缓存设计
缓存穿透:
就是redis始终查不到,导致每次都越过缓存,去查DB
失去了缓存保护DB的意义
原因
- 代码问题,数据问题
- 恶意攻击
解决方案:
1:缓存空对象
过期时间设置
String get(String key) {// 从缓存中获取数据String cacheValue = cache.get(key);// 缓存为空if (StringUtils.isBlank(cacheValue)) {// 从存储中获取String storageValue = storage.get(key);cache.set(key, storageValue);// 如果存储数据为空, 需要设置一个过期时间(300秒)if (storageValue == null) {cache.expire(key, 60 * 5);}return storageValue;} else {// 缓存非空return cacheValue;}}
2:布隆过滤器
判断一个key是否存在
不能保证一定存在,但一定确定不存在
大型的位数组和多个无篇hash函数
- 把key进行hash运算,得到整数索引,
- 对位数组取模,把对应位置为1
- 同样对其他数组,用不同的hash函数,把其他数组位改成1
判断存在时:
同样把key,经过同样的Hash ,取对应位的数值,是否都是1,
如果有一个0 ,表示不存在
也有可能从都是1, 也不存在
<dependency><groupId>org.redisson</groupId><artifactId>redisson</artifactId><version>3.6.5</version></dependency>
public class RedissonBloomFilter {public static void main(String[] args) {Config config = new Config();config.useSingleServer().setAddress("redis://localhost:6379");//构造RedissonRedissonClient redisson = Redisson.create(config);RBloomFilter<String> bloomFilter = redisson.getBloomFilter("nameList");//初始化布隆过滤器:预计元素为100000000L,误差率为3%,根据这两个参数会计算出底层的bit数组大小bloomFilter.tryInit(100000000L,0.03);//将zhuge插入到布隆过滤器中bloomFilter.add("zhuge");//判断下面号码是否在布隆过滤器中System.out.println(bloomFilter.contains("guojia"));//falseSystem.out.println(bloomFilter.contains("baiqi"));//falseSystem.out.println(bloomFilter.contains("zhuge"));//true}}
//初始化布隆过滤器RBloomFilter<String> bloomFilter = redisson.getBloomFilter("nameList");//初始化布隆过滤器:预计元素为100000000L,误差率为3%bloomFilter.tryInit(100000000L,0.03);//把所有数据存入布隆过滤器void init(){for (String key: keys) {bloomFilter.put(key);}}String get(String key) {// 从布隆过滤器这一级缓存判断下key是否存在Boolean exist = bloomFilter.contains(key);if(!exist){return "";}// 从缓存中获取数据String cacheValue = cache.get(key);// 缓存为空if (StringUtils.isBlank(cacheValue)) {// 从存储中获取String storageValue = storage.get(key);cache.set(key, storageValue);// 如果存储数据为空, 需要设置一个过期时间(300秒)if (storageValue == null) {cache.expire(key, 60 * 5);}return storageValue;} else {// 缓存非空return cacheValue;}}
注意:布隆过滤器不能删除数据,如果要删除得重新初始化数据。
缓存失效(击穿)
缓存同时批量,大量的同时失效导致,可能会造成宕机引发雪崩
解决方案:
设置的一个随机的超时时间,默认时间+ 一个随机数
String get(String key) {// 从缓存中获取数据String cacheValue = cache.get(key);// 缓存为空if (StringUtils.isBlank(cacheValue)) {// 从存储中获取String storageValue = storage.get(key);cache.set(key, storageValue);//在一个基准时间上设置一个时间范围int expireTime = new Random().nextInt(300) + 300;if (storageValue == null) {cache.expire(key, expireTime);}return storageValue;} else {// 缓存非空return cacheValue;}}
缓存雪崩
由一个redis挂了,大量请求到DB,,导致DB挂了,进而影响服务挂了,
解决方案:
保证高可用,集群,主从,哨兵
- 消费降级,控流
- 提前演练
热点缓存key重建优化
- 热点事件导致冷数据变成热点
- 重建缓存时,需要时间计算
解决方案
在实际获取DB数据的地方加上分布式锁
String get(String key) {// 从Redis中获取数据String value = redis.get(key);// 如果value为空, 则开始重构缓存if (value == null) {// 只允许一个线程重建缓存, 使用nx, 并设置过期时间exString mutexKey = "mutext:key:" + key;if (redis.set(mutexKey, "1", "ex 180", "nx")) {// 从数据源获取数据value = db.get(key);// 回写Redis, 并设置过期时间redis.setex(key, timeout, value);// 删除key_mutexredis.delete(mutexKey);}// 其他线程休息50毫秒后重试else {//这个设计很巧妙,值得借鉴Thread.sleep(50);get(key);}}return value;}
缓存数据库双写不一致
双写不一致:
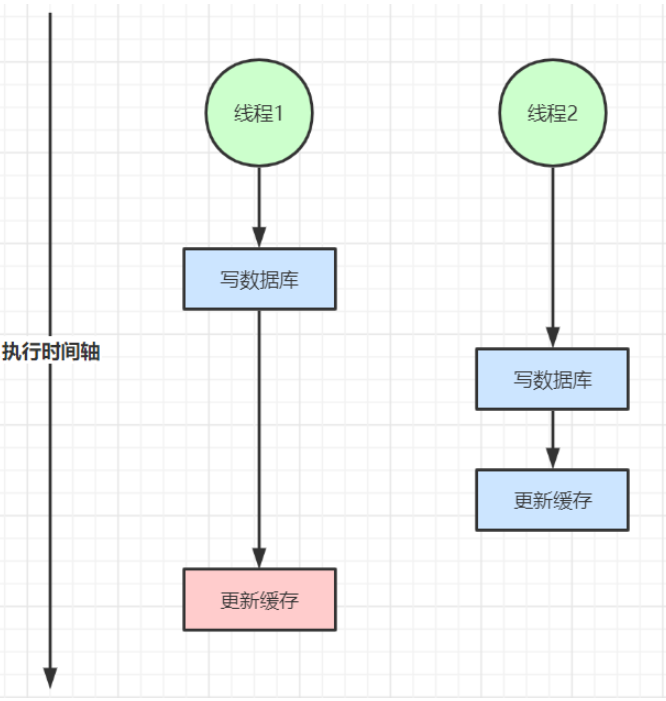
读写不一致
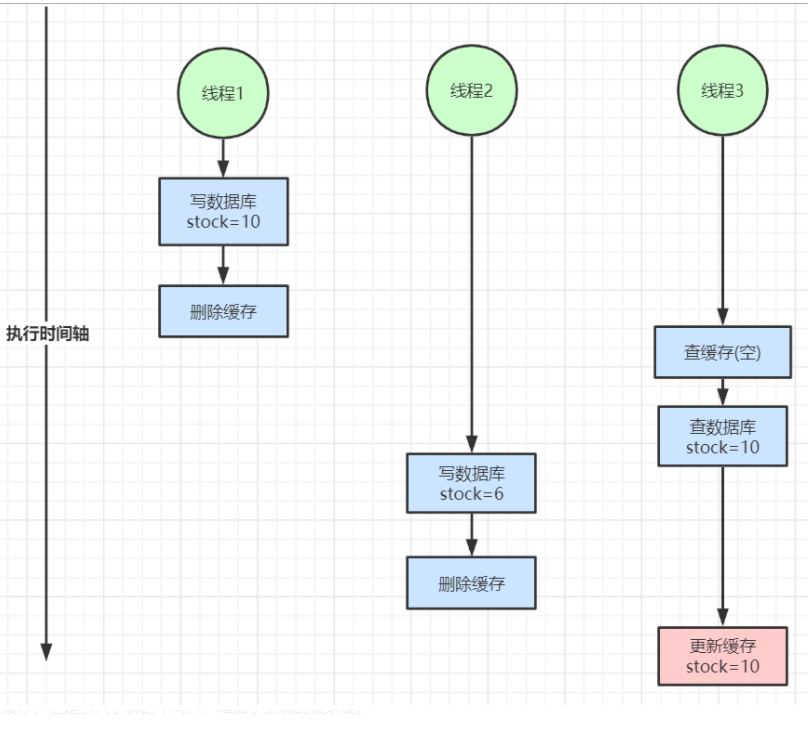
延迟双删
就是删除之后,一段时间后再删一次,没必要
解决方案:
- **无法容忍的不一致数据,库存:分布式锁读写锁
- cannal监听binlog日志,同步缓存
增加了系统复杂度,不太建议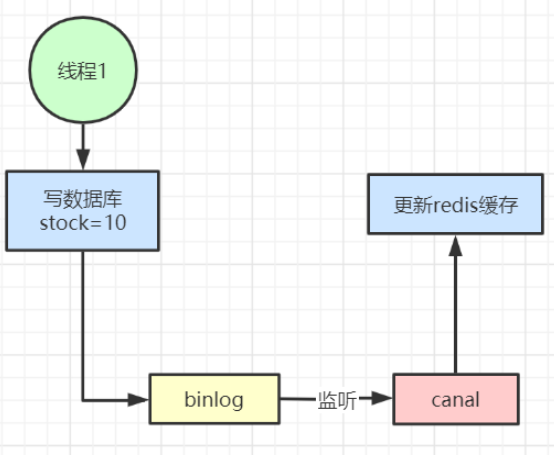
- 个人维度的信息,不太重要的不一致数据,加过期时间,每隔一段时间主动更新即可
- 并发高,但不太敏感的数据不一致,名称,分类,可以加时间,定期更新即可
读多写少:缓存效果好
写多读多: 不建议缓存
不要为了绝对的一致性过度设计和控制,增加系统负责性
开发规范
一:键值设计
1:key名称设计:
- 可读性,可管理性
- 简洁性,不要太长
- 不要包含特殊字符
2: value设计
- 拒绝bigkey,网络问题,慢查询
redis字符串最大可以512M,实际上不要这么干
1:字符串类型:超过10k就算大了
2:集合类型,元素不要超过5000个 - 非字符串bigkey ,不要用del
使用hscan, sscan,zscan 渐进式删除,
防范bigkey过期自动删除的问题,会引起del,造成阻塞
bigkey危害
1:redis阻塞
2:网络拥塞,
3:过期删除
redis4.0要设置过期异步删除否则会阻塞
lazyfree-lazy-expire yes
bigkey的产生
设计不合理导致的
1:社交类,粉丝列表
2:统计类,
3:缓存类,直接序列化放进缓存
优化bigkey
- 拆分
list ,hash - 如果不可拆分
避免每次取出全部,尽量hmget 而不是 hgetall - 合理设计数据类型
比如实体可以放在一个hash中,而不是对每个属性设计一个字符串缓存 - 控制key的生命周期
避免缓存同时失效,
二:命令使用规范
- 【推荐】 O(N)命令关注N的数量
hgetall、lrange、smembers、zrange、sinter等并非不能使用,但是需要明确N的值。有遍历的需求可以使用hscan、sscan、zscan代替。 - 禁用命令
禁止线上使用keys、flushall、flushdb等,通过redis的rename机制禁掉命令,或者使用scan的方式渐进式处理。 - 【推荐】使用批量操作提高效率
原生命令:例如mget、mset。 非原生命令:可以使用pipeline提高效率。 -
三: 客户端使用规范
避免多个应用使用一个Redis实例
- 使用带有连接池的数据库
连接池设计
| 序号 | 参数名 | 含义 | 默认值 | 使用建议 | | —- | —- | —- | —- | —- | | 1 | maxTotal | 资源池中最大连接数 | 8 | 设置建议见下面 | | 2 | maxIdle | 资源池允许最大空闲的连接数 | 8 | 设置建议见下面 | | 3 | minIdle | 资源池确保最少空闲的连接数 | 0 | 设置建议见下面 | | 4 | blockWhenExhausted | 当资源池用尽后,调用者是否要等待。只有当为true时,下面的maxWaitMillis才会生效 | true | 建议使用默认值 | | 5 | maxWaitMillis | 当资源池连接用尽后,调用者的最大等待时间(单位为毫秒) | -1:表示永不超时 | 不建议使用默认值 | | 6 | testOnBorrow | 向资源池借用连接时是否做连接有效性检测(ping),无效连接会被移除 | false | 业务量很大时候建议设置为false(多一次ping的开销)。 | | 7 | testOnReturn | 向资源池归还连接时是否做连接有效性检测(ping),无效连接会被移除 | false | 业务量很大时候建议设置为false(多一次ping的开销)。 | | 8 | jmxEnabled | 是否开启jmx监控,可用于监控 | true | 建议开启,但应用本身也要开启 |
参数:
maxTotal : 最大连接数
nodes(应用个数)* maxTotal 不能超过maxClients**maxIdle和minIdle
最大连接数:给出余量,maxIdle,不要过小,否则会new jedis
最佳 maxTotal = maxIdle 避免连接池伸缩带来的干扰
minIdle:最小空闲连接数,至少需要保持的空闲连接数
**
线程池的预热:
让连接池的空闲链接快速提升到minIdle
List<Jedis> minIdleJedisList = new ArrayList<Jedis>(jedisPoolConfig.getMinIdle());for (int i = 0; i < jedisPoolConfig.getMinIdle(); i++) {Jedis jedis = null;try {jedis = pool.getResource();minIdleJedisList.add(jedis);jedis.ping();} catch (Exception e) {logger.error(e.getMessage(), e);} finally {//注意,这里不能马上close将连接还回连接池,否则最后连接池里只会建立1个连接。。//jedis.close();}}//统一将预热的连接还回连接池for (int i = 0; i < jedisPoolConfig.getMinIdle(); i++) {Jedis jedis = null;try {jedis = minIdleJedisList.get(i);//将连接归还回连接池jedis.close();} catch (Exception e) {logger.error(e.getMessage(), e);} finally {}}
高并发下建议添加熔断功能
合适使用密码
Redis过期策略
- 被动删除:当读写一个已经过期的key时,才去删掉
- 主动删除:定期主动删除已过期的key,只是一批一批的删,不是同时
- 当已用内存超过maxMemory,会触发主动策略
淘汰策略
主动清理策略在Redis 4.0 之前一共实现了 6 种内存淘汰策略,在 4.0 之后,又增加了 2 种策略,总共8种:
a) 针对设置了过期时间的key做处理:
- volatile-ttl:在筛选时,会针对设置了过期时间的键值对,根据过期时间的先后进行删除,越早过期的越先被删除。
- volatile-random:就像它的名称一样,在设置了过期时间的键值对中,进行随机删除。
- volatile-lru:会使用 LRU 算法筛选设置了过期时间的键值对删除。
- volatile-lfu:会使用 LFU 算法筛选设置了过期时间的键值对删除。
b) 针对所有的key做处理:
- allkeys-random:从所有键值对中随机选择并删除数据。
- allkeys-lru:使用 LRU 算法在所有数据中进行筛选删除。
- allkeys-lfu:使用 LFU 算法在所有数据中进行筛选删除。
c) 不处理:
- noeviction:不会剔除任何数据,拒绝所有写入操作并返回客户端错误信息”(error) OOM command not allowed when used memory”,此时Redis只响应读操作。
LRU 算法(Least Recently Used,最近最少使用)
淘汰很久没被访问过的数据,以最近一次访问时间作为参考。
热点数据效果好,
LFU 算法(Least Frequently Used,最不经常使用)
淘汰最近一段时间被访问次数最少的数据,以次数作为参考。
根据自身业务类型,配置好maxmemory-policy(默认是noeviction),推荐使用volatile-lru。如果不设置最大内存,当 Redis 内存超出物理内存限制时,内存的数据会开始和磁盘产生频繁的交换 (swap),会让 Redis 的性能急剧下降。
当Redis运行在主从模式时,只有主结点才会执行过期删除策略,然后把删除操作”del key”同步到从结点删除数据

若有收获,就点个赞吧
0 人点赞
