head
深度学习模型压缩与加速综述.pdf
软件学报ISSN1000—9825,CODENRUXUEW
JournalofSoftware,2021,32(1):68—92【doi:10.133280.cnki.jos.006096]
高晗,田育龙,许封元,仲盛
(计算机软件新技术国家重点实验室(南京大学)’江苏 南京 210023)
通讯作者:许封元,E-mail:fengyuan.xu@nju.edu.cn
在不影响深度学习模型性能的情况下进行模型压缩与加速成为研究热点.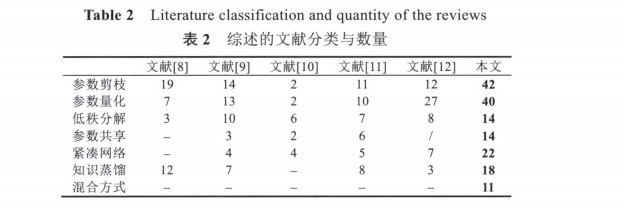
表2是本文与目前国内外最新相关综述进行方法分类的种类以及与该分类下的文章数量进行对比的情况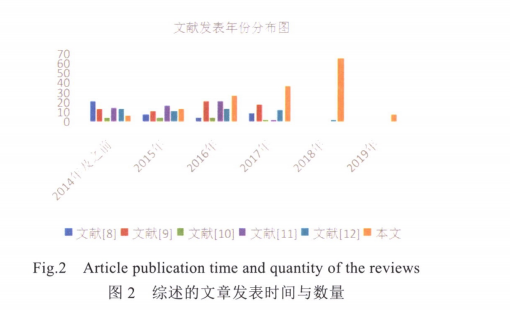
从压缩参数和压缩结构两个角度可以将压缩方法分成以下7类.
1 参数剪枝
非结构化剪枝
非结构化剪枝的粒度比较细,可以无限制地去掉网络中期望比例的任何“冗余”参数,但这样会带来裁剪后网络结构不规整、难以有效加速的问题.
结构化剪枝
结构化剪枝的粒度比较粗,剪枝的最小单位是filter内参数的组合,通过对filter或者featuremap设置评价因子,甚至可以删除整个filter或者某几个channel,使网络“变窄”,从而可以直接在现有软/硬件上获得有效加速,但可能会带来预测精度(accuracy)的下降,需要通过对模型微J同(fine.tuning)以恢复性能.
2 参数量化
3 紧凑网络
4 知识蒸馏
5 低秩分解
6 参数共享
7 混合方式
8 硬件加速
任何模型的运行都需要依托某种计算平台来完成,因此我们可以直接从计算平台的硬件设计方面来加速,目前深度学习模型的主流计算平台是 GPU,从Volta 架构开始,GPU 配备了专门用于款速矩阵乘法运算的硬件计算单元 Tensor Core , 可以显著提升深度学习模型的吞吐量, 同时,以低功耗低延时为主要特性的 FPGA/ASIC 加速芯片也开始在业界展露头角。
对比效果
结论:我们总结的7类压缩与加速方法各有利弊,由于实验使用的硬件平台不同,并不能量化地确定孰优孰劣.依据不同的应用场景和现实需要,可以进行方法的选取.
例如:

若有收获,就点个赞吧
0 人点赞
