深度学习模型优化方法有:
(1)模型压缩:模型权重量化、模型权重稀疏、模型通道剪枝
(2)优化推理引擎:TVM、tensorRT、OpenVINO
深度学习推理引擎的又一些思考
https://zhuanlan.zhihu.com/p/144348913
https://zhuanlan.zhihu.com/p/87392811
推理引擎优化—五大方向
2019年以来主流性能优化主要有五个大的方向 (http://blog.sina.com.cn/s/blog_61bc01360102zgsx.html)
第一,利用metal、opencl、opengl、vulkan方式借助异构GPU加速神经网络计算;
第二,优化访存结构,借助ncwh->nc4hw4 layout,借助bf16 fp16 int8等低精度量化手段,减少访存miss提高性能;
第三,fp16 int8量化计算,利用armv8.2[8][3-5] A55 A76等新cpu带来2倍4倍于fp32的量化计算提高性能;
第四,算法层面,自动指令重排tvm方案,以及完成卷积计算的不同算法(滑窗/im2col+gemm/winograd…),完成某个特定计算的计算核心多了起来,针对每种不同的计算方案进行在线搜索,搜索出当前设备上最优的计算内核来完成优化;
第五,调度层面,计算kernel对于不同计算设备混合计算下的最优计算加速;
优化推理引擎
(1)Intel 的 OpenVINO
(2)NVIDA 的 tensorRT
(3)ARM 的 ARM NN :https://github.com/OAID/Tengine
(4)Tencent 针对移动端应用推出 NCNN
(5)TVM (开源,广泛,编译框架)
于2020/04/30(基于网上查阅资料和官方文档)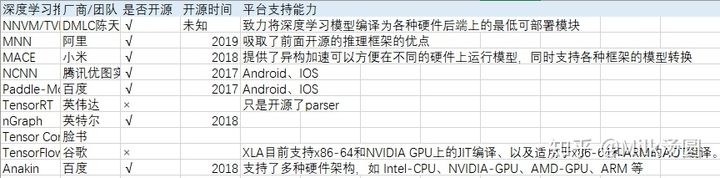
2017 年 Google 提出了 Transformer [1] 模型,之后在它基础上诞生了许多优秀的预训练语言模型和机器翻译模型,如 BERT [2] 、GPT 系列[13]等
字节跳动开源序列推理引擎LightSeq https://zhuanlan.zhihu.com/p/269478459
TFLite这样的框架,即调用高效的GEMM加速库,抑或着NCNN这样的框架,针对ARM CPU手写汇编
LightSeq 可以应用于机器翻译、自动问答、智能写作、对话回复生成等众多文本生成场景
OpenVINO、TensorRT、Mediapipe—- AI 推理框架对比

若有收获,就点个赞吧
0 人点赞
