索引数据结构
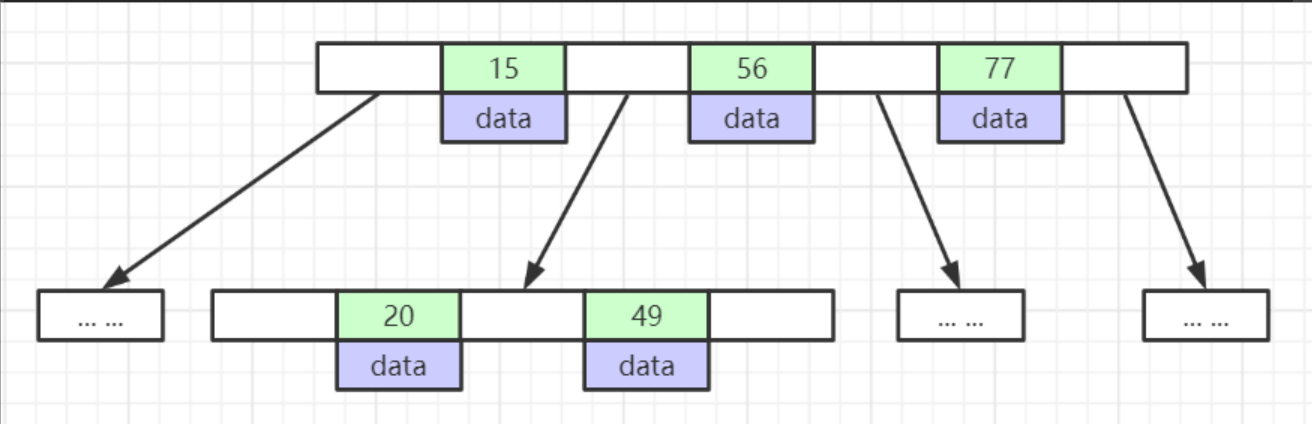
data: key-value结构
B+ 树 (B 树变种)
子节点是排好序的
- 非叶子节点不存储data,只存索引
- 叶子节点包含所有索引字段
- 叶子节点直接用指针链接
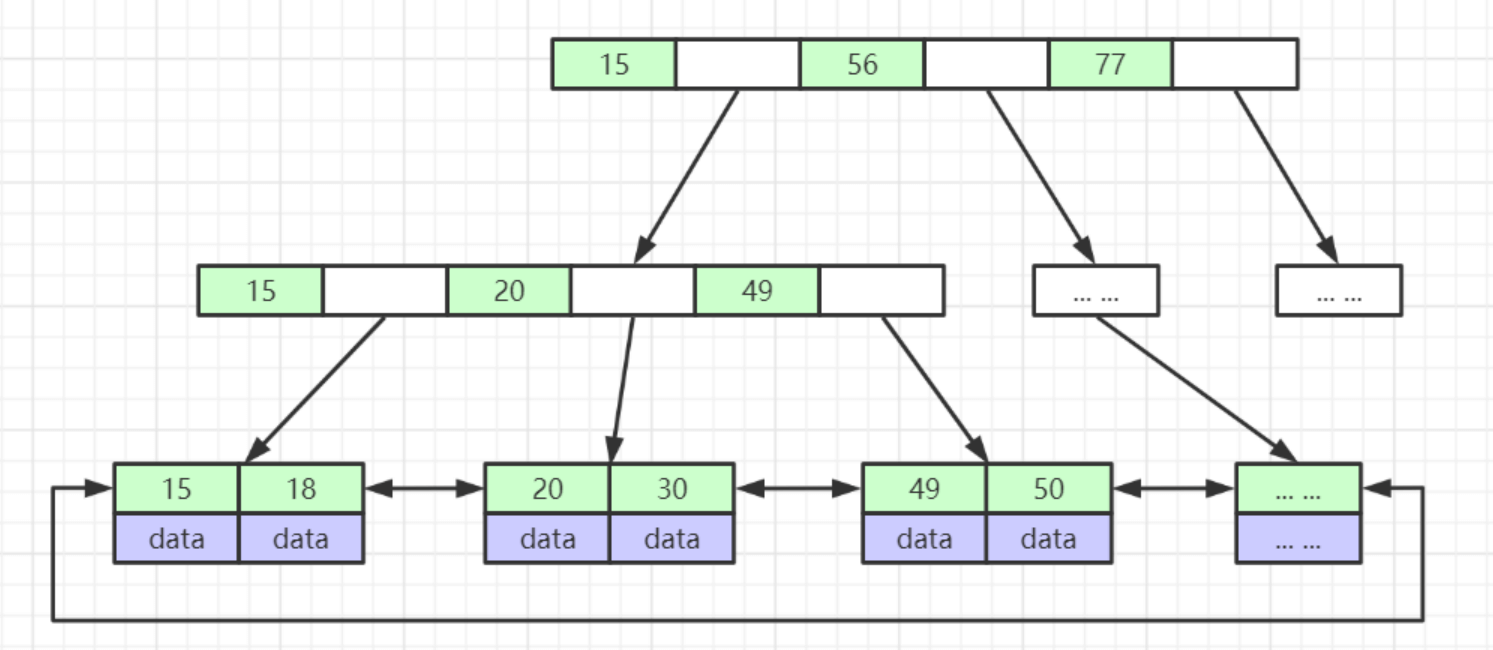
查找过程:
- 从根节点查找,第一层加载到内存,查询定位
- 到下一层,加载到内存,继续查询
- 到叶子节点,加载内存,比对确实数据
MySql的一页大小 16KBSHOW GLOBAL STATUS LIKE 'Innodeb_page_size'
每次磁盘的IO,比较耗时,
16KB,大概11170个,每个14个字节的话
根节点可能会长存内存,或可以把非叶子节点也凡在内存中
为什么选择B+ 而非B树
数据的高度影响查询次数
B树的非叶子节点可以放的索引元素太少,查询效率太低
MyISAM:
形容数据库表的
对应三个文件
表:
对应文件: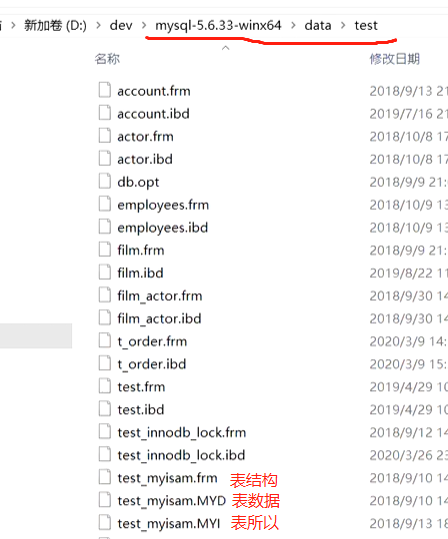
数据与索引是分离的(非聚集)
查找
- 先根据值找对应的数据地址
- 根据地址,再去加载数据
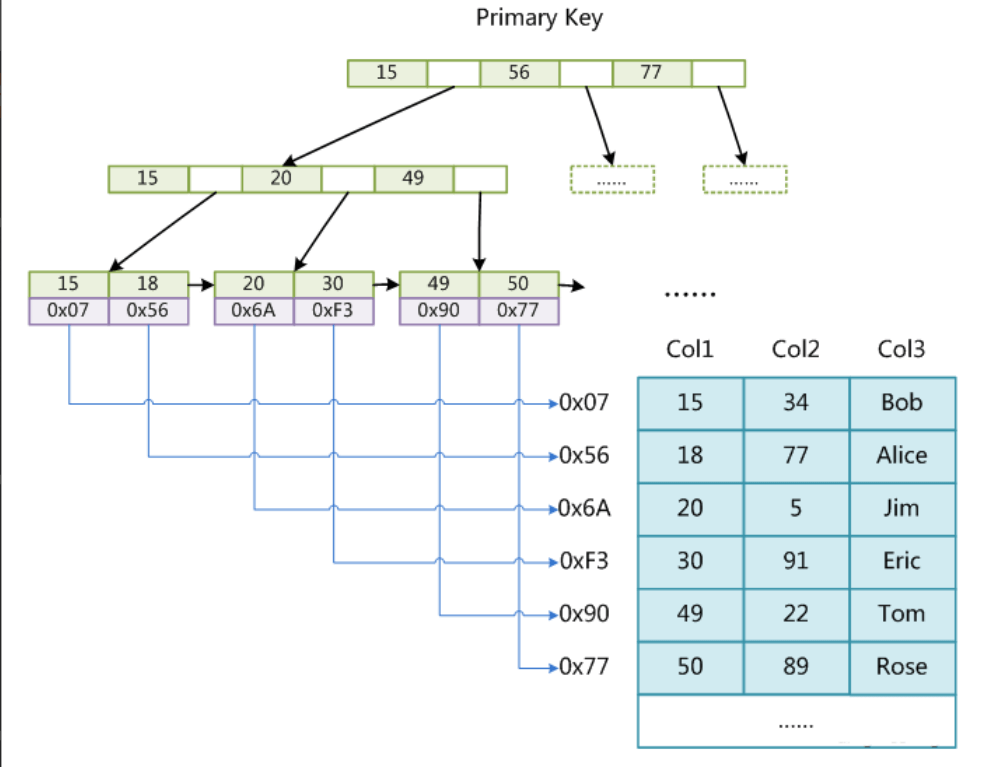
InnoDB
一个表对应两个文件
InnoDB聚集索引
InnoDB必须主键,推荐整型自增?
- 必须要组建B+树索引,如果没有,会选一列都不相等的字段区间,如果选不到,会有一个隐藏列去建主键
- 为什么是整型?整型大小比较效率高
- 整型占用空间较小
每个节点第一个索引会提上去做冗余
自增只会一致向后加节点,而不会打扰多已经存在的的节点顺序
不需要再次平衡了
非主键索引:
叶子节点会存储主键:一致性和节约存储空间
需要找到主键,在根据主键再会回表查询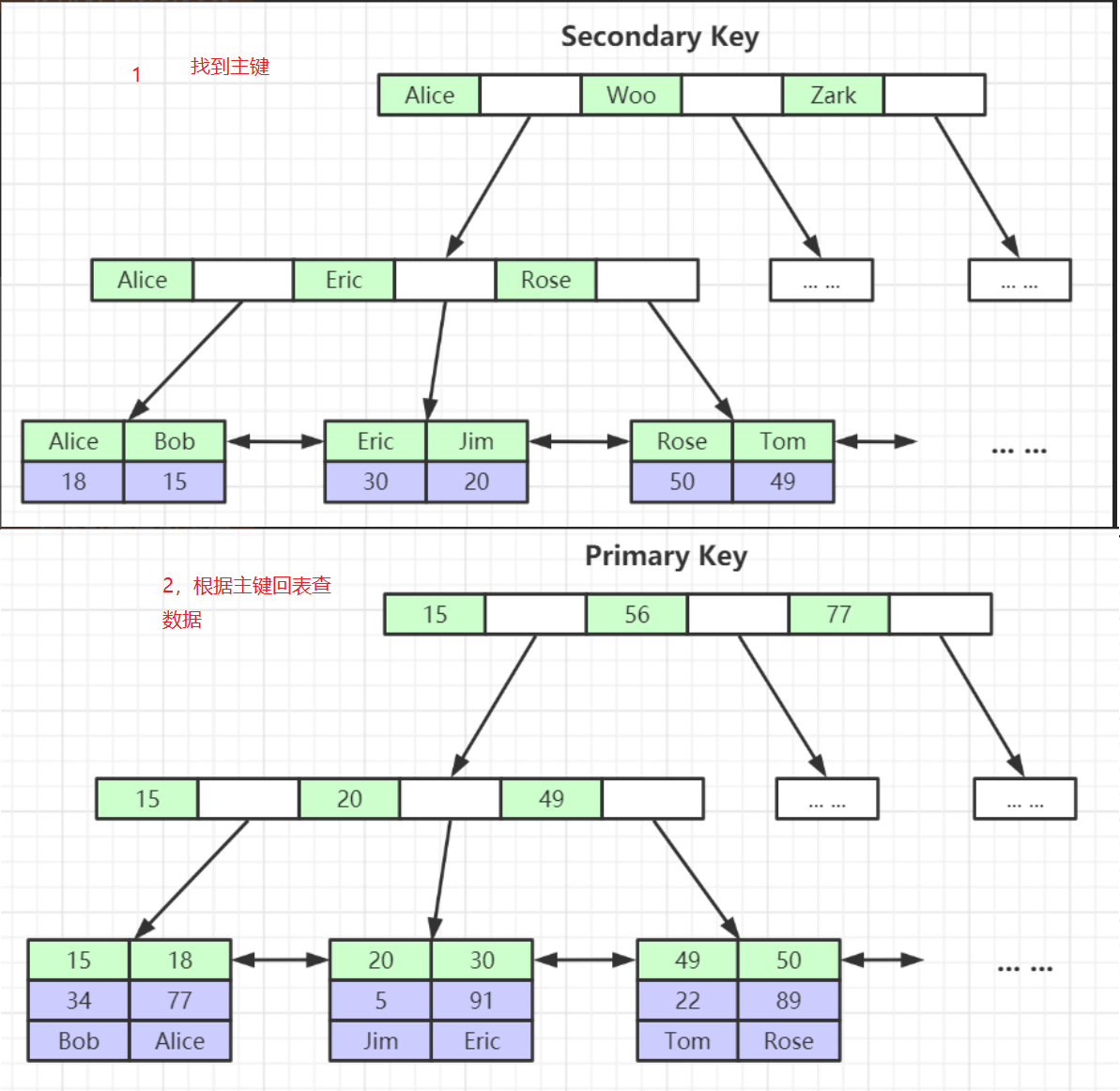
聚集索引,非聚集那个快?
Hash索引:
对索引进程Hash运算,根据Hash值,插入散列(数据是数据的地址)
类似HashMap
效率特别高,
问题 :Hash冲突,满足等值查询,不支持范围查询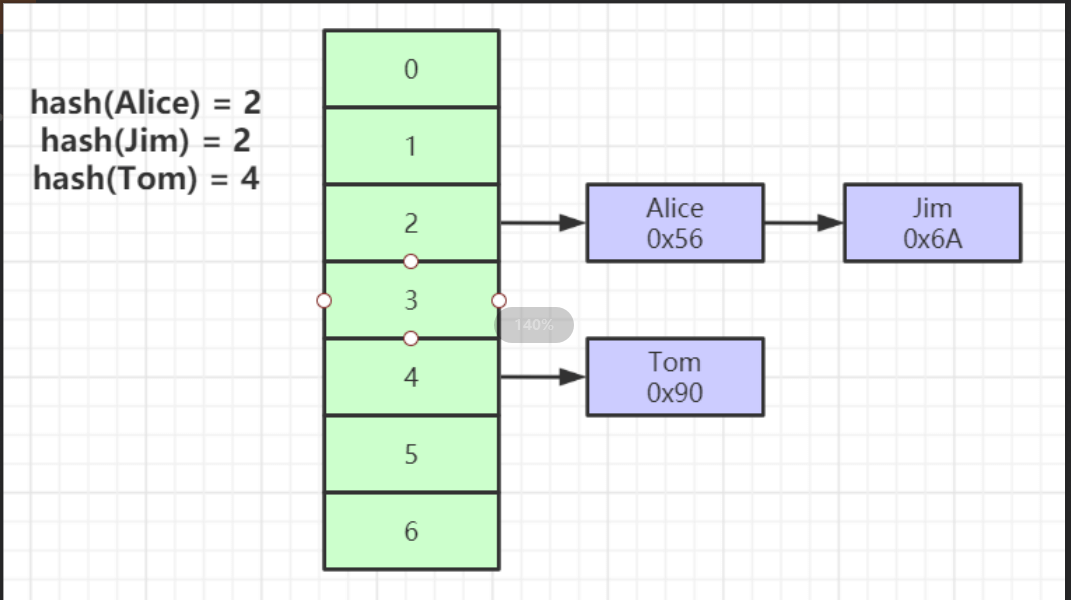
联合索引
多字段索引;
最左优先选择
逐个比较索引列,
如何排序 ,联合主键索引,
不会跳过前面的索引?
为什么不会?因为就是按照所以最左排序,的对于整张表来时,不是按照第二个列排序的
排好序的数据结构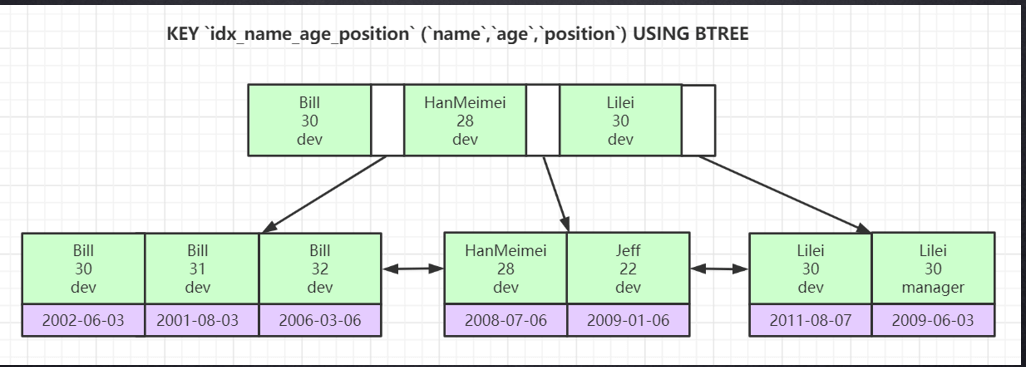

若有收获,就点个赞吧
0 人点赞
