KS
KS用来衡量正负两个分布之间的差异,差异越大表明模型更具有区分正负样本的能力,KS值被定义为累积正例分布和累积负例分布的最大差值。
Gain/Lift

x轴是support,y轴是recall。
base rate,根据Base Rate 查找出完美的分类模型的情况,也就是当x值=BR时,也就是AUC为1的情况. 这是分类器能获得的最佳收益,因此我们的收益曲线(Gain curve)越接近idea case越好.
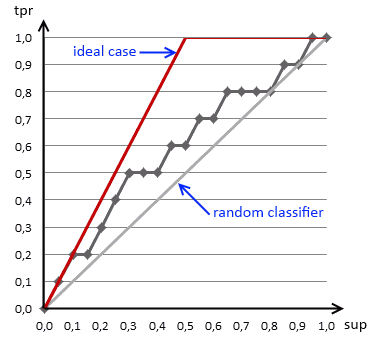
理想情况如上图的红线,也就是前面10个全是P,后面10个全是N,证明模型的区分能力很好,而灰色的斜线表示随机猜测。
下面是一个Gain的计算过程,其中样本量为N,有预测的score和实际的标签P/N,将预测的score,按照从大到小排序,下图左边是排完序之后的结果,没有保留原有的score,而是用标签代替。
x轴和y轴总共是1.0,按照排序之后的样本,从上到下, 每次考虑一个样本,此时x的步长为一个样本,也就是1.0/N,例子里有20个样本,所以是0.05一个点;此时y为P,也就是正标签的累积比例,总共10个P,所以每遇到1个P,就增加1/10=0.1,最终形成曲线。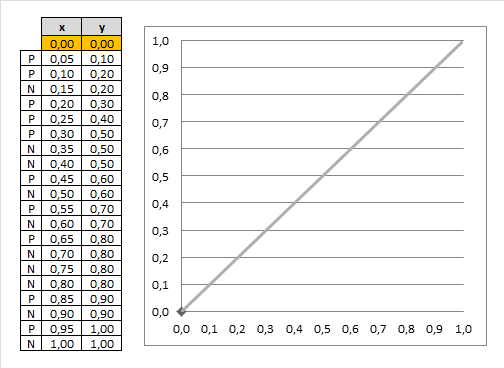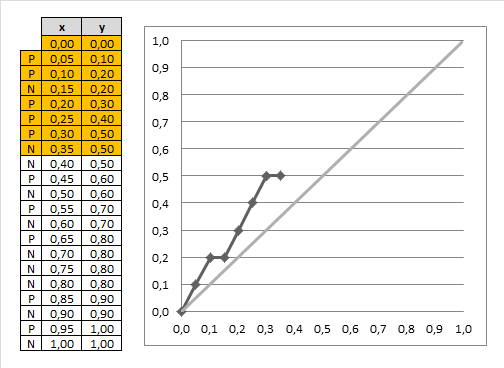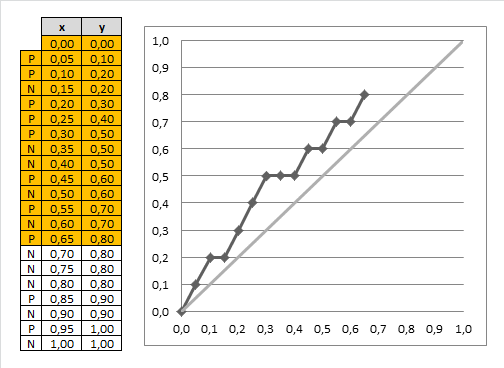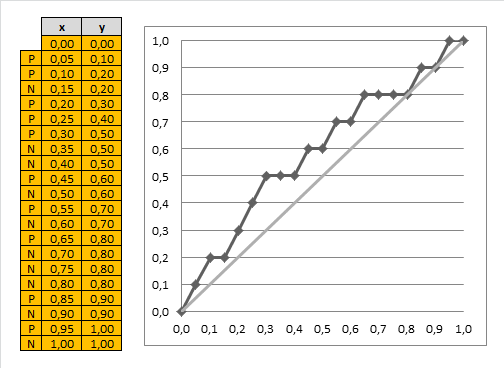
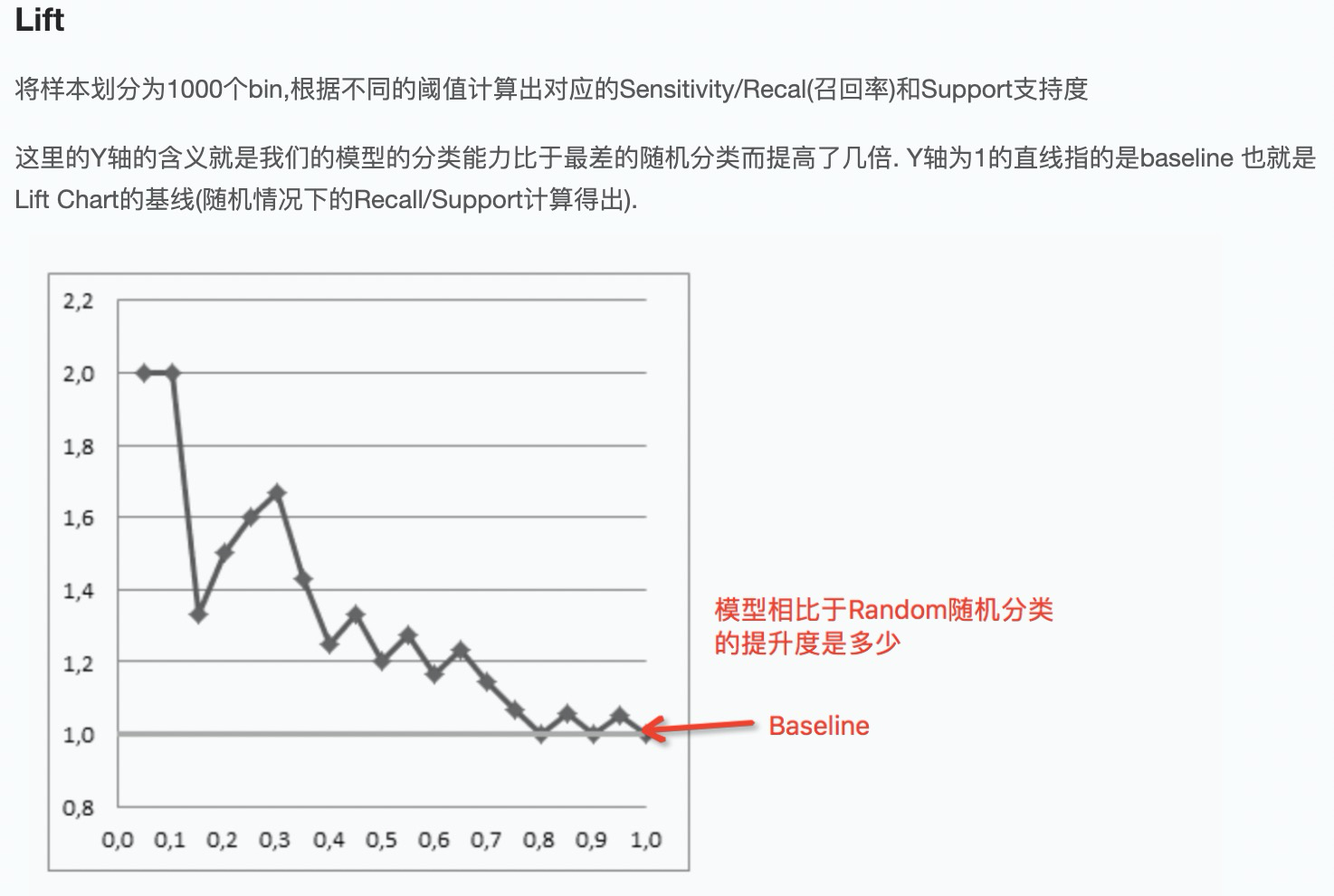

引用:

若有收获,就点个赞吧
0 人点赞
