费逻辑的队列
只存索引,在commitLog的位置,offset,还有message tag的索引
区分索引的方式
对应store/config路径下的json文件,的存储,控制台的数据来源
IndexFile:s索引文件:
在consumerQUeu的基础上提供更多的索引查询的文件
timeStamp key hash ,消息的偏移量,
abort文件:是否正常关闭的标识文件
checkpoint:
同步刷盘:
主从同步的问题,
同步刷盘,异步刷盘
在不同的配置文件区分的
区别:性能,吞吐量,安全问题
4:刷盘机制
把消息存储在磁盘上
- 同步
消息被吸入内存的pagecache后就通知刷盘,刷成功后唤醒等待线程返回成状态 - 异步
消息被写入内存pagecache就算成功了,只有内存到一定数量,才会触发刷盘
通过Broker配置文件里的flushDiskType 参数设置的,这个参数被配置成SYNC_FLUSH、ASYNC_FLUSH中的 一个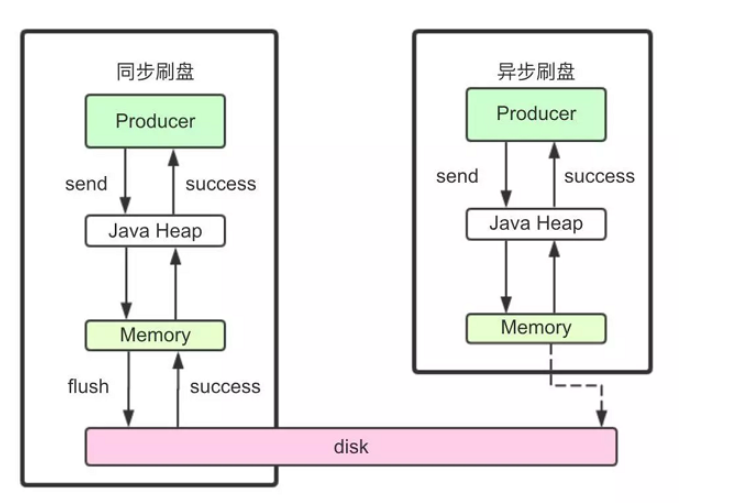
5:主从复制
- 同步复制
主从都写入才返回客户端状态 - 异步复制
master成功就算成功了,异步同步
通过Broker配置文件里的brokerRole参数进行设置的,这个参数可以被设置成ASYNC_MASTER、 SYNC_MASTER、SLAVE三个值中的一个
6:负载均衡
Producer负载均衡
默认轮询:依次发给不同的broker的messagequeue ,
也可以指定MessageQueueSelector 发给指定的MessageQueue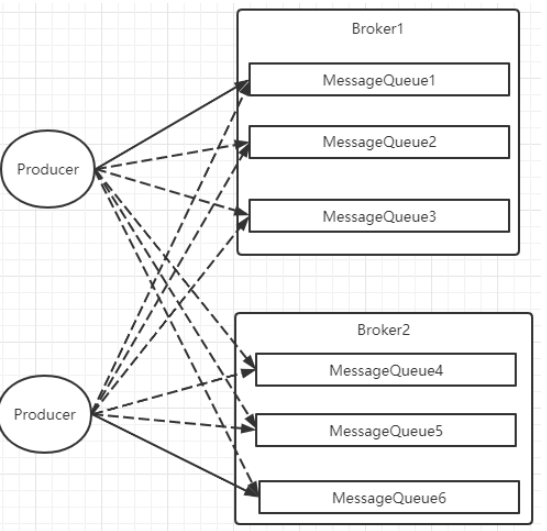
Consumer负载均衡
广播:
集群:
会采用主动拉取的方式
订阅模式
把messageQueue与consumer绑定,完成订阅
把Broker与consumer绑定,分配
分配策略:AllocateMessageQueueStrategy
AllocateMachineRoomNearby: 将同机房的Consumer和Broker优先分配在一起。
AllocateMessageQueueAveragely:平均分配。将所有MessageQueue平均分给每一个消费者
AllocateMessageQueueAveragelyByCircle: 轮询分配。轮流的给一个消费者分配一个MessageQueue。
AllocateMessageQueueByConfig: 不分配,直接指定一个messageQueue列表。类似于广播模式
,直接指定所有队列。
AllocateMessageQueueByMachineRoom:按逻辑机房的概念进行分配。又是对BrokerName和ConsumerIdc有定制化的配置。
AllocateMessageQueueConsistentHash。源码中有测试代码AllocateMessageQueueConsitentHashTest。这个一致性哈希策略只需要指定一个虚拟节点数,是用的一个哈希环的算法,虚拟节点是为了让Hash数据在换上分布更为均匀。
7:消息重试
三种方式:
- 返回Action.ReconsumeLater-推荐
- 返回null
- 抛出异常
public class MessageListenerImpl implements MessageListener {@Overridepublic Action consume(Message message, ConsumeContext context) {//处理消息doConsumeMessage(message);//方式1:返回 Action.ReconsumeLater,消息将重试return Action.ReconsumeLater;//方式2:返回 null,消息将重试return null;//方式3:直接抛出异常, 消息将重试throw new RuntimeException("Consumer Message exceotion");}}
创建重试队列public class MessageListenerImpl implements MessageListener {@Overridepublic Action consume(Message message, ConsumeContext context) {try {doConsumeMessage(message);} catch (Throwable e) {//捕获消费逻辑中的所有异常,并返回 Action.CommitMessage;return Action.CommitMessage;}//消息处理正常,直接返回 Action.CommitMessage;return Action.CommitMessage;}}
给每个消费者组,创建重试消费队列
默认16次,16个级别,
重试之后超过16次,会进去死信队列
| 重试次数 | 与上次重试的间隔时间 | 重试次数 | 与上次重试的间隔时间 |
|---|---|---|---|
| 1 | 10 秒 | 9 | 7 分钟 |
| 2 | 30 秒 | 10 | 8 分钟 |
| 3 | 1 分钟 | 11 | 9 分钟 |
| 4 | 2 分钟 | 12 | 10 分钟 |
| 5 | 3 分钟 | 13 | 20 分钟 |
| 6 | 4 分钟 | 14 | 30 分钟 |
| 7 | 5 分钟 | 15 | 1 小时 |
| 8 | 6 分钟 | 16 | 2 小时 |
8:死信队列
DLQ::默认创建
默认创建,但是需要人工处理,消息是不可读不可消费的
特征:
- 一个死信队列对应一个consumerGroup,不是某个消费者示例
- 如果一个consumerGroup没有产生死信队列,rocketmq就不会创建对应的死信队列
- 不区分topic
- 不会被消费者消费
- 有效期默认三天,在broker.conf的fileReservedTime配置
9:消费幂等
三种语义
- at most once 最多一次:每条消息最多只会被消费一次
- at least once 至少一次:每条消息至少会被消费一次
- exactly once 刚刚好一次:每条消息都只会确定的消费一次
处理方式:messageId
其他
事务机制,回查次数,间隔
默认回查15次,
源码中的文档
test
源码:

若有收获,就点个赞吧
0 人点赞
