start
视频教程
good https://www.bilibili.com/video/BV1r7411n7gQ?p=4&spm_id_from=pageDriver
https://space.bilibili.com/4025066?from=search&seid=13429899630816700615
一、TensorRT理论解释
https://zhuanlan.zhihu.com/p/35657027
TensorRT项目立项的时候名字叫做GPU Inference Engine(简称GIE),
Tensor表示数据流动以张量的形式。所谓张量大家可以理解为更加复杂的高维数组,一般一维数组叫做Vector(即向量),二维数组叫做Matrix,再高纬度的就叫Tensor,Matrix其实是二维的Tensor。在TensoRT中,所有的数据都被组成最高四维的数组,如果对应到CNN中其实就是{N, C, H, W},
- N表示batch size,即多少张图片或者多少个推断(Inference)的实例;
- C表示channel数目;
- H和W表示图像或feature maps的高度和宽度。
- TR表示的是Runtime。
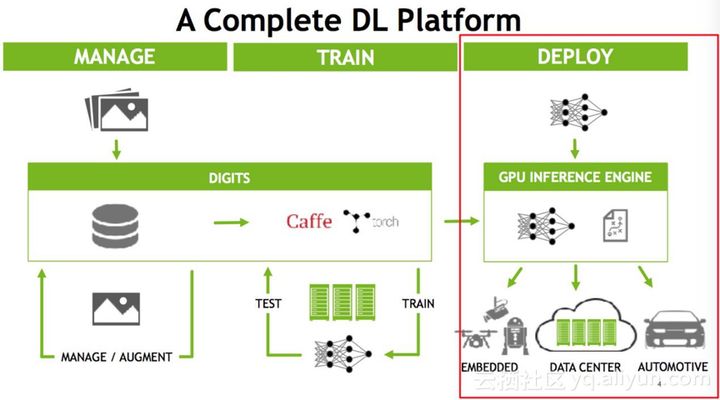
下图是NVDIA针对深度学习平台的一系列完整的解决方案(官网有更新版本)。如果大家对深度学习有些了解的话可能会知道,它分为训练和部署两部分,
1 training
训练部分首先也是最重要的是构建网络结构,准备数据集,使用各种框架进行训练,训练要包含validation和test的过程,最后对于训练好的模型要在实际业务中进行使用。训练的操作一般在线下,实时数据来之后在线训练的情况比较少,大多数情况下数据是离线的,已经收集好的,数据更新不频繁的一天或一周一收集,数据更新频繁的可能几十分钟,在线下有大规模的集群开始对数据或模型进行更新,这样的训练需要消耗大量的GPU,相对而言一般会给一个比较大的batchsize,因为它的实时性要求相对较低,一般训练模型给的是128,甚至有些极端的1024,大的batch的好处是可以充分的利用GPU设备。但是到推断(Inference)的时候就是不同的概念了,推断(Inference)的时候只需要做一个前向计算,将输入通过神经网络得出预测的结果。
1.4 优化_build_phase

1.5 plan_file 部署方案


2 inference—deploy
而推断(Inference)的实际部署有多种可能,可能部署在Data Center(云端数据中心),比如说大家常见的手机上的语音输入,目前都还是云端的,也就是说你的声音是传到云端的,云端处理好之后把数据再返回来;还可能部署在嵌入端,比如说嵌入式的摄像头、无人机、机器人或车载的自动驾驶,当然车载的自动驾驶可能是嵌入式的设备,也可能是一台完整的主机,像这种嵌入式或自动驾驶,它的特点是对实时性要求很高。同样的,Data Center也是对实时性要求很高,做一个语音识别,不能说说完了等很长时间还没有返回,所以在线的部署最大的特点是对实时性要求很高,它对latency非常敏感,要我们能非常快的给出推断(Inference)的结果。做一个不同恰当的比方,训练(Training)这个阶段如果模型比较慢,其实是一个砸钱可以解决的问题,我们可以用更大的集群、更多的机器,做更大的数据并行甚至是模型并行来训练它,重要的是成本的投入。而部署端不只是成本的问题,如果方法不得当,即使使用目前最先进的GPU,也无法满足推断(Inference)的实时性要求。因为模型如果做得不好,没有做优化,可能需要二三百毫秒才能做完一次推断(Inference),再加上来回的网络传输,用户可能一秒后才能得到结果。在语音识别的场景之下,用户可以等待;但是在驾驶的场景之下,可能会有性命之庾。
在部署阶段,latency是非常重要的点,而TensorRT是专门针对部署端进行优化的,目前TensorRT支持大部分主流的深度学习应用,当然最擅长的是CNN(卷积神经网络)领域,但是的TensorRT 3.0也是有RNN的API,也就是说我们可以在里面做RNN的推断(Inference)。
推断(Inference)和训练(Training)的不同
一般的深度学习项目,训练时为了加快速度,会使用多GPU分布式训练。但在部署推理时,为了降低成本,往往使用单个GPU机器甚至嵌入式平台(比如 NVIDIA Jetson)进行部署,部署端也要有与训练时相同的深度学习环境,如caffe,TensorFlow等。
总结一下推断(Inference)和训练(Training)的不同:
1. 推断(Inference)的网络权值已经固定下来,无后向传播过程,因此可以
1)模型固定,可以对计算图进行优化
2) 输入输出大小固定,可以做memory优化(注意:有一个概念是fine-tuning,即训练好的模型继续调优,只是在已有的模型做小的改动,本质上仍然是训练(Training)的过程,TensorRT没有fine-tuning
推断(Inference)的batch size要小很多,仍然是latency的问题,因为如果batch size很大,吞吐可以达到很大,比如每秒可以处理1024个batch,500毫秒处理完,吞吐可以达到2048,可以很好地利用GPU;但是推断(Inference)不能做500毫秒处理,可以是8或者16,吞吐降低,没有办法很好地利用GPU.
推断(Inference)可以使用低精度的技术,训练的时候因为要保证前后向传播,每次梯度的更新是很微小的,这个时候需要相对较高的精度,一般来说需要float型,如FP32,32位的浮点型来处理数据,但是在推断(Inference)的时候,对精度的要求没有那么高,很多研究表明可以用低精度,如半长(16)的float型,即FP16,也可以用8位的整型(INT8)来做推断(Inference),研究结果表明没有特别大的精度损失,尤其对CNN。更有甚者,对Binary(二进制)的使用也处在研究过程中,即权值只有0和1
所以为了提高部署推理的速度,出现了很多轻量级神经网络,比如squeezenet,mobilenet,shufflenet等。基本做法都是基于现有的经典模型提出一种新的模型结构,然后用这些改造过的模型重新训练,再重新部署。
而tensorRT 则是对训练好的模型进行优化。 tensorRT就只是 推理优化器。当你的网络训练完之后,可以将训练模型文件直接丢进tensorRT中,而不再需要依赖深度学习框架(Caffe,TensorFlow等),如下:
(https://www.yuque.com/yilon/ez89w4/tf39qx)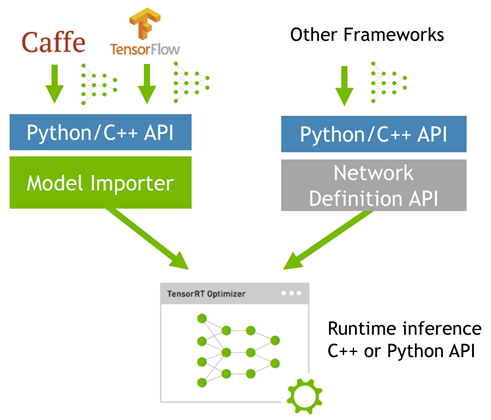
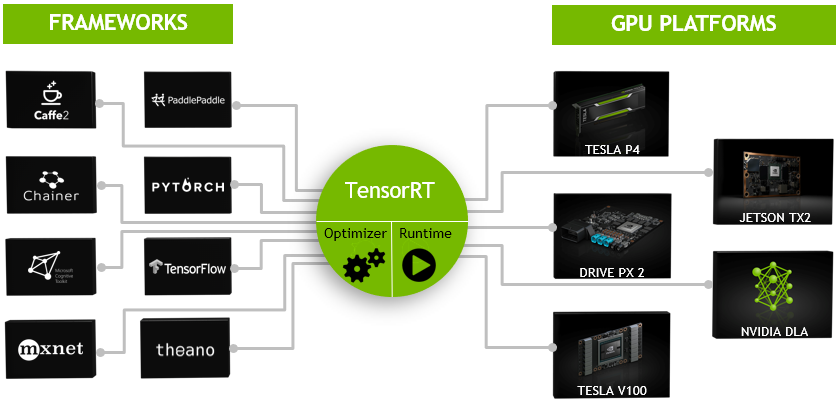
回到TensorRT的主题,之前大家普遍存在的一个疑问是在训练过程中可以使用不同的框架,为什么推断(Inference)不能用各种框架,比如TensorFlow等。当然是可以用的,但是问题是灵活性和性能是一种trade-off的关系,这是在做深度学习或训练过程中经常会遇到的一个问题。比如像TensorFlow的设计初衷是为各种各样的操作来做准备的,在早期的框架,例如Caffe中很多前后处理并不在框架里面完成,而是通过额外的程序或脚本处理,但是TensorFlow支持将所有的操作放入框架之中来完成,它提供了操作(Operation)级别的支持,使得灵活性大大提高,但是灵活性可能是以牺牲效率为代价的。TensorFlow在实现神经网络的过程中可以选择各种各样的高级库,如用nn来搭建,tf.nn中的convolution中可以加一个卷积,可以用slim来实现卷积,不同的卷积实现效果不同,但是其对计算图和GPU都没有做优化,甚至在中间卷积算法的选择上也没有做优化,而TensorRT在这方面做了很多工作。
在讲TensorRT做了哪些优化之前, 想介绍一下TensorRT的流程, 首先输入是一个预先训练好的FP32的模型和网络,将模型通过parser等方式输入到TensorRT中,TensorRT可以生成一个Serialization,也就是说将输入串流到内存或文件中,形成一个优化好的engine,执行的时候可以调取它来执行推断(Inference)。
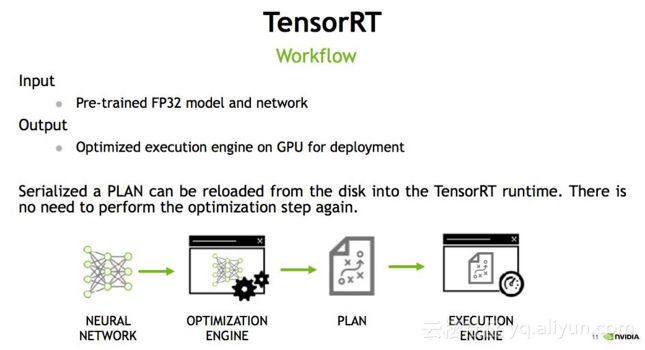
API 使用过程


如上图所示TensorRT整个过程可以分三个步骤,即模型的解析(Parser),Engine优化和执行(Execution)。暂时抛开TensorRT,如果让大家从头写一个深度学习模型的前向过程,具体过程应该是
1) 首先实现NN的layer,如卷积的实现,pooling的实现。
2) 管理memory,数据在各层之间如何流动。
3) 推断(Inference)的engine来调用各层的实现。
以上三个步骤在TendorRT都已经实现好了,用户需要做的是如何将网络输入到TensorRT中。目前TensorRT支持两种输入方式:
1. 一种是Parser的方式,即模型解析器,输入一个caffe的模型,可以解析出其中的网络层及网络层之间的连接关系,然后将其输入到TensorRT中,但是TensorRT是如何知道这些连接关系呢?答案是API。
2. API接口可以添加一个convolution或pooling。而Parser是解析模型文件,比如TensorFlow转换成的uff,或者是caffe的模型,再用API添加到TensorRT中,构建好网络。构建好后就可以做优化。
a) 考虑到一个情况,如果有一个网络层不支持,这个有可能,TensorRT只支持主流的操作,比如说一个神经网络专家开发了一个新的网络层,新型卷积和以前的卷积都不一样,TensorRT是不知道是做什么的。比如说最常见的检测网络,有一些网络层也是不支持的,这个时候涉及到customer layer的功能,即用户自定义层,构建用户自定义层需要告诉TensorRT该层的连接关系和实现方式,这样TensorRT才能去做。
b) 目前API支持两种接口实现方式,一种是C++,另一种是Python,Python接口可能在一些快速实现上比较方便一些。
c) Parser目前有三个,
- 一个是caffe Parser,这个是最古老的也是支持最完善的;
- 另一个是uff,这个是NV定义的网络模型的一种文件结构,现在TensorFlow可以直接转成uff;
- 第三个 onnx,ONNX(Open Neural Network Exchange )是微软和Facebook携手开发的开放式神经网络交换工具,也就是说不管用什么框架训练,只要转换为ONNX模型,就可以放在其他框架上面去inference。这是一种统一的神经网络模型定义和保存方式,上面提到的除了tensorflow之外的其他框架官方应该都对onnx做了支持,而ONNX自己开发了对tensorflow的支持。从深度学习框架方面来说,这是各大厂商对抗谷歌tensorflow垄断地位的一种有效方式;从研究人员和开发者方面来说,这可以使开发者轻易地在不同机器学习工具之间进行转换,并为项目选择最好的组合方式,加快从研究到生产的速度。
如果某个公司新推出一个特别火的框架不支持怎么办,仍然可以采用API的方式,一层一层的添加进去,告诉TensorRT连接关系,这也是OK的。
模型解析后,engine会进行优化,具体的优化稍后会介绍。得到优化好的engine可以序列化到内存(buffer)或文件(file),读的时候需要反序列化,将其变成engine以供使用。然后在执行的时候创建context,主要是分配预先的资源,engine加context就可以做推断(Inference)。
以上是TensorRT的整个过程,大家在疑惑TensorRT是否支持TensorFlow,首先大家写的网络计算层可能都是支持的,但是有些网络层可能不支持,在不支持的情况下可以用customer layer的方式添加进去,但是有时候为了使用方便,可能没办法一层一层的去添加,需要用模型文件形式,这个取决于Parser是否完全支持。相对而言,大家在框架有过比较后会发现,caffe这个框架的特点是非常不灵活,如果要添加一个新的网络层,需要修改源代码;TensorFlow的优点却是非常的灵活
3. TensorRT支持的Layer
3.1 Caffe
这些是Caffe框架中支持的OP。
- BatchNormalization。
- BNLL。
- Clip。
- Concatenation。
- Convolution。
- Crop。
- Deconvolution。
- Dropout。
- ElementWise。
- ELU。
- InnerProduct。
- Input。
- LeakyReLU。
- LRN。
- Permute。
- Pooling。
- Power。
- Reduction。
- ReLU,TanH,和Sigmoid。
- Reshape。
- SoftMax。
-
3.2 TensorFlow
这些是TensorFlow中支持的OP。
Add, Sub, Mul, Div, Minimum and Maximum。
- ArgMax。
- ArgMin。
- AvgPool。
- BiasAdd。
- Clip。
- ConcatV2。
- Const。
- Conv2d。
- ConvTranspose2D。
- DepthwiseConv2dNative。
- Elu。
- ExpandDims。
- FusedBatchNorm。
- Identity。
- LeakyReLU。
- MaxPool。
- Mean。
- Negative, Abs, Sqrt, Recip, Rsqrt, Pow, Exp and Log。
- Pad is supported if followed by one of these TensorFlow layers: Conv2D, DepthwiseConv2dNative, MaxPool, and AvgPool.
- Placeholder
- ReLU, TanH, and Sigmoid。
- Relu6。
- Reshape。
- ResizeBilinear, ResizeNearestNeighbor。
- Sin, Cos, Tan, Asin, Acos, Atan, Sinh, Cosh, Asinh, Acosh, Atanh, Ceil and Floor。
- Selu。
- Slice。
- SoftMax。
- Softplus。
- Softsign。
-
为什么TensorRT能让模型跑的快?
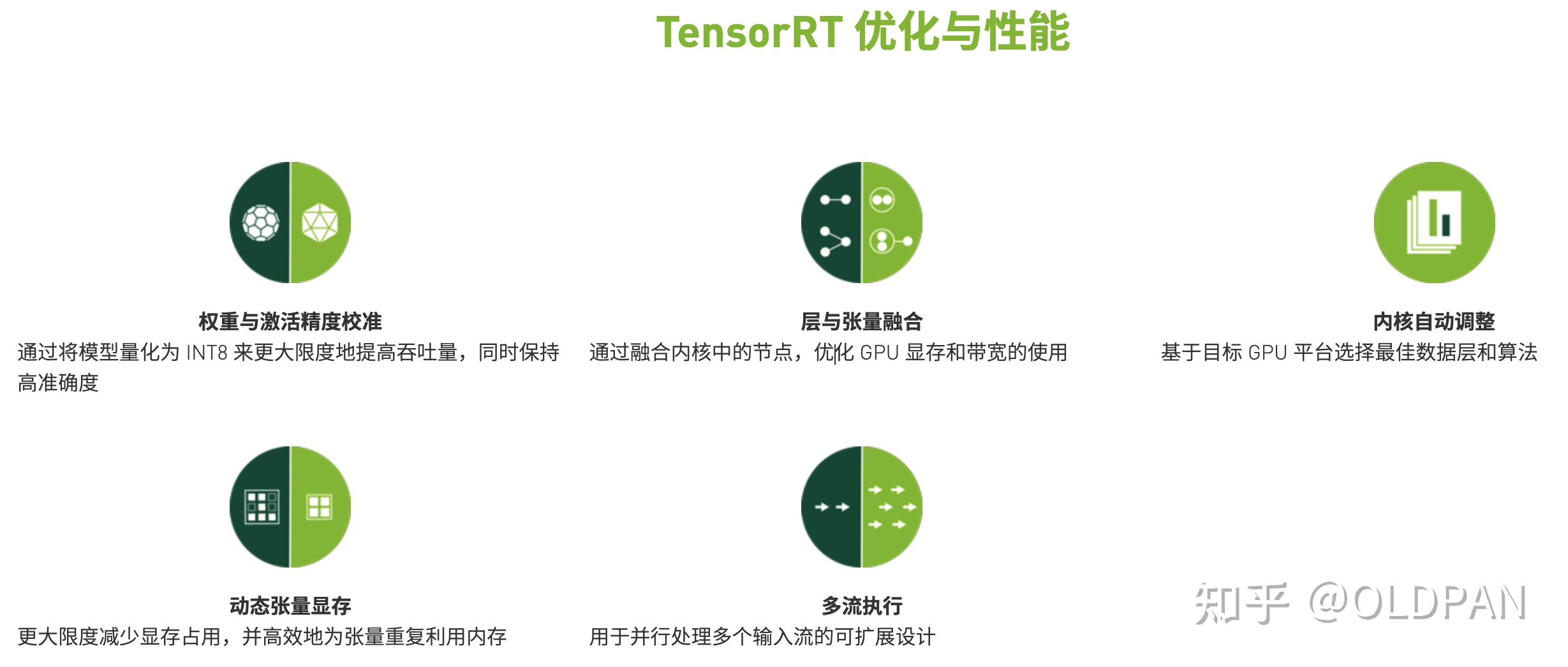
算子融合(层与张量融合):简单来说就是通过融合一些计算op或者去掉一些多余op来减少数据流通次数以及显存的频繁使用来提速
- 量化:量化即IN8量化或者FP16以及TF32等不同于常规FP32精度的使用,这些精度可以显著提升模型执行速度并且不会保持原先模型的精度
- 内核自动调整:根据不同的显卡构架、SM数量、内核频率等(例如1080TI和2080TI),选择不同的优化策略以及计算方式,寻找最合适当前构架的计算方式
- 动态张量显存:我们都知道,显存的开辟和释放是比较耗时的,通过调整一些策略可以减少模型中这些操作的次数,从而可以减少模型运行的时间
- 多流执行:使用CUDA中的stream技术,最大化实现并行操作
这一问题的答案就隐藏下面这张图中: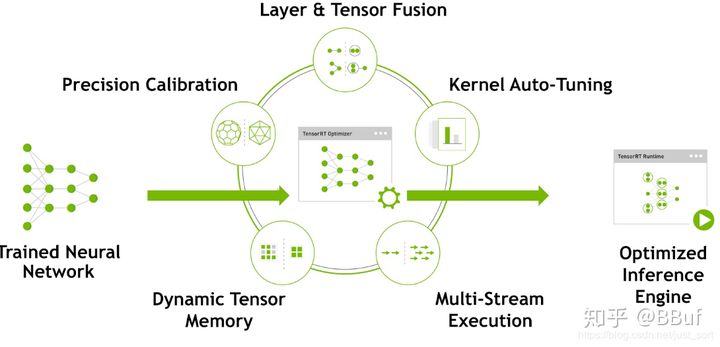
从图上可以看到,TensorRT主要做了下面几件事,来提升模型的运行速度。
- TensorRT支持FP16和INT8的计算。我们知道深度学习在训练的时候一般是应用32位或者16位数据,TensorRT在推理的时候可以降低模型参数的位宽来进行低精度推理,以达到加速推断的目的。这在后面的文章中是重点内容,笔者经过一周的研究,大概明白了TensorRT INT8量化的一些细节,后面会逐渐和大家一起分享讨论。
- TensorRT对于网络结构进行重构,把一些能够合并的运算合并在了一起,针对GPU的特性做了优化。大家如果了解GPU的话会知道,在GPU上跑的函数叫Kernel,TensorRT是存在Kernel的调用的。在绝大部分框架中,比如一个卷积层、一个偏置层和一个reload层,这三层是需要调用三次cuDNN对应的API,但实际上这三层的实现完全是可以合并到一起的,TensorRT会对一些可以合并网络进行合并;再比如说,目前的网络一方面越来越深,另一方面越来越宽,可能并行做若干个相同大小的卷积,这些卷积计算其实也是可以合并到一起来做的。(加粗的话转载自参考链接1)。
- 然后Concat层是可以去掉的,因为TensorRT完全可以实现直接接到需要的地方。
- Kernel Auto-Tuning:网络模型在推理计算时,是调用GPU的CUDA核进行计算的。TensorRT可以针对不同的算法,不同的网络模型,不同的GPU平台,进行 CUDA核的调整,以保证当前模型在特定平台上以最优性能计算。
- Dynamic Tensor Memory 在每个tensor的使用期间,TensorRT会为其指定显存,避免显存重复申请,减少内存占用和提高重复使用效率。
- 不同的硬件如P4卡还是V100卡甚至是嵌入式设备的卡,TensorRT都会做优化,得到优化后的engine。
下面是一个原始的Inception Block,首先input后会有多个卷积,卷积完后有Bias和ReLU,结束后将结果concat到一起,得到下一个input。我们一起来看一下使用TensorRT后,这个原始的计算图会被优化成了什么样子。
首先,在没有经过优化的时候Inception Block如Figure1所示: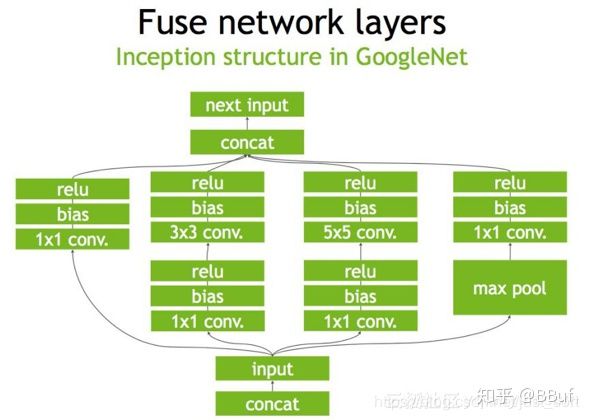
第二步,对于网络结构进行垂直整合,即将目前主流神经网络的conv、BN、Relu三个层融合为了一个层,所谓CBR,合并后就成了Figure2中的结构。
第三步,TensorRT还可以对网络做水平组合,水平组合是指将输入为相同张量和执行相同操作的层融合一起,下面的Figure3即是将三个相连的 的CBR为一个大的
的CBR为一个大的 的CBR。
的CBR。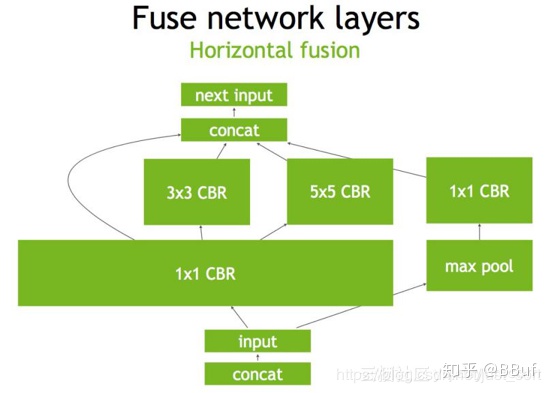
最后,对于concat层,将contact层的输入直接送入下面的操作中,不用单独进行concat后在输入计算,相当于减少了一次传输吞吐,然后就获得了如Figure4所示的最终计算图。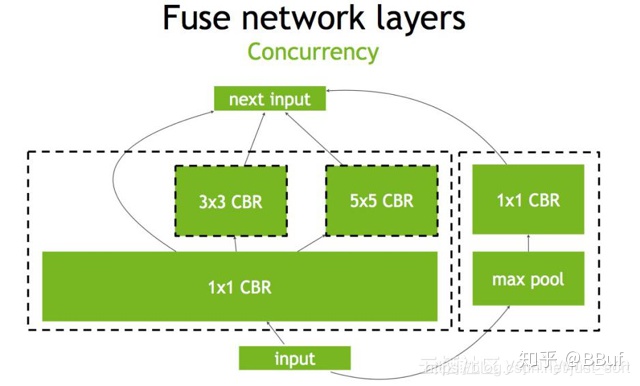
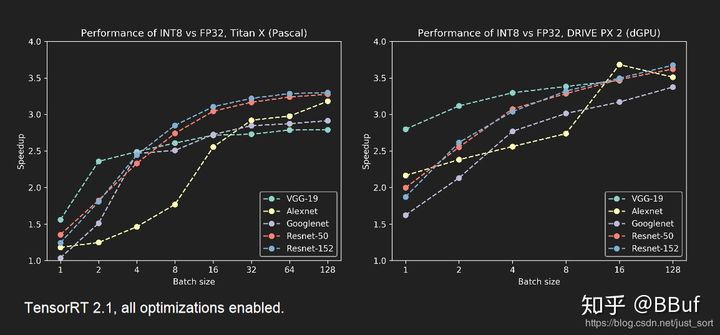
除了计算图和底层优化,最重要的就是低精度推理了,这个后面会细讲的,我们先来看一下使用了INT8低精度模式进行推理的结果展示:包括精度和速度。来自NIVIDA提供的PPT。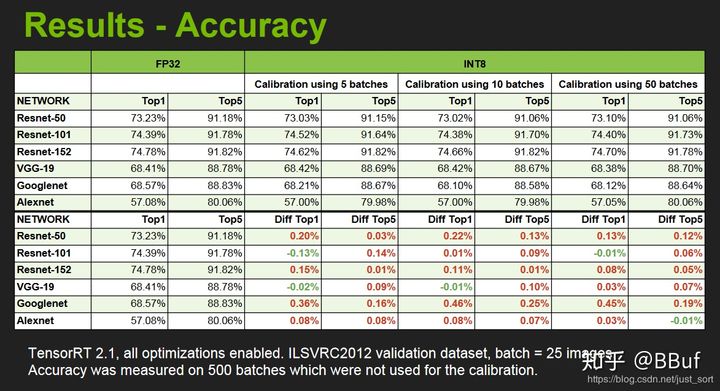
名词解释
builder:
构建器,搜索cuda内核目录以获得最快的可用实现,必须使用和运行时的GPU相同的GPU来构建优化引擎。在构建引擎时,TensorRT会复制权重。
IBuilder builder = createInferBuilder(gLogger);
INetworkDefinition network = builder->createNetwork();
创建引擎
builder->setMaxBatchSize(maxBatchSize);
builder->setMaxWorkspaceSize(1 << 20); I
CudaEngine engine = builder->buildCudaEngine(network);
engine:
引擎,不能跨平台和TensorRT版本移植。若要存储,需要将引擎转化为一种格式,即序列化,若要推理,需要反序列化引擎。引擎用于保存网络定义和模型参数。
IHostMemory serializedModel = engine->serialize();
// store model to disk
std::ofstream p(“resnet18.engine”);
p.write(reinterpret_cast<const char>(modelStream->data()), modelStream->size());
// <…>
serializedModel->destroy();
context:
上下文,创建一些空间来存储中间值。一个engine可以创建多个context,分别执行多个推理任务。
IExecutionContext *context = engine->createExecutionContext();
runtime:
用于反序列化引擎。
IRuntime runtime = createInferRuntime(gLogger); ICudaEngine engine = runtime->deserializeCudaEngine(modelData, modelSize, nullptr);
边界条件
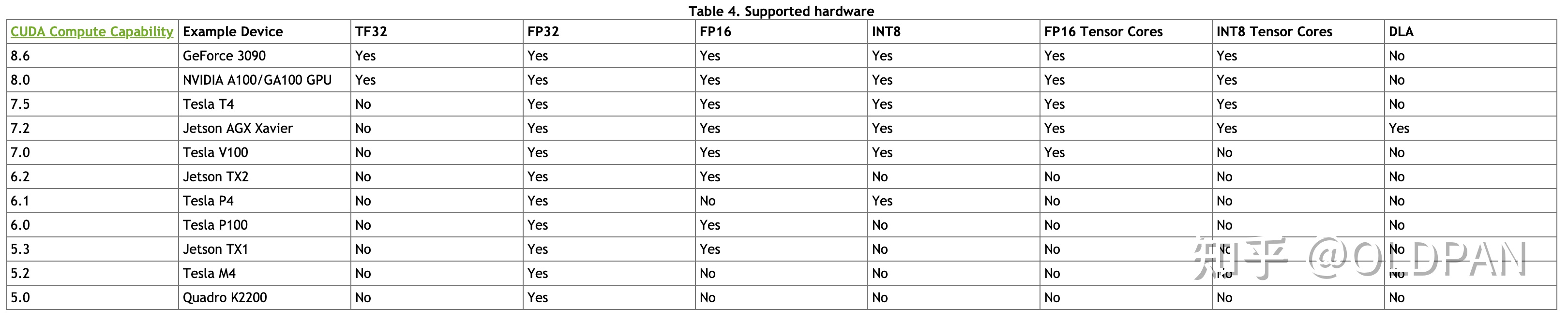
support-matrix https://docs.nvidia.com/deeplearning/tensorrt/support-matrix/index.html
只能用在NIVDIA的GPU上的推理框架
此处为 边界(https://docs.nvidia.com/deeplearning/tensorrt/developer-guide/index.html#api)
系统
TensorRT provides a C++ implementation on all supported platforms, and a Python implementation on Linux. Python is not currently supported on Windows or QNX.
AI framework
TensorRT enables developers to import, calibrate, optimize, and deploy deep learning models. Models can be imported from frameworks like TensorFlow and PyTorch via the ONNX format. They may also be created programmatically by instantiating individual layers and setting parameters and weights directly.
With the Python API, an existing model built with TensorFlow, Caffe, or an ONNX compatible framework can be used to build a NVIDIA® TensorRT™ engine using the provided parsers. The Python API also supports frameworks that store layer weights in a NumPy compatible format, for example, PyTorch.
PyTorch models can be exported to ONNX which can then be consumed by TensorRT.
hardware
相关问题
TensorRT详细入门指北
https://zhuanlan.zhihu.com/p/371239130
TensorRT是硬件相关的
这个很好明白,因为不同显卡(不同GPU),其核心数量、频率、架构、设计(还有价格..)都是不一样的,TensorRT需要对特定的硬件进行优化,不同硬件之间的优化是不能共享的。
The generated plan files are not portable across platforms or TensorRT versions. Plans are specific to the exact GPU model they were built on (in addition to platforms and the TensorRT version) and must be re-targeted to the specific GPU in case you want to run them on a different GPU
TensorRT版本相关
TensorRT的版本与CUDA还有CUDNN版本是密切相关的,我们从官网下载TensorRT的时候应该就可以注意到: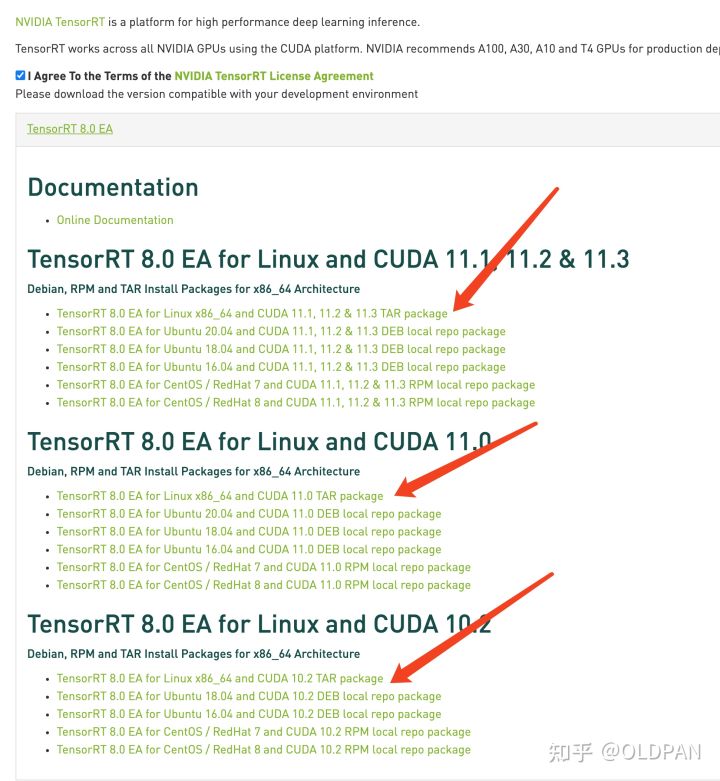
不匹配版本的cuda以及cudnn是无法和TensorRT一起使用的。
所以下载的时候要注意,不要搞错版本了哦。
关于如何选择合适自己的TensorRT版本,首先看驱动,其次看CUDA版本。
驱动怎么看,使用nvidia-smi命令即可:
TensorRT的缺点
TensorRT不是没有“缺点”的,有一些小小的缺点需要吐槽一下:
- 经过infer优化后的模型与特定GPU绑定,例如在1080TI上生成的模型在2080TI上无法使用;
- 高版本的TensorRT依赖于高版本的CUDA版本,而高版本的CUDA版本依赖于高版本的驱动,如果想要使用新版本的TensorRT,更换环境是不可避免的;
- TensorRT尽管好用,但推理优化infer还是闭源的,像深度学习炼丹一样,也像个黑盒子,使用起来会有些畏手畏脚,不能够完全掌控。所幸TensorRT提供了较为多的工具帮助我们调试。
正所谓爱之深恨之切,老潘也知道,这些”缺点“也是没有办法的缺点,既然无法避免,就轻轻吐槽一下吧
关键接口

tensorflow与tersorRT的input格式不一

end

若有收获,就点个赞吧
0 人点赞
