https://www.yuque.com/darrenzhang/qiazqm/gsacw2
https://www.yuque.com/zhangshuhao/notebook/ymp2b7
常用的模型压缩技术有:
(1)奇异值分解(singular value decomposition (SVD))
(2)网络剪枝(Network Pruning)使用网络剪枝和稀疏矩阵
(3)深度压缩(Deep compression)使用网络剪枝,数字化和huffman编码
(4)硬件加速器(hardware accelerator)
在小型化方面常用的手段有:
(1)卷积核分解,使用1×N和N×1的卷积核代替N×N的卷积核
(2)使用bottleneck结构,以SqueezeNet为代表
(3)以低精度浮点数保存,例如Deep Compression
(4)冗余卷积核剪枝及哈弗曼编码
通常进行设计空间探索的方法有:
(1)贝叶斯优化
(2)模拟退火
(3)随机搜索
(4)遗传算法
1.复杂度分析
深度学习模型的复杂度主要体现在计算量、访存量和参数量上。
计算量:即模型完成一次前向传播所需的浮点乘加操作数,其单位通常写作 FLOPs (FLoating-point OPerations)。对卷积神经网络而言,卷积操作通常是整个网络中计算量最为密集的部分,例如 VGG16 [1] 网络 99% 的计算量都来自于其卷积层。假设卷积层的输出特征图空间尺寸为 H × W,输入通道数为 Cin,卷积核个数(输出通道数)为 Cout,每个卷积核空间尺寸为 KH × KW,那么该卷积层的理论计算量为 H × W × KH × KW × Cin × Cout FLOPs。可以看到,卷积层的计算量由输出特征图的大小、卷积核的大小以及输入和输出通道数所共同决定。对输入特征图进行下采样,或者使用更小、更少的卷积核都可以明显降低卷积层的计算量。
访存量:即模型完成一次前向传播过程中发生的内存交换总量,单位是 Byte。访存量的重要性经常会被人们忽视,实际上,模型在逐层进行前向传播的过程中,需要频繁的读写每层的输入特征图、权重矩阵和输出特征图,而读写速度取决于计算平台的内存带宽。如果我们在尝试加速模型的时候,只关注减少模型计算量,而没有等比例减小其访存量,那么依据 Roofline [2] 理论,这将导致模型在实际运行过程中,发生单位内存交换所对应的计算量下降,模型会滑向越来越严重的内存受限状态(即下图中的红色区域),从而无法充分的利用计算平台的算力,因此最后观察到的实际加速比与理论计算量的减小并不成正比。
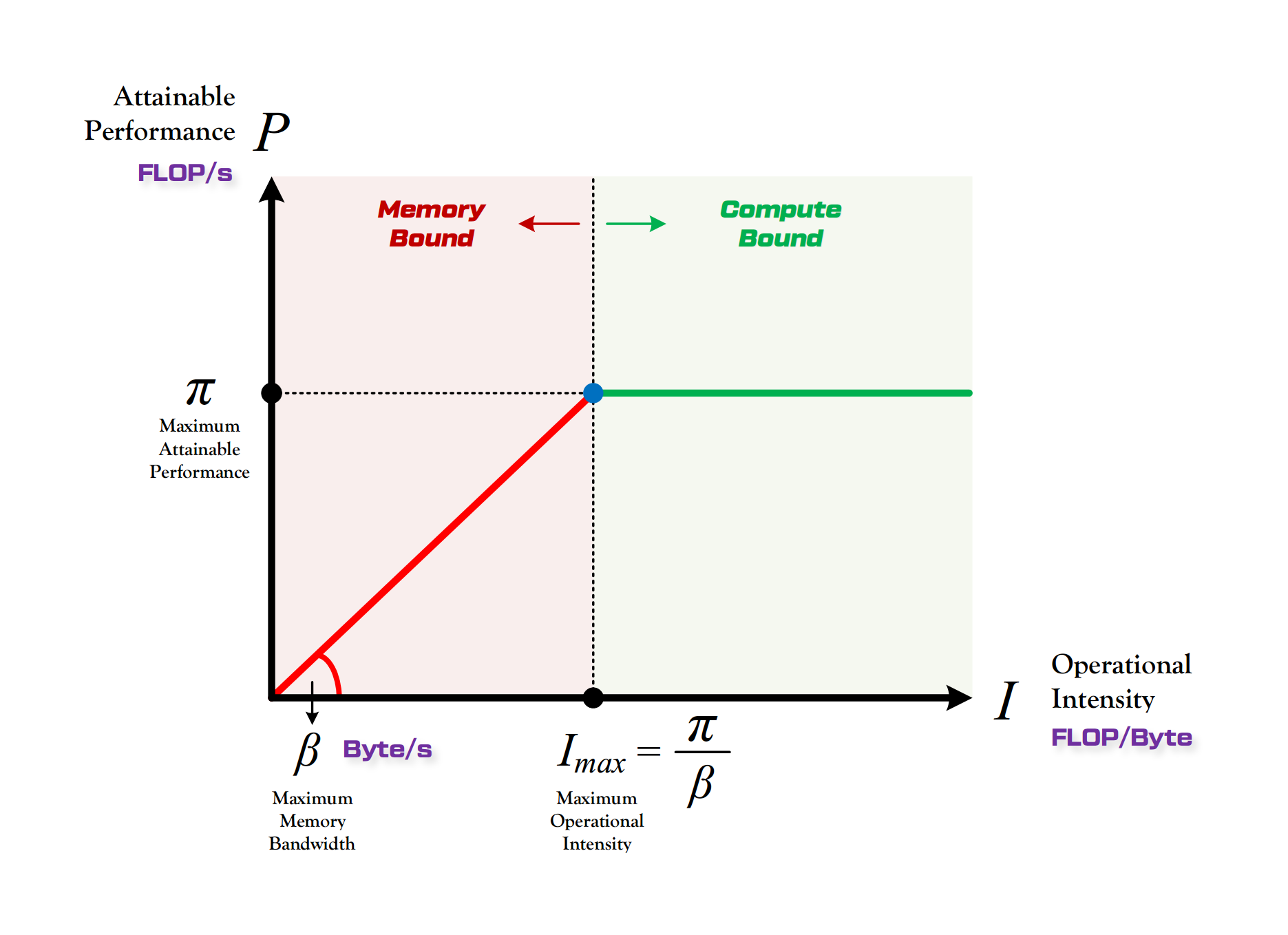
图1:Roofline Model(图中左侧红色区域为带宽受限,右侧绿色区域为算力受限)
- 参数量:即模型所含权重参数的总量,单位是 Byte,表现为模型文件的存储体积大小。全连接层通常是整个网络参数量最为密集的部分,例如 VGG16 网络中超过 80% 的参数都来自于最后三个全连接层。资源严重受限的移动端小型设备会对模型文件的大小较为敏感。
- 并行度:如果以 GPU 作为计算平台,那么由于 GPU 本身所具有的高吞吐特性,模型的并行度会成为影响模型实际运行效率的一个重要方面。模型的并行度越高,意味着模型越能够充分利用 GPU 的算力,执行效率越高。影响并行度的因素有很多,例如模型的计算强度(计算量与访存量的比值)、卷积算法的具体实现方式等,Batch Size 也会显著的影响模型的并行度。
工业界模型要求

模型精简的设计技术要点


若有收获,就点个赞吧
0 人点赞
