不懂
*P ++ : 取出p所指的那个数据来,完事之后顺便把p移到下⼀一个位置去
OVERFLOWint LocateElem_Sq(Sqlist L, ElemType e, Status (* compare) (ElemType,ElemType)) { // 函数的参数里 可以有 另一个函数, }
已知
// 函数的 健壮性: 1 传入的参数 判断 : ( a 类型, b 值大小)
// 时间复杂度的 算法, 对于这个函数, 会出现什么可能的参数, 每个参数出现的 可能。 p25。
char : 1字节 (8 bit)
short: 2字节
int: 取决于 编译器(cpu),通常意义是“1个字长”
long: 取决于 编译器(cpu),通常意义是“1个字长”
\n 换行, \r 回车 , \t 下一个表格位, \b 回退一格。
c 语言的函数, 传的是 值。 若是希望传地址, 则需要,指针。*p;
printf(“%.3f\n”,-0.0049) // % 与 f 之间加上 .n 可以指定输出 小数点后几位(四舍五入)
printf(“%.30f\n”,-0.0049)
形式参数: 函数参数表中的参数,
形式参数: 调用函数时给的参数;
变量的 生存期 和 作用域。
笔记
C 中,
char 1 个子长
short 2B
int,为4B,
double 8 B,
longdouble 16B。
sizeof 是静态的, 它不会做实际的执行,
a = 2sizeof(a+4.0)printf(a) //a
寄存器的位数。(cpu一次能处理的数据的位数), 总线。 字长。 1个int就是一个字长。
// 现在机器 大多是 32 ,64 bite的字长。 现代的编译器一般会设计 内存对齐, 这个时候,你用 char,short不见得比 你用int更快。 一般情况下 我们就用int就好了。
计算机内部 一切数据都是 二进制。
补码, 8个bite,多出来的那个 1, 100000000(九位),1 就会被丢掉。
补码 : 就是拿补码和源码相加出一个溢出的”零“。
00000001 表示 1
11111111 原本表示 255, 当作补码的时候, 就是 -1.
00000000 —> 0
000000001 — 01111111 —> 1 — 127
111111111 —- 10000000 —-> -1 — -128 // 没有unsigned char 就是127, //有unsigned的时候,char就是255.
char c = 255 // -1 这里会当作补码来看待
unsigned char c = 255 // 255 unsigned 表示就是 纯二进制。 255U输出%U``````%lu%d就是10进制。 %o八进制 012 为 10(十进制) %x十六进制 0x12 为 18 (十进制)
inf 无穷大,
nan 不是一个有效的数字,
有效数字 的位数, (超过一定的位数,后面的几位他就不一定表示准确了 )
float, %f输入 %f输出 %.16f输出0后16位 %e科学计数法
double %lf输入 %f输出 %e科学计数法
<< 计算机内 float, double有的数是无法准确表达的, float 直接计算的结果其实是 很容易得不到精确的结果的,因为它只有一定范围内的计算, 误差在一定的范围内才能相信。(这是因为它在计算机内部的 存储 是一个编码的运算, 而不是纯二进制。所以计算就有问题)
但是整数的运算是精确的。 (纯二进制)
选择的话 ,没有特殊需要, 直接就用 double.
char 是整数, 也是一种特殊的字符。 %c输入,%c输出
当你给它赋值的时候, 你从外部看他,
49 == "1"int 49 == char “1” 在计算机内部。
int i = "Z" - "A"这个时候,i == 25.
逃逸字符
terminal 其实是 shell 程序。
回退, 指针回到下一个。
tab (制表符)在行中的固定位置。
自动类型转换。(执行时, )(输出)(输入时候比较麻烦,注意)
强制类型转换。(注意 可能溢出,则导致 值 变了。) (强制类型转化 优先级 高于四则运算)
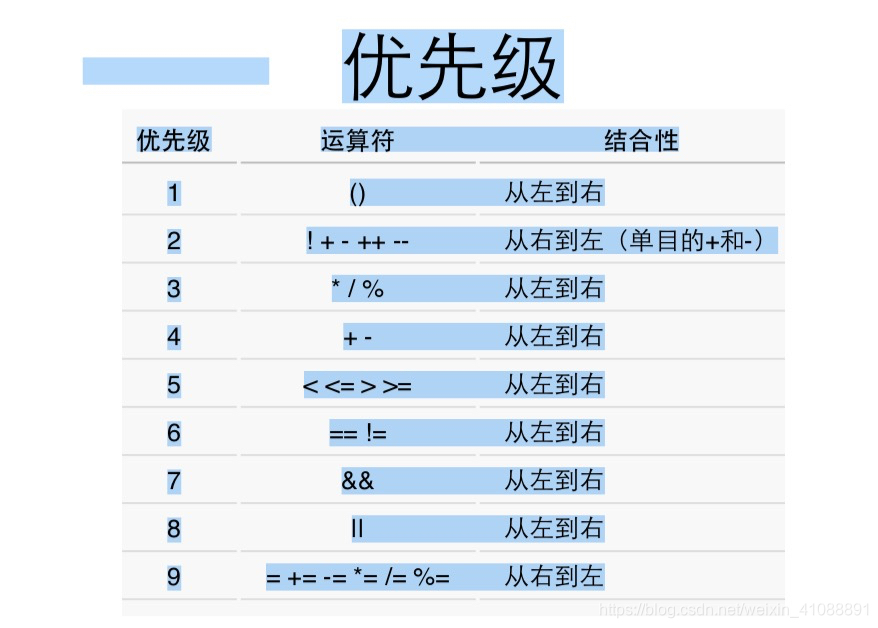
! > && > || 优先级比较, 同时 !优先级高于 + - * / 。
短路 (不要把 赋值, 组合赋值 写进 逻辑判断里) (否则容易 短路(赋值不执行))
,逗号是C中表达式, 基本只用在 for循环里面。
“代码复制” 是质量不高啊的表现。
函数:
返回类型, 函数名(参数){
}
void kk() // void 表示 没有返回
{
int a ;
printf("it is kk, %n",a);
}
int max(int a, int b) //返回的结果 为 int类型。
{
int ret;
if ( a > b){
ret =a ;
} else {
ret = b ;
}
return ret;
}
函数的先后顺序, C的编译器,逐行的 从上至下。
所以我们 调用之前, 还是提前把他给写出来,
函数原型:函数头;如果想要开始就调用 main() , 可以用 函数声明 。//定义就可以放在后面了。
参数: 可以是表达式的结果。(字面量, 变量,函数的返回值,计算的结果)
// 在 C里, 如果你的参数的类型 不对, 不一定有 报错, 这是一个巨大的漏洞。 //后续的 C++,Java,对这个就很严格。
C语言在调用函数的 时候, 永远只能传值给函数。
每个函数有自己的变量空间, 参数也位于这个独立的空间中, 和其它函数没有关系。
递归的时候, 每段函数都有自己的独立的空间。
变量的生存期, 作用域:
本地变量的作用域与生存期 : {} // 外部定义,内部能用; 内部定义,外部不能用。
本地变量不会被初始化,但是参数会被初始化。
1 // 声明 int kk(void); //没有参数的时候, 尽量用void, 避免错误。
main函数里的 return 0; //return 还是有人看到,
数组。
int number[100] #定义了数组。 数组的大小 可以用变量来表示。 相当于容器。
// 容器 已经成为了一种判断 语言能力的 标准,
/ // C中的数组, 容器的所有元素具有相同的 数据类型; 一旦创建, 不能改变大小; 数组中元素在内存中是连续一次排列的。
数组的运用需要 首先初始化。
int a[10];
a[1]=0;
int a[] ={1,33,44,53,345};
int a[5] = {2}; // 2,0,0,0,0
int a[10]= {[1]=2,4,[5]=9} //0,2,4,0,0,5
int a[]= {[1]=2,4,[5]=9}
sizeof(a)/sizeof(a[0]) // 表示 数组的长度, 这个写程序不容易出错, 很方便。
int a[] ={1,33,44,53,345};
int b[] =a; 这是错的。 // C是不能这样做的。 还是 遍历来赋值吧。
数组作为参数的时候 ,必须由另一个参数来传入数组的大小。
在函数内 加上一些 {}, 大多是为了方便调试。
// C 的 编译和运行环境,都不会检查数组下标是否越界, 但是运行的时候可能就会出错, (大部分都会出错。 这就是比较蛋疼的地方。 )
int a[0] //可以存在,但是没用。
同一个常量出项多次, 用 const 定义, 方便你的 代码修改和阅读。
??? prime[count++] = i; //
多维数组
int a[3][5]; // 3行5列的 二维数组。
int a[][5]={ // 至少有 列数
{1,2,3,4,5},
{55,66,23,45,12}
}
9.2 指针运算
char 指针+1, 地址+1, sizeof(char) —-> 1
int 指针+1, 而地址+4 , sizeof(int) —-> 4
指针+1, 其实是 sizeof() +1 . 这里是下一个存储单元。
指针相加减, 就是 位置的相加减。
p++ : (p++) (语言若以 编译的底层语言, 就跑的越快)
0地址, 进程,虚拟的地址。
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
int number;
int* a;
int i;
printf("please input number");
scanf("%d",&number);
a = (int*)malloc(number*sizeof(int));
for (i=0; i<number; i++){
scanf("%d", &a[i]);
}
for (i=number-1;i>=0;i--){
printf("%d".a[i]);
}
free(a);
return 0;
}
没有free,时间长了, 就容易 内存泄漏。
只能free一次,而且只能是原来的 值。多次free再次free, 会报错。
计算机中 最小单位是二进制数中的一位, bite. (位,bit)
一个字长的位串 表示一个整数
8位 二进制表示 一个字符。

若有收获,就点个赞吧
0 人点赞
