种类
Facebook 的 Glow
TVM
TC
Graph
PlaidML
XLA
综述
https://vlambda.com/wz_x19u1dUwI4.html
https://zhuanlan.zhihu.com/p/139552817
如图是深度学习框架概况:1)当前流行的框架; 2)历史框架; 3)支持ONNX格式的框架。
The Open Neural Network Exchange(ONNX),定义了可扩展的计算图模型,可以将不同框架构建的计算图轻松转换为ONNX,这样在不同框架之间转换模型变得容易。 ONNX已集成到PyTorch、MXNet和PaddlePaddle中。 对于尚不直接支持的多个框架(例如TensorFlow和Keras),ONNX对它们添加了转换器。
下表是一些常用编译器的对比:
其中缩写:just-in-time compilation (JIT)和ahead-of-time compilation (AOT)
深度学习编译器普遍采用的设计架构如图所示: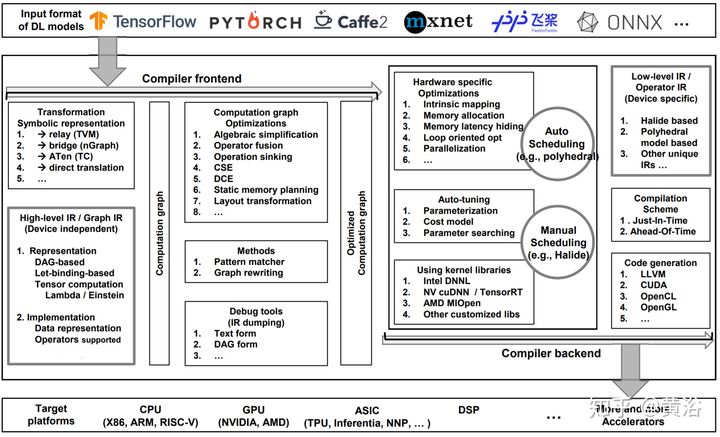
这类编译器的通用设计体系结构主要包含两部分:编译器前端和编译器后端。 中间表示(IR)横贯前端和后端。 通常IR是程序的抽象,用于程序优化。 具体而言,深度学习模型在编译器中转换为多级IR,其中高级IR驻留在前端,而低级IR驻留在后端。 基于高级IR,编译器前端负责独立于硬件的转换和优化。 基于低级IR,编译器后端负责特定于硬件的优化、代码生成和编译。
注:关于硬件实现的编译器比较参考综述文章【101】,本文重点是设计架构的比较。
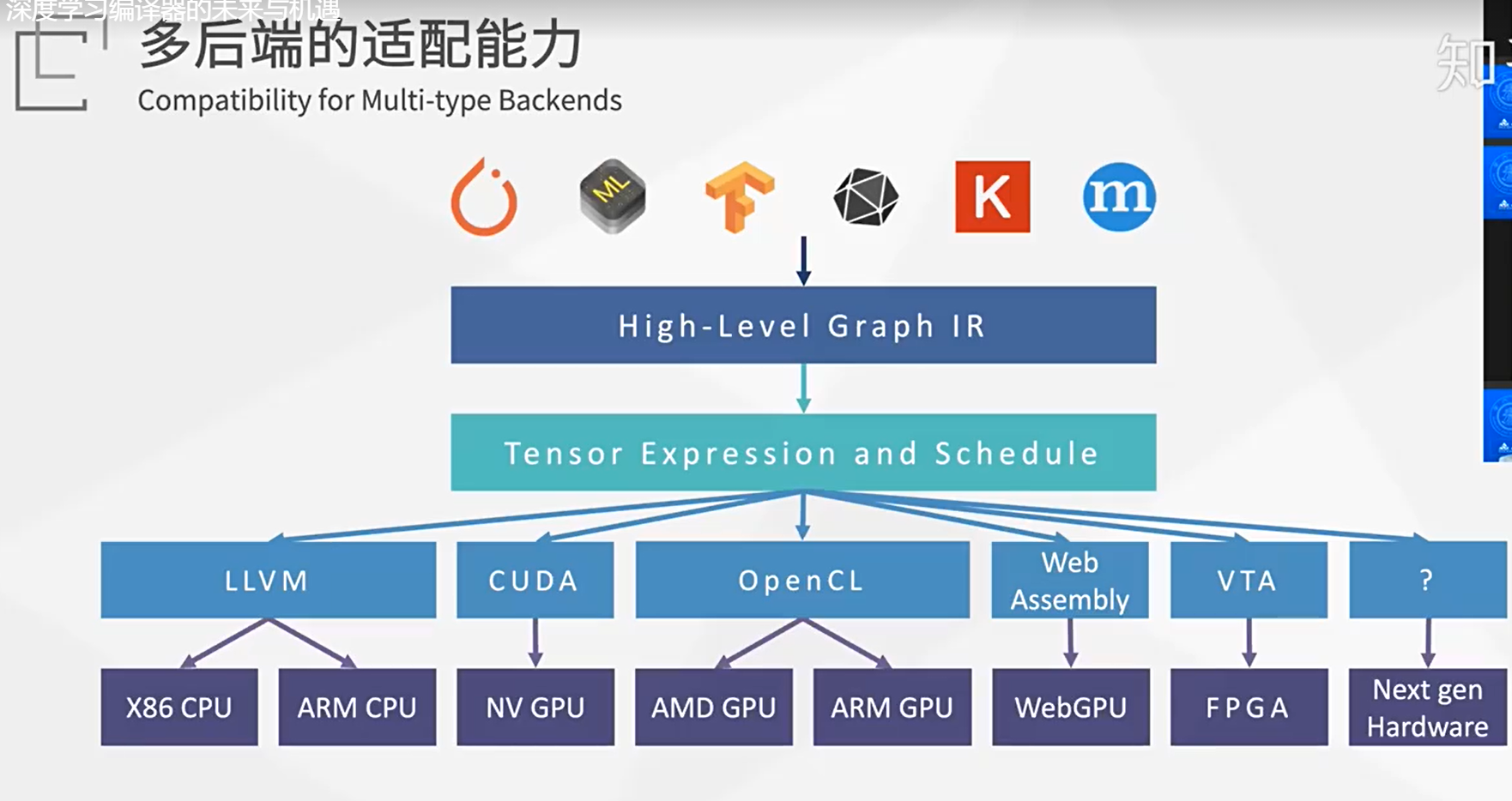
深度学习编译器和推理引擎的区别是什么?
https://www.zhihu.com/question/401766029
编译器用于将神经网络模型转换为包含引擎的可执行文件,将每一层转换为操作算子,内心分配和依赖生成等
编译器负责优化
引擎则负责执行该文件,根据文件的依赖描述调度每层算子
推理引擎负责执行
当下这个时间点(20200622)其实没有太大意义了,无论是早前的TC/Halide/TensorRT,还是当下最火的TVM,其路线都不仅仅局限于传统编译器领域为“编译器”三字所下的定义,而是一整套解决方案。
就目前实际而言,很多时候深度学习编译器也会被当做推理引擎来用,但是深度学习编译器和传统的推理引擎实现会有所不同。在深度学习编译器中,很多时候在后端会被Lower成IR的表示,而优化加速的方式也是IR层面的优化,然后最后的生成也是IR进行Code Generation(这一层的IR往往是很少的,所以Code Generation很快就可以搞完),生成更底层的LLVM IR / OpenCL / CUDA / …,
传统的推理引擎往往缺失这一层,更多的会在算子的层面进行实现与优化,如convolution在arm cpu / OpenCL / CUDA分别实现一遍,这样相比深度学习编译器很容易出现某某平台支持,但是换个平台就不支持,这在以TVM为代表的深度学习编译器很少见。深度学习编译器在设备爆炸时的优势会比较明显。
tvm过人之处在于能够自动调优,这是ncnn,tensorrt,mace,mnn等不具备的。支持各种平台与开发,本人用过python,c++,java去调tvm的runtime,在android,window,linux上都可以跑
TVM,XLA这些深度学习编译器和TNN,MNN这些深度学习推理引擎之间的区别是什么呢?
首先,要解决的问题不同:
TVM和XLA要解决的是如何通过编译的方法分离前端表意与后端多硬件的问题,这个问题本身曾经在编程语言领域也遇到过,所以借鉴过来。
MNN之流是为了解决常见的深度学习模型高效地跑在手机端的问题。
其次,MNN之类的核心不仅仅是适配多硬件,还有比如:减少最终部署时候的size。控制功耗等手机端的问题。而性能不是唯一最重要的问题了。
所以,你看这些都不是冲着性能去的。
之所以大家都在谈性能是因为性能是唯一可以在固定模型,固定硬件下,且有一定门槛的可量化比较的指标了。
TVM
tvm 系列操作教程
https://blog.csdn.net/sinat_31425585/category_8874264.html
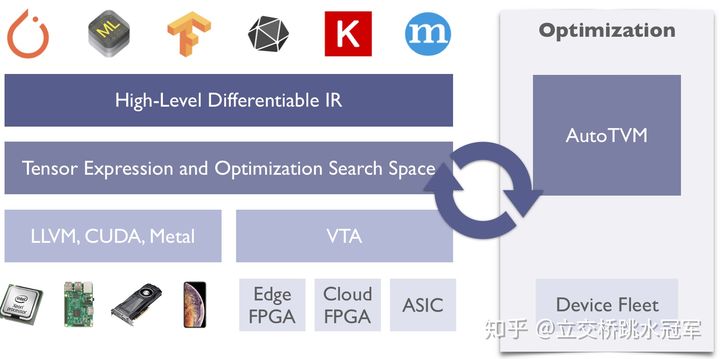
(https://zhuanlan.zhihu.com/p/88188955)
按照官方的定义,TVM是一套完整的stack,包括神经网络图优化(比如op fusion)和单个operation优化等部分。我习惯于将图优化的部分归类做Relay项目,而仅仅把单个operation优化看做TVM,因此文章之后提到的TVM基本是指单个算子优化这部分。
上面这张摘自tvm的官网(https://tvm.ai/about)的图片说明了TVM处于深度学习框架的位置。TVM位于神经网络图(High-Level Differentiable IR)的下方,底层硬件(LLVM, CUDA, Metal)的上方。
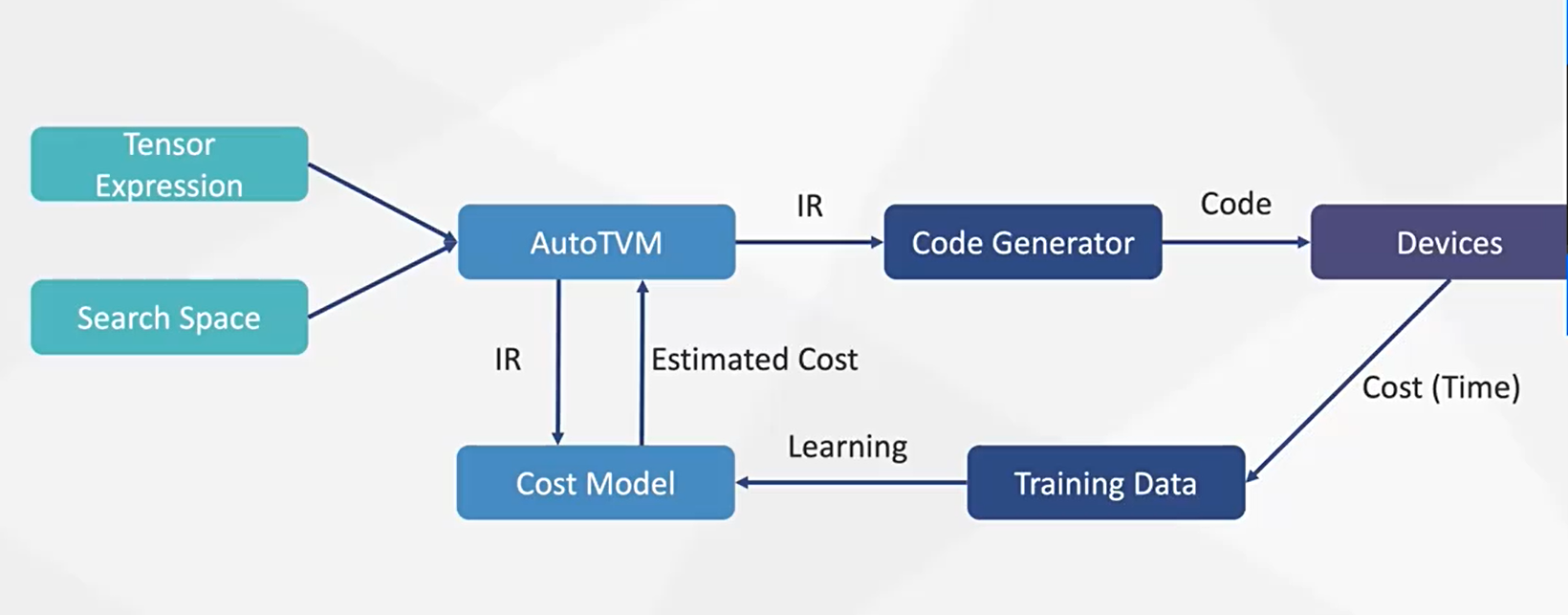
图片右边的AutoTVM我认为比较独立。这个目的是自动调整TVM生成的代码的一些参数,试图让TVM生成的代码尽可能快。做自动代码优化的优秀项目除了AutoTVM,还有Halide(https://halide-lang.org/papers/autoscheduler2019.html),个人认为目前Halide做代码自动优化做的更好。TVM的基本思路参考自Halide,其中的数据结构也引用了很多Halide的实现,强烈推荐感兴趣的朋友研究一下Halide
新得operation指的具体: 就是会有层出不穷的op,比如deform convolution, maxunpool这种稀奇古怪的操作
深度学习模型编译框架 TVM 概述
https://zhuanlan.zhihu.com/p/353660224
在任意深度学习的应用场景落地一个模型/算法时,需要经历两个基本步骤:1. 根据数据生产一个模型的训练步骤;2. 将生产出的模型部署到目标设备上执行服务的推理步骤。训练步骤目前基本由Tensorflow、PyTorch、Keras、MXNet等主流框架主导,同样的,推理步骤目前也处在“百家争鸣”的状态。
TVM是什么?
TVM是一款开源的、端到端的深度学习模型编译框架,用于优化深度学习模型在CPU、GPU、ARM等任意目标环境下的推理运行速度,常见的应用场景包括:
- 需要兼容所有主流模型作为输入,并针对任意类型的目标硬件生成优化部署模型的场景
- 对部署模型的推理延迟、吞吐量等性能指标有严格要求的场景
- 需要自定义模型算子、自研目标硬件、自定义模型优化流程的场景
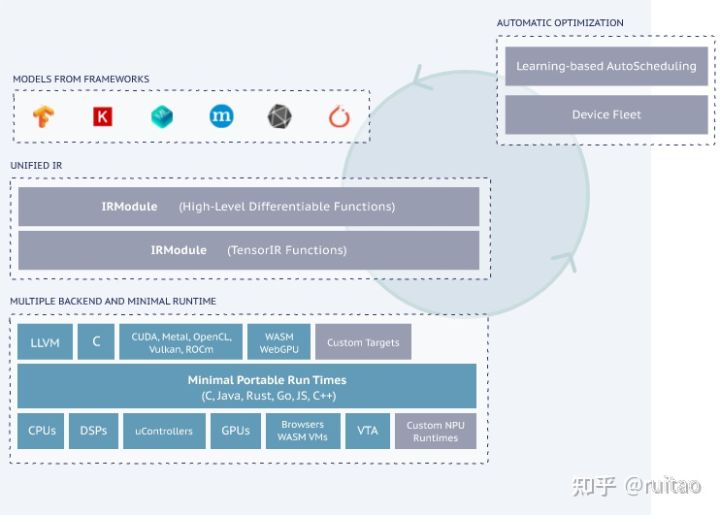
TVM软件框架(图片来自TVM官方网站)
TVM框架如上图:主流的深度学习框架(Tensorflow, Pytorch, MXNet等)导出的模型作为TVM框架的输入,经过该框架内一系列的图优化操作以及算子级的自动优化操作后最终转化为针对目标运行时(CPU/GPU/ARM等)的部署模型,优化后的模型理论上可以最大化地利用目标硬件的资源以最小化模型的推理延迟。
为什么用TVM优化模型推理?
模型推理场景下用于模型优化、部署的软件框架仍处于“百家争鸣”的状态,其原因在于推理任务的复杂性:训练后的模型需要部署于多样的设备上(Intel CPU/ NVGPU/ ARM CPU/FPGA/ AI芯片等),要在这些种类、型号不同的设备上都能保证模型推理的高效是一项极有挑战的工作。
一般来说,主流的硬件厂商会针对自家硬件推出对应的推理加速框架以最大化利用硬件性能,如Intel的OpenVINO、ARM的ARM NN、Nvidia的TensorRT等,但这些框架在实际应用场景中会遇到不少问题:
- 厂商推理框架对主流训练框架产生的模型的算子种类支持不全,导致部分模型无法部署
- 模型部署侧的开发人员需要针对不同的硬件编写不同的框架代码,花精力关注不同框架对算子的支持差异和性能差异等
因此,一套可以让我们在任意硬件上高效运行任意模型的统一框架就显得尤其有价值,而TVM正是这样一套框架。
TVM框架构成
以“模型部署”为边界,TVM可以分为TVM编译器和TVM运行时两个组件: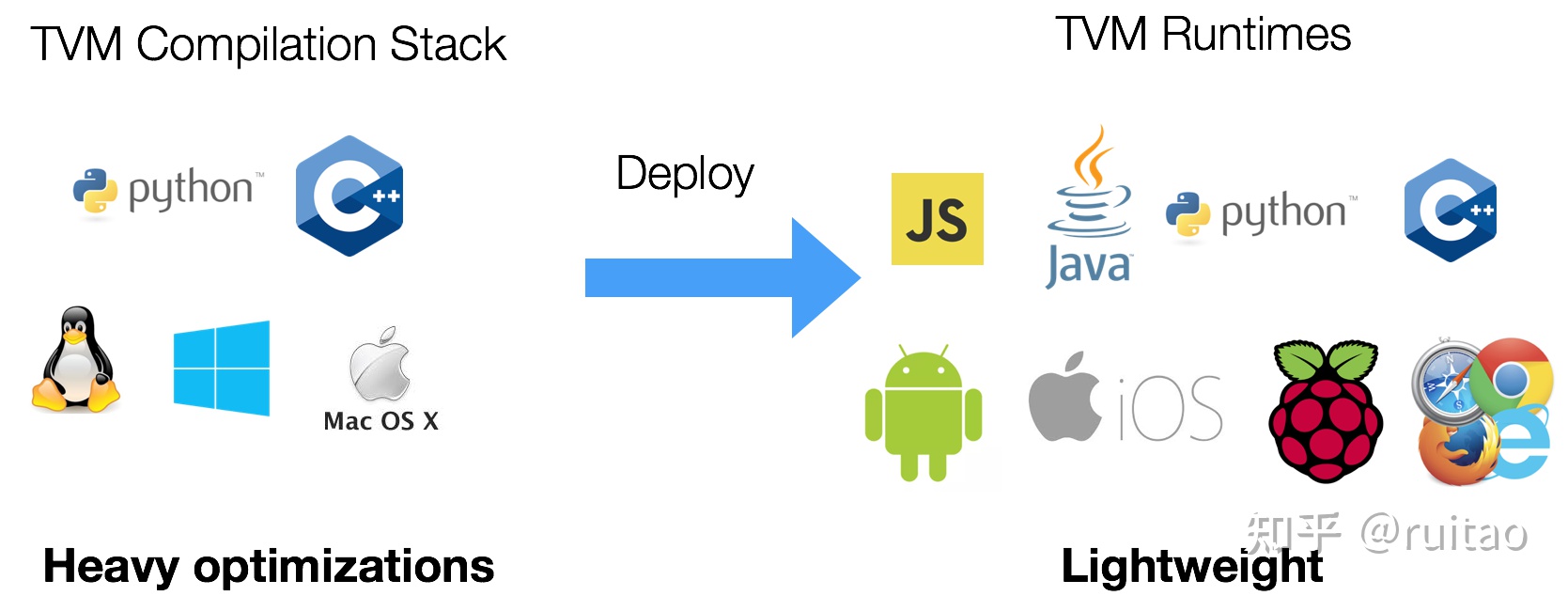
TVM组件:编译器和运行时(图片来自TVM官方网站)
编译器负责模型的编译和优化,是TVM的主体功能:
- 编译优化过程支持Python和C++接口
- 系统环境支持Linux、Windows以及MacOS平台(部分功能如AutoTVM在非Linux平台可能受限)
运行时负责在目标设备上执行编译器生成的模型推理代码:
- 部署过程支持JS, Java, Python, C++语言
- 部署平台除了支持Linux、Windows以及MacOS系统,还支持Android, IOS, 树莓派等端侧系统
备注
https://www.zhihu.com/people/hong_pku/posts 编译器
end

若有收获,就点个赞吧
0 人点赞
