hadoop是一个分布式的框架:
由三个模块组成:分布式存储HDFS、分布式计算MapReduce、资源调度引擎Yarn
1.hdfs:分布式文件系统
文件系统:管理计算机硬盘上面的各种文件 avi文件,torrent文件 各种文件等等
操作系统,windows操作系统:文件管理系统
主节点:namenode 主要负责管理整个集群,以及维护集群当中的元数据信息
从节点:datanode 主要用于保存数据,说白了就是一块硬盘/服务器
1.2 hdfs的架构详细剖析
hdfs如何实现分布式文件的存储:都是抽象成为block块,hadoop3.0一个block的大小默认为512M,可设置
blockpool:专门用于管理block块 类似于一个水桶,水桶里面最多可以装128斤水,但是你也可以只装1斤
1.3 hdfs的shell命令操作
hdfs dfs -rm -skipTrash /xcall
使用这个命令,跳过hdfs的垃圾桶删除文件
hdfs dfs -rmr -skipTrash /hello.txt
1.4 hdfs的安全模式
- 安全模式是hdfs的一种保护机制,主要是为了保存block块数量的完整性,避免数据出现丢失的可能性
- 集群启动的时候,会去检查block块的完整性
- 如果block块不完整,有丢失,需要进入到安全模式,对外不提供写入数据的功能,只提供读取数据的功能,进行block快的修复,复制等等的工作
1.5 hdfs的javaAPI的开发:
具体教程可跳转这里
需要构建windows的开发环境:
1、需要在windows安装jdk
2、需要在windows安装maven
3、需要在windows安装idea
4、需要在windows配置hadoop的环境变量
2.MapReduce
- MapReduce是很多大数据组建的基础,包括Flink等
- 一个分布式运算程序的编程框架,是用户开发“基于Hadoop的数据分析应用”的核心框架。
- MapReduce思想在生活中处处可见。或多或少都曾接触过这种思想。MapReduce的思想核心是“分而治之”,适用于大量复杂的任务处理场景(大规模数据处理场景)。
- Map负责“分”,即把复杂的任务分解为若干个“简单的任务”来并行处理。可以进行拆分的前提是这些==小任务可以并行计算,彼此间几乎没有依赖关系。==
- Reduce负责“合”,即对map阶段的结果进行全局汇总。
-
mapreduce编程指导思想(八个步骤背下来)
MapReduce的开发一共有八个步骤其中map阶段分为2个步骤,shuffle阶段4个步骤,reduce阶段分为2个步骤
1. Map阶段2个步骤
第一步:设置inputFormat类,将数据切分成key,value对,输入到第二步
第二步:自定义map逻辑,处理我们第一步的输入kv对数据,然后转换成新的key,value对进行输出
2. shuffle阶段4个步骤
第三步:对上一步输出的key,value对进行分区。(相同key的kv对属于同一分区)
- 第四步:对每个分区的数据按照key进行排序
- 第五步:对分区中的数据进行规约(combine操作),降低数据的网络拷贝(可选步骤)
第六步:对排序后的kv对数据进行分组;分组的过程中,key相同的kv对为一组;将同一组的kv对的所有value放到一个集合当中(每组数据调用一次reduce方法)
3. reduce阶段2个步骤
第七步:对多个map的任务进行合并,排序,写reduce函数自己的逻辑,对输入的key,value对进行处理,转换成新的key,value对进行输出
- 第八步:设置将输出的key,value对数据保存到文件中
3.YARY分布式集群资源管理调度工具
主要用于管理集群资源,包括cpu以及内存等等
区别于Zookeeper:只是一个分布式服务管理框架,更多的是注册,不涉及资源管理
Apache Hadoop YARN(Yet Another Resource Negotiator)是Hadoop的子项目,为分离Hadoop2.0资源管理和计算组件而引入- YRAN具有足够的通用性,可以支持其它的分布式计算模式
类似HDFS,YARN也是经典的主从(master/slave)架构
- YARN服务由一个ResourceManager(RM)和多个NodeManager(NM)构成
- ResourceManager为主节点(master)
- NodeManager为从节点(slave)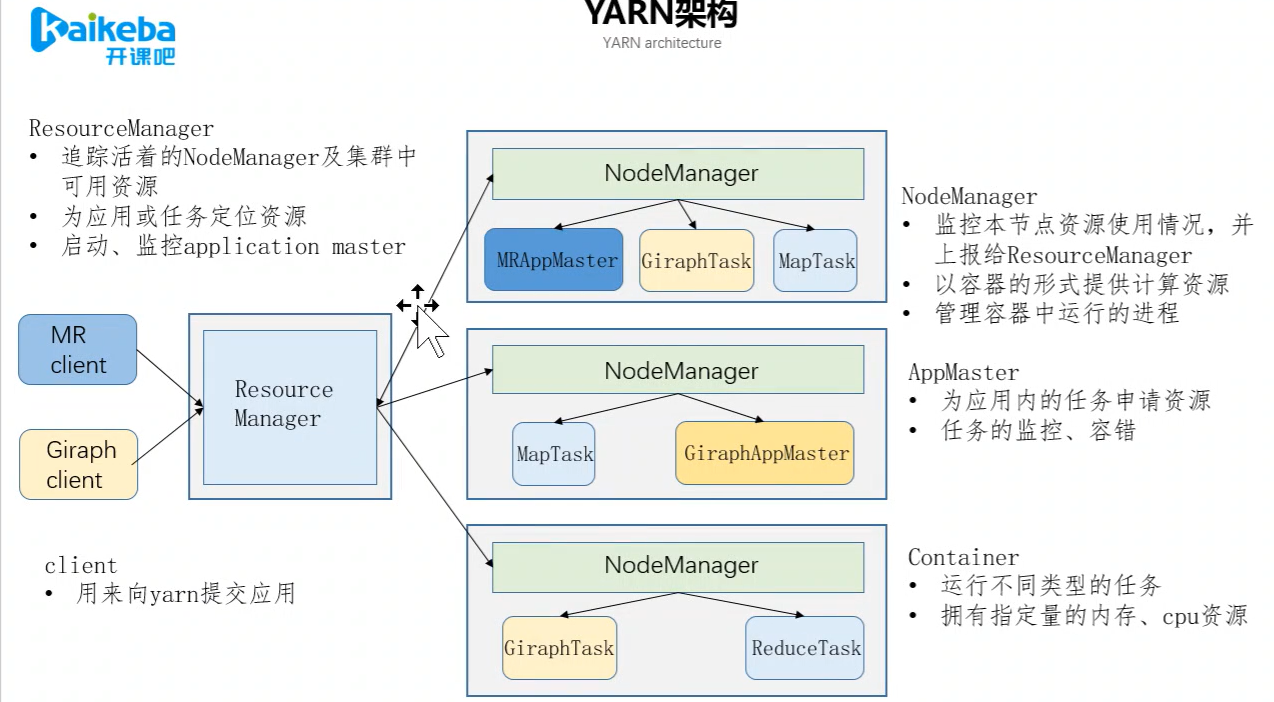
4.Hive
- Hive是基于Hadoop的一个数据仓库工具
- 可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。
- 其本质是将SQL转换为MapReduce的任务进行运算,底层由HDFS来提供数据的存储支持,说白了hive可以理解为一个将SQL转换为MapReduce任务的工具,甚至更进一步可以说hive就是一个MapReduce的客户端
- 这里必须讲下MapReduce是一栋大厦的基底,学和用Hive都需要站在MapReduce这个巨人的肩膀上。(虽然偶还只是懂原理,还没啃源码,打算留在寒假慢慢啃)
- Hive 只适合用来做海量离线数据统计分析,也就是数据仓库
5-分布式服务管理框架Zookeeper
1. 什么是ZooKeeper?(5分钟)
- 是Google的Chubby的一个开源实现版
- ZooKeeper
- 一个主从架构的分布式框架、开源的
- 对其他的分布式框架的提供协调服务(service),如hdfs的高可用方案
Zookeeper 作为一个分布式的服务框架
分布式框架多个独立的程序协同工作比较复杂
- 开发人员容易花较多的精力实现如何使多个程序协同工作的逻辑
- 导致没有时间更好的思考实现程序本身的逻辑
- 或者开发人员对程序间的协同工作关注不够,造成协调问题
- 且分布式框架中协同工作的逻辑是==共性的==需求
ZooKeeper简单易用,能够很好的解决分布式框架在运行中,出现的各种协调问题。
HBase基于Google的BigTable论文,是建立的==HDFS==之上,提供高可靠性、高性能、列存储、可伸缩、实时读写的分布式数据库系统。
在需要==实时读写随机访问==超大规模数据集时,可以使用HBase。
1.2 HBase的特点
==海量存储==
- 可以存储大批量的数据
- ==列式存储==
- HBase表的数据是基于列族进行存储的,列族是在列的方向上的划分。
- ==极易扩展==
- 底层依赖HDFS,当磁盘空间不足的时候,只需要动态增加datanode节点就可以了
- 可以通过增加服务器来对集群的存储进行扩容
- ==高并发==
- 支持高并发的读写请求
- ==稀疏==
- 稀疏主要是针对HBase列的灵活性,在列族中,你可以指定任意多的列,在列数据为空的情况下,是不会占用存储空间的。
- ==数据的多版本==
- HBase表中的数据可以有多个版本值,默认情况下是根据版本号去区分,版本号就是插入数据的时间戳
==数据类型单一==
Flume是一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统。
- Flume可以采集文件,socket数据包、文件、文件夹、kafka等各种形式源数据,又可以将采集到的数据(下沉sink)输出到HDFS、hbase、hive、kafka等众多外部存储系统中
- 一般的采集需求,通过对flume的简单配置即可实现
Flume针对特殊场景也具备良好的自定义扩展能力,因此,flume可以适用于大部分的日常数据采集场景
2. 运行机制
Flume分布式系统中最核心的角色是agent,flume采集系统就是由一个个agent所连接起来形成的
- 每一个agent相当于一个数据传递员,内部有三个组件:
9-数据传输框架Sqoop
1. 概述
Sqoop是apache旗下的一款 ”Hadoop和关系数据库之间传输数据”的工具导入数据:将MySQL,Oracle导入数据到Hadoop的HDFS、HIVE、HBASE等数据存储系统导出数据:从Hadoop的文件系统中导出数据到关系数据库
2. Sqoop的工作机制
将导入和导出的命令翻译成mapreduce程序实现
- 在翻译出的mapreduce中主要是对inputformat和outputformat进行定制
10-任务调度框架Azkaban
Azkaban介绍
- Azkaban是由Linkedin开源的一个批量工作流任务调度器。用于在一个工作流内以一个特定的顺序运行一组工作和流程。
- Azkaban定义了一种KV文件(properties)格式来建立任务之间的依赖关系,并提供一个易于使用的web用户界面维护和跟踪你的工作流。
它有如下功能特点:
Azkaban由三部分构成
MR中间结果需要读写磁盘,MR是进程级别的,spark是线程级别的,这个只需要基于内存的分布式内存计算框架
- 基本tmdj、bat都在用
- 比Hadoop快
Spark是一个快速(基于内存),通用、可扩展的计算引擎,采用Scala语言编写。2009年诞生于UC Berkeley(加州大学伯克利分校,CAL的AMP实验室),2010年开源,2013年6月进入Apach孵化器,同年由美国伯克利大学 AMP 实验室的 Spark 大数据处理系统多位创始人联合创立Databricks(属于 Spark 的商业化公司-业界称之为数砖-数据展现-砌墙-侧面应正其不是基石,只是数据计算),2014年成为Apach顶级项目,自2009年以来,已有1200多家开发商为Spark出力!
12-多范式编程语言Scala
1. scala简介
- scala是运行在 JVM 上的多范式编程语言,同时支持==面向对象==和==面向函数编程==
- scala大概是在==2003年==才正式诞生,而java的诞生可以追溯到1995年
- 早期scala刚出现的时候,并没有怎么引起重视,随着==Spark==(2010开源、2014成为apache顶级项目)和==Kafka==这样基于scala的大数据框架的兴起,scala逐步进入大数据开发者的眼帘。
- scala的主要优势是它的==表达性==。
官网地址
- http://www.scala-lang.org
2. 为什么要使用scala
- http://www.scala-lang.org
开发大数据应用程序(Spark程序、Flink程序)
- 表达能力强,一行代码抵得上Java多行,开发速度快
- 兼容Java,可以访问庞大的Java类库
13-Flink生态体系
- Apache Flink 是一个分布式大数据处理引擎,可对有界数据流和无界数据流进行有状态的计算。能够部署在各种集群环境,对各种规模大小的数据进行快速计算。
- 区别于Spark,它是真正意义上的流处理框架,能实现对新增到来的数据来一条就处理一条
- 有界数据流:数据是有开始时间和结束时间。Flink能够数据进行离线批处理。
- 无界数据流:数据是有开始时间和没有结束时间。Flink能够数据进行流式处理
- 有状态的计算:当前task处理的中间结果数据缓存起来,后续可以获取该中间结果
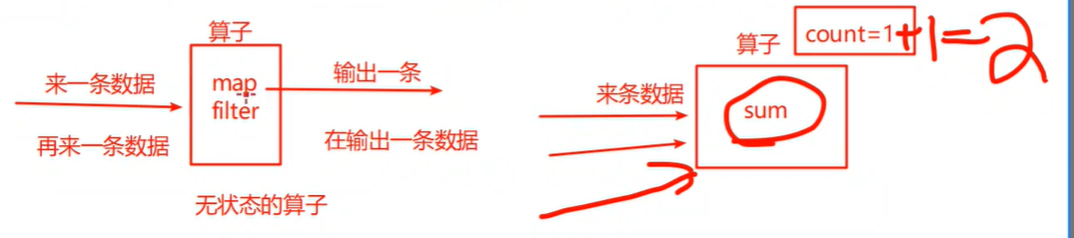
- 比如Spark-->DStream-->算子-->updateStateByKEey
- 在实际生产的过程中,大量数据在不断地产生,例如金融交易数据、互联网订单数据、 GPS 定位数据、传感器信号、移动终端产生的数据、通信信号数据等,以及我们熟悉的网络 流量监控、服务器产生的日志数据,这些数据最大的共同点就是实时从不同的数据源中产生, 然后再传输到下游的分析系统。针对这些数据类型主要包括实时智能推荐、复杂事件处理、 实时欺诈检测、实时数仓与 ETL 类型、流数据分析类型、实时报表类型等实时业务场景,而 Flink 对于这些类型的场景都有着非常好的支持。

若有收获,就点个赞吧
0 人点赞
