模型、训练、算法这几个概念是机器学习和深度学习的最基础,现在看来有必要说明一下。 以下所有解释均仅限于人工智能领域。
模型
模型是什么?通常形容AI语境下的模型一词时,比较多的情况会类比数学领域的函数。不过个人感觉,那样比较容易跑偏,不如我们先姑且将它理解成是“一个程序”吧。
模型这种“程序”接受输入,经过一系列内部处理,给出输出——在这一点上它和普通意义上的程序一样。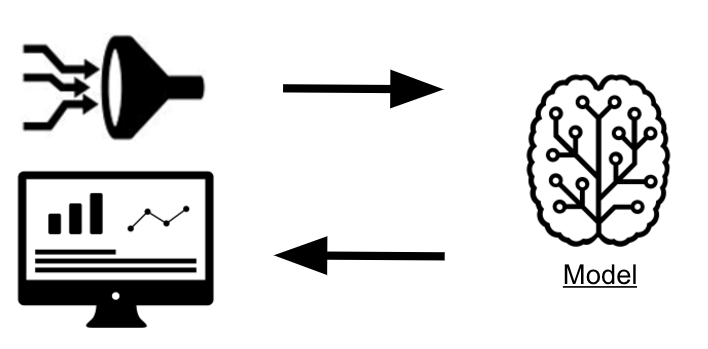
模型和普通程序不一样的是:后者是人类直接编写出来的,而前者则是经有另外一个人类编写的训练程序训练出来的。
从某种意义上可以说,模型是程序产生的程序。
训练程序和算法
这个训练模型的程序(简称训练程序),一般情况下是实现了某一种训练算法,这个算法接受输入的数据,进行某些运算,运算的结果就形成了模型。
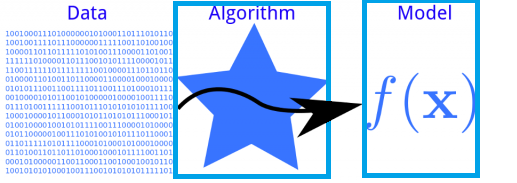
训练程序运行的过程就叫做训练,模型是训练程序的输出,训练的结果。
概念间的关系
说到这里,我们已经涉及到了四个概念:A.普通程序;B. 模型;C. 训练程序;和D.算法。
它们之间的关系见下图:
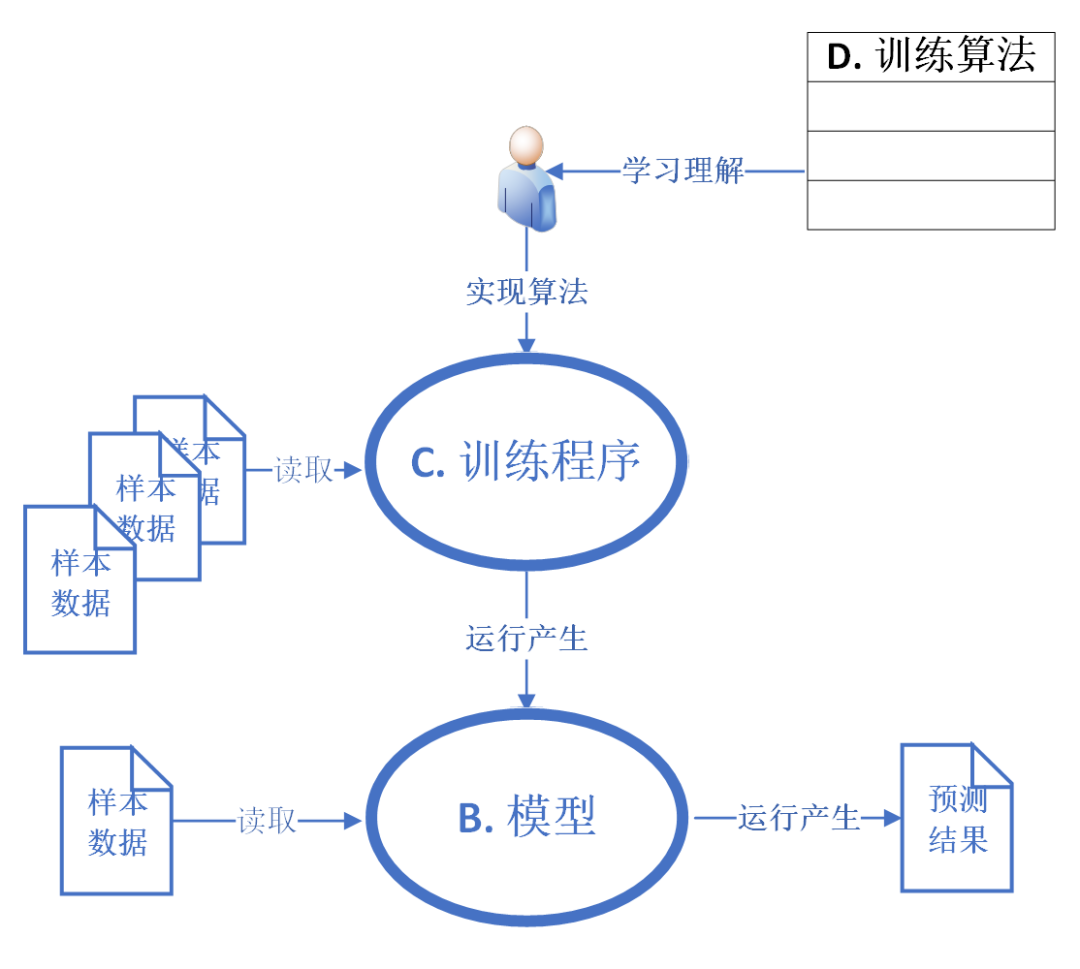
共性
普通程序、模型和训练程序的共性是:接受输入数据;内部处理输入的数据后生成输出数据;输出输出数据。
不同
但是它们仨又有所不同:
A(普通程序)和C(训练程序)都是人类编写出来的;而B(模型)则是C运行的结果(输出)。
A和B对输入输出的处理是静态的;而C对输入输出的处理是动态的。
静态 vs 动态
关于不同之处的第2点——“静态处理输入输出”和“动态处理输入输出”的区别,我们需要特别解释一下。
静态是指:对于A(普通程序)和B(模型)而言,给它们一个特定的输入,它们就会给出一个特定的输出。
A和B能够处理的数据非常多,但就算是各自接受一百万份输入,每份输入对应的输出都是既定的,并不会因为A或B之前已经处理了其他的数据而产生不同的输出。
动态则是说:C(训练程序)在获得不同的输入后会输出不同的B(模型)。
“训练程序在获得不同的输入数据后输出不同的模型”——这是什么意思?
来看个例子:
我们用某个训练程序 c0 训练了包含2M样本的数据集Dataset_1,生成了一个模型b1。
后来,我们又获得了包含另外1M样本的数据集Dataset_2。既然又有了新数据,自然就想把Dataset_2也用于 c0 的训练。那么我们可以:
- 方式 i)用Dataset_2从头开始训练,可以获得模型b2;
- 方式 ii)将b1作为预训练模型,在它的基础上,用Dataset_2继续训练,获得模型b1’。
按照上述两种方式,c0同样是处理Dataset_1+ Dataset_2共3M的样本数据,但因为具体的训练方式(运行c0的方式)不同,输出的结果是不同的。
- 方式 i)输出的两个模型:b1是基于2M样本获得的,b2是基于1M样本获得的。
- 方式 ii)输出的两个模型:b1基于2M样本,而b1’ 则是基于3M样本!
两种方式中的b1是一样的,b2和b1’ 却差距颇大。
- b2仅具备从Dataset_2中学习到的知识;
- b1’ 除了Dataset_2,还学习了Dataset_1中的知识——这一部分不是通过直接的训练,而是通过已经训练出来的b1间接得到的。相当于b1先学习了Dataset_1中蕴含的知识,再移交(transfer)给了b1’ .
Transfer Learning
顺便说一下,方式 ii)又叫做迁移学习(Transfer Learning),是不是有点耳熟?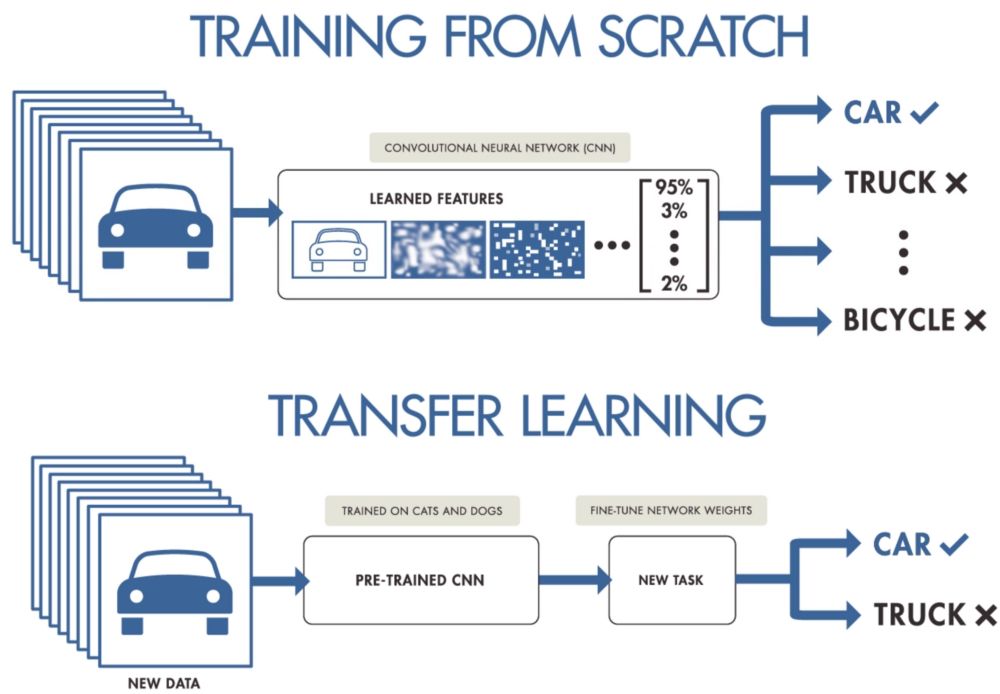
造成这样差异的原因不是数据,也不是训练程序本身,而是训练的方式不同。这就是训练程序的特色啦!
————————————————
版权声明:本文为CSDN博主「叶锦鲤」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/YeJuliaLi/article/details/104586301

若有收获,就点个赞吧
0 人点赞
