(二) 卷积神经网络
19. 滤波器(Filters)
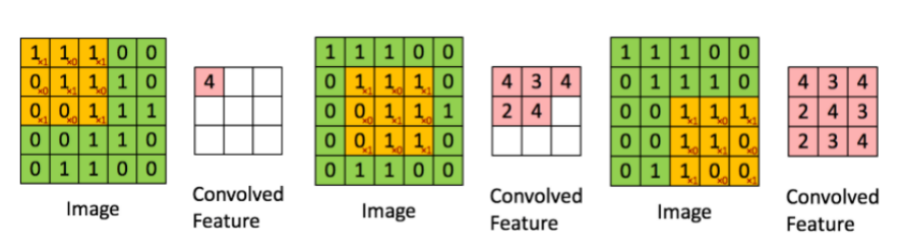
——CNN中的滤波器与加权矩阵一样,它与输入图像的一部分相乘以产生一个回旋输出。我们假设有一个大小为28 28的图像,我们随机分配一个大小为3 3的滤波器,然后与图像不同的3 3部分相乘,形成所谓的卷积输出。滤波器尺寸通常小于原始图像尺寸。在成本最小化的反向传播期间,滤波器值被更新为重量值。
参考一下下图,这里filter是一个3 3矩阵:与图像的每个3 * 3部分相乘以形成卷积特征。

20. 卷积神经网络(CNN)
——卷积神经网络基本上应用于图像数据。假设我们有一个输入的大小(28 28 3),如果我们使用正常的神经网络,将有2352(28 28 3)参数。并且随着图像的大小增加参数的数量变得非常大。我们“卷积”图像以减少参数数量(如上面滤波器定义所示)。当我们将滤波器滑动到输入体积的宽度和高度时,将产生一个二维激活图,给出该滤波器在每个位置的输出。我们将沿深度尺寸堆叠这些激活图,并产生输出量。
你可以看到下面的图,以获得更清晰的印象。
原理:
也被称之为过滤器,滤波器(filter)或者内核(kernel);filter将当前层神经网络上的一个子节点矩阵转化为下一层神经网络上的一个单位节点矩阵。

不同的卷积,可以提取图片不一样的特征。
卷积核的作用在于特征的抽取,越是大的卷积核尺寸就意味着更大的感受野,当然随之而来的是更多的参数。
对于(m×m)特征图I,用(k×k)的核做卷积,则得到的特征图O是(m−k+1)×(m−k+1)
* 对于c(m×m)特征图I,用(k×k)的核做卷积,stride是s, 则得到的特征图O是(m−k)/s+1)×(m−k)/s+1)*out_c
示例:
输入: 2272273 , kernel_size=11, stride=4 , output_c=96 , out=(227-11)/4 +1 = 55 . out = 555596
对于c(m×m)特征图I,用(k×k)的核做卷积,stride是s, pad 是 p, 则得到的特征图O是(m−k +2p)/s+1)×(m−k+2p)/s+1)out_c
卷积维度的输入输出计算公式:
输入:图片大小 I×I , Filter(卷积核)大小K×K , 步长 S , padding的像素数 P ,
于是我们可以得出输出: O = (I − K + 2P )/S+1
21. 空洞卷积(dilated convolution)理解
Dilated/Atrous Convolution(中文叫做空洞卷积或者膨胀卷积) 或者是 Convolution with holes 从字面上就很好理解,是在标准的 convolution map 里注入空洞,以此来增加 reception field。相比原来的正常convolution,dilated convolution 多了一个 hyper-parameter 称之为 dilation rate 指的是kernel的间隔数量(e.g. 正常的 convolution 是 dilatation rate 1)。
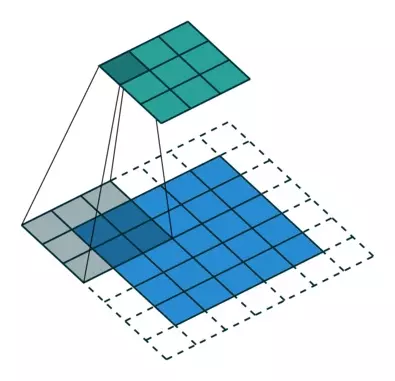
标准的卷积 : 33的kernel ,pad=1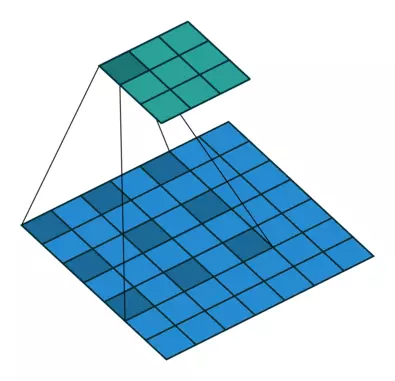
空洞卷积:33的kernel , dilatation rate=2
空洞卷积的超参数d , (d-1)的值为实际塞入的空格数, 假定原来的卷积核大小为K,那么塞入(d-1)个空格后的卷积核大小为: n = k + (k-1)(d-1)
进而,假定输入空洞卷积的大小为i , 步长为s, pad为p , dilatation rate为d, 空洞卷积后的输出为O :
**O = [i+2P-k-(k-1)(d-1)]/s + 1 **
22. 池化(Pooling)
——通常在卷积层之间定期引入池层。这基本上是为了减少一些参数,并防止过度拟合。最常见的池化类型是使用MAX操作的滤波器尺寸(2,2)的池层。它会做的是,它将占用原始图像的每个4 * 4矩阵的最大值。
你还可以使用其他操作(如平均池)进行池化,但是最大池数量在实践中表现更好。池化层可以非常有效的缩小矩阵的尺寸,从而减少最后全连接层中的参数。池化层可以加快计算速度,也有防止过拟合问题的作用。
23. 填充(Padding)
——填充是指在图像之间添加额外的零层,以使输出图像的大小与输入相同。这被称为相同的填充。
在应用滤波器之后,在相同填充的情况下,卷积层具有等于实际图像的大小。
有效填充是指将图像保持为具有实际或“有效”的图像的所有像素。在这种情况下,在应用滤波器之后,输出的长度和宽度的大小在每个卷积层处不断减小。
卷积:
Same padding :平面外面补0. 得到与原来平面大小相同的平面。
Valid padding:不补0,得到比原来平面小的平面。
池化:
Same padding :可能会给平面外面补0.
Valid padding:不补0
24. 数据增强(Data Augmentation)
——数据增强是指从给定数据导出的新数据的添加,这可能被证明对预测有益。例如,如果你使光线变亮,可能更容易在较暗的图像中看到猫,或者例如,数字识别中的9可能会稍微倾斜或旋转。在这种情况下,旋转将解决问题并提高我们的模型的准确性。通过旋转或增亮,我们正在提高数据的质量。这被称为数据增强。

若有收获,就点个赞吧
0 人点赞
