https://www.bilibili.com/video/BV1B5411W7TW?from=search&seid=52486649454542281
2 CUDA Python—存储管理以及卷积计算.py
2 CUDA-python—并行计算基础-卷积计算以及共享内存.pdf
3 CUDA-python—多流执行和cuBLAS.ipynb
3 CUDA-python—多流执行和cuBLAS.pdf
day_1
import cv2import numpy as npfrom numba import cudaimport timeimport math# gpu function@cuda.jitdef process_gpu(img, channels):tx = cuda.blockIdx.x * cuda.blockDim.x + cuda.threadIdx.xty = cuda.blockIdx.y * cuda.blockDim.y + cuda.threadIdx.y# all in one loopfor c in range(channels):color = img[tx, ty][c] * 2.0 + 30if color > 255:img[tx, ty][c] = 255elif color < 0:img[tx, ty][c] = 0else:img[tx, ty][c] = colordef process_cpu(img, dst):rows, cols, channels = img.shapefor i in range(rows):for j in range(cols):for c in range(3):color = img[i,j][c]*2.0 + 30if color > 255:dst[i,j][c] = 255elif color < 0:dst[i,j][c] = 0else:dst[i,j][c] = colorif __name__ == "__main__":# create an imageimg = cv2.imread("dog_test_101.jpg")rows, cols, channels = img.shapedst_cpu = img.copy()dst_gpu = img.copy()start_cpu = time.time()process_cpu(img, dst_cpu)end_cpu = time.time()print("cpu process time: ", end_cpu - start_cpu)# gpu functiondImg = cuda.to_device(img)threadsprblock = (16, 16)blockspergrid_x = int(math.ceil(rows/threadsprblock[0]))blockspergrid_y = int(math.ceil(cols/threadsprblock[1]))blockspergrid = (blockspergrid_x, blockspergrid_y)cuda.synchronize()# 同步start_gpu = time.time()process_gpu[blockspergrid, threadsprblock](dImg, channels)cuda.synchronize()end_gpu = time.time()dst_gpu = dImg.copy_to_host()print("gpu process time: ", end_gpu - start_gpu)# savecv2.imwrite("result_cpu.jpg", dst_cpu)cv2.imwrite("result_gpu.jpg", dst_gpu)print("#### done")
what_is_cuda



异构计算



SM: 
每16 核 共享一个 解码器/译码器
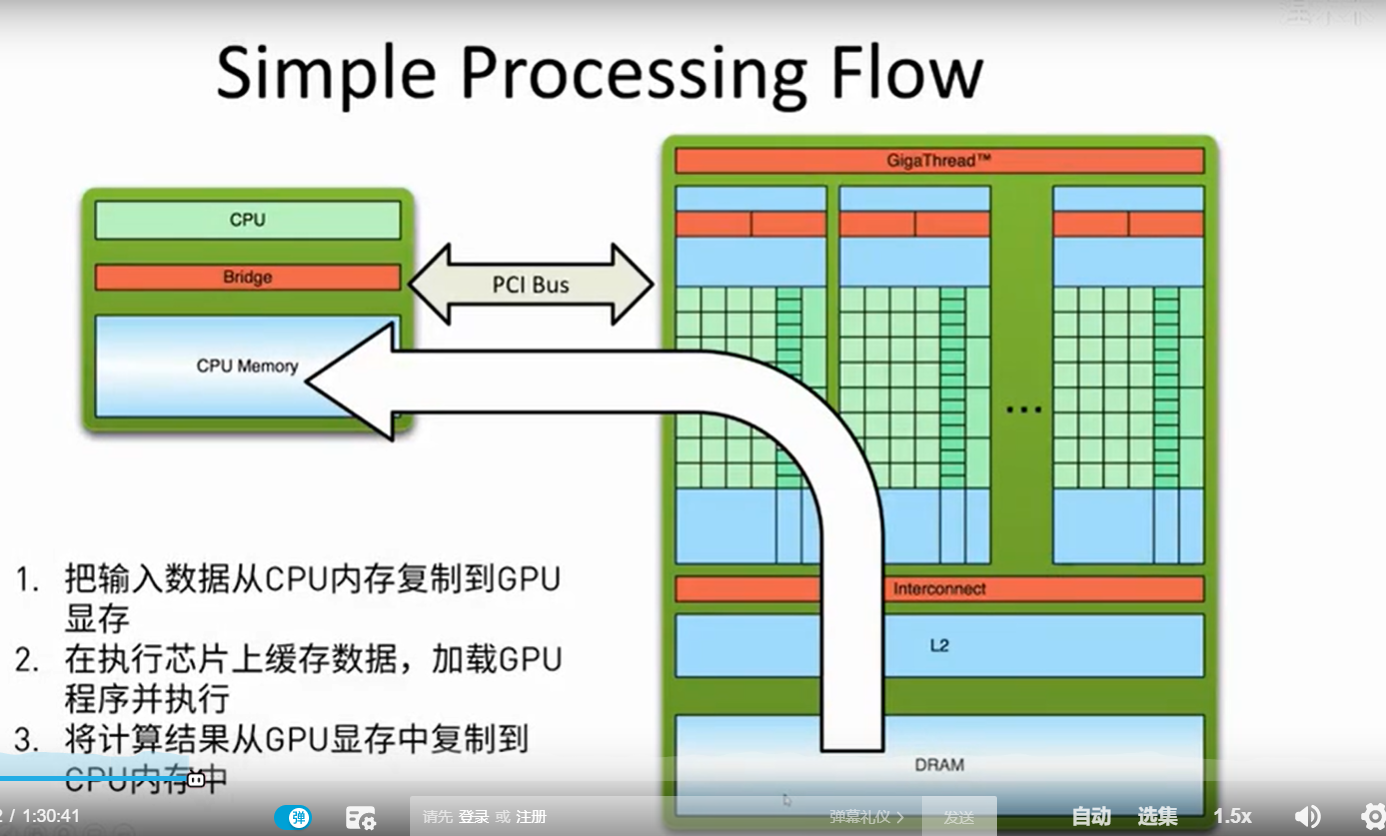
每32 核 共享一个 context, memory. 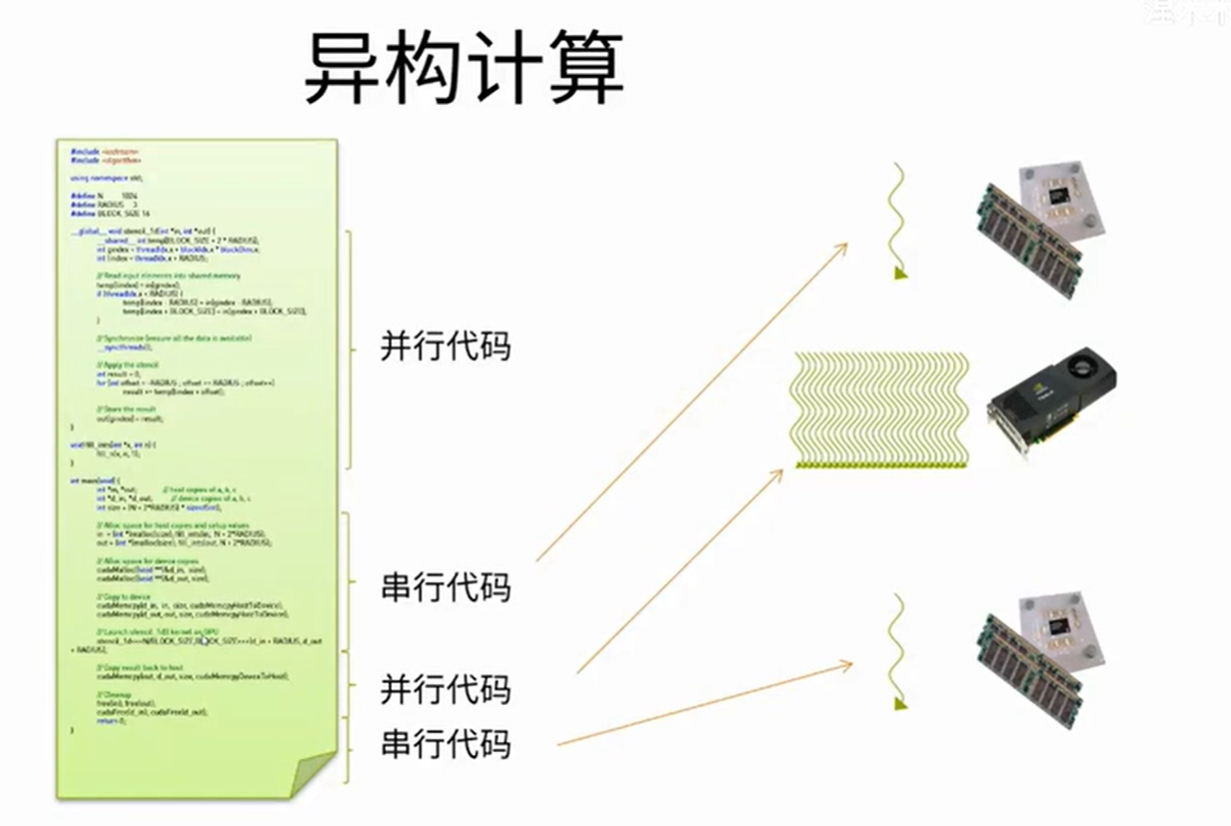




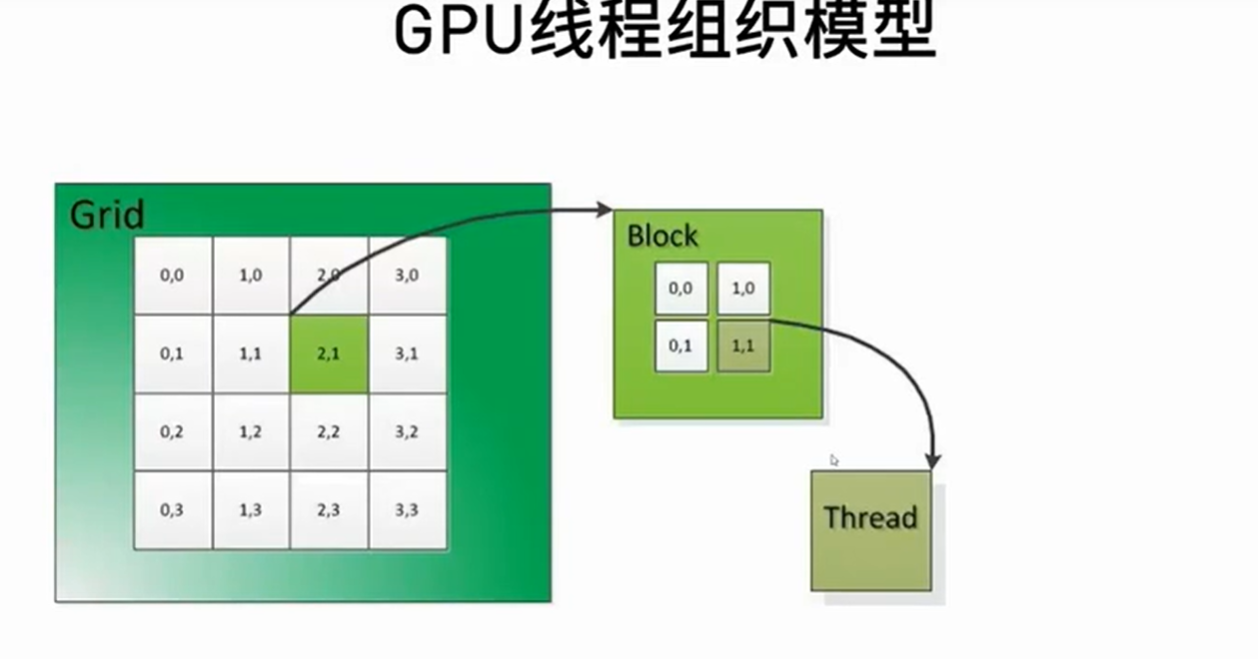

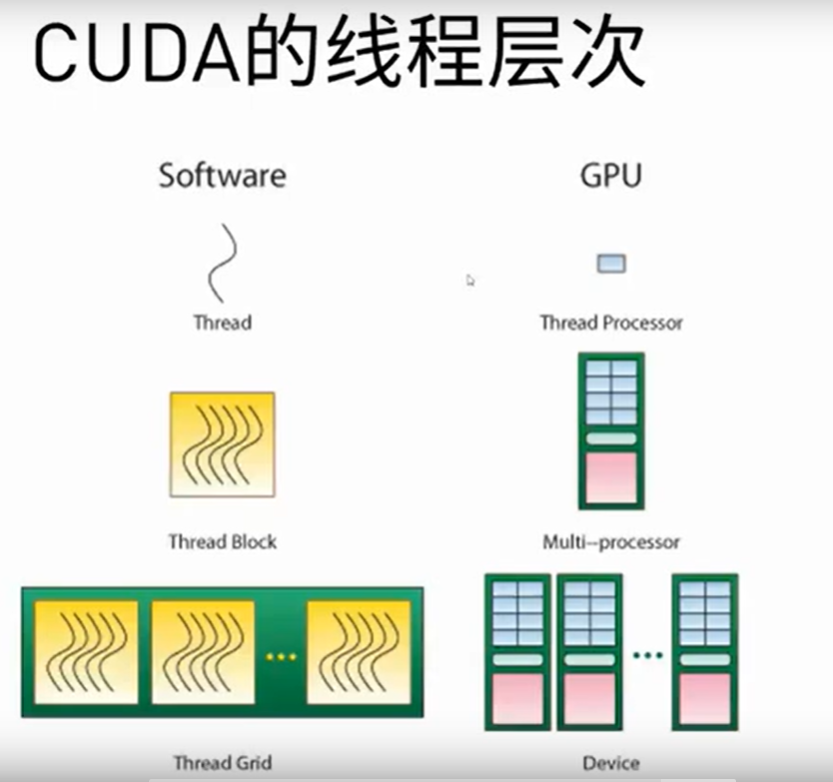

只读: constant memory, texture memory
其余 读写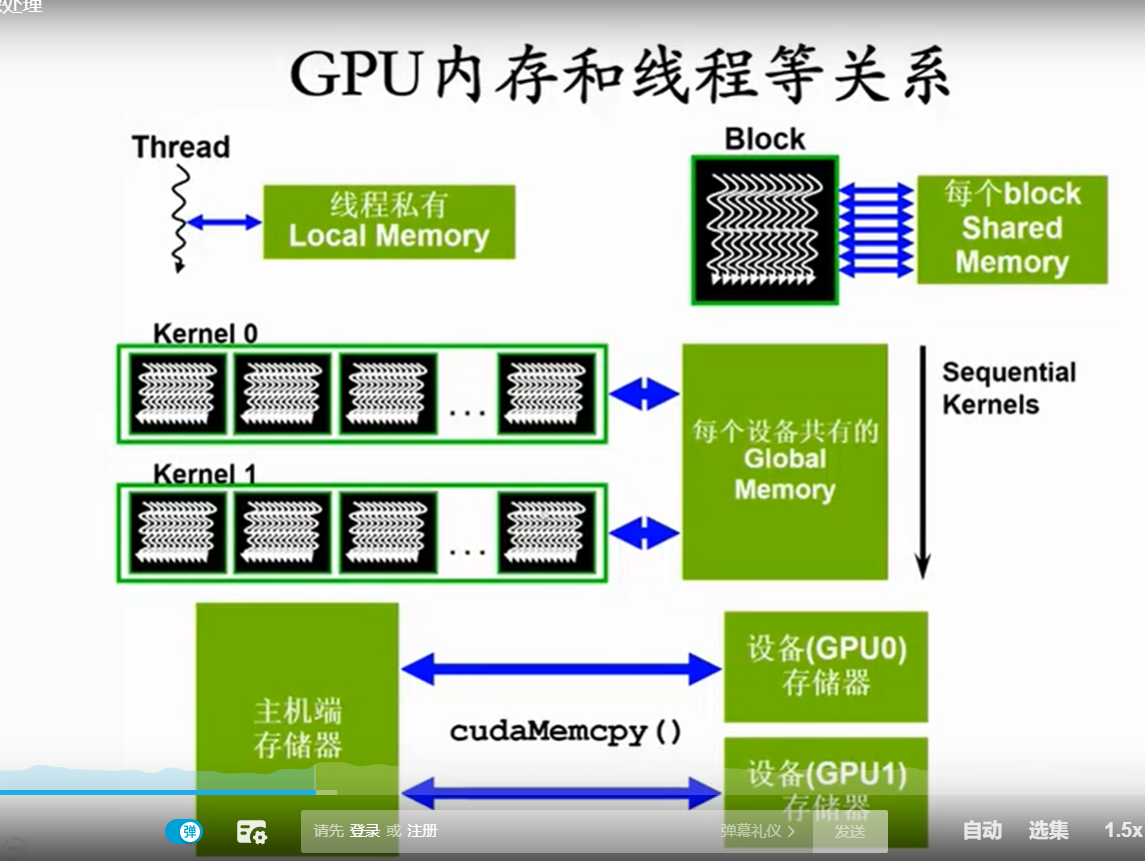
cuda python



install cuda


end

若有收获,就点个赞吧
0 人点赞
