参考:
- 《动手做深度学习第一版》优化算法B站视频
-
Mini-Batch 梯度下降
BGD(Batch Gradient Descent)- 按数据集迭代,每次对整个数据集计算每个样本的平均loss,然后反向梯度传播,迭代一次。
- SGD(Stochastic Gradient Descent)- 按样本迭代,每次对单个样本计算loss,然后反向梯度传播,迭代一次。
- Mini-Batch是一种介于BGD和SGD的中间做法,每次取mini-batch个样本当做一批来进行训练,通常mini-batch是2的倍数,介于2-512之间。相比于BGD,他减少了每次训练使用的样本,增加了迭代速度,相比于SGD,他增加了每次迭代使用的样本,增加了稳定性和鲁棒性。因此,mini-batch通常是对大样本训练的一种较好的处理方法。
指数加权平均(EMA)
EMA = Exponential Moving Average
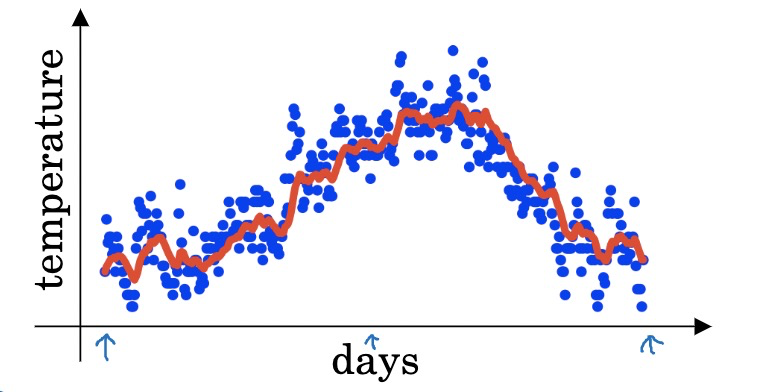
先来一个例子:
假设有某地近100天中每天的气温,其中第t天的气温用 表示,
表示, 是从1第天到第t天的加权平均温度。
是从1第天到第t天的加权平均温度。
指数加权平均的作用?
指数加权平均是平均数的一种近似,是一种加权平均,第100天的平均温度,以下面的例子来说,就是越近的日期,权重越大。
节省内存的说法我表示不能理解,即使是算平均数,你可以用两个变量,一个存储当前的sum,一个存储当前的个数,一样可以两个变量就可以解决平均数问题。(然而你这是每次都用所有的数据的情况,如果是只用最近N个数据,那么你就要记录最近N个数据的值,因为N是移动窗口,一直在改变的)。
指数加权平均的公式:
如果看不明白指数在哪里,可以将公式进一步写为:
为什么 代表了最近
代表了最近 天的平均温度?
天的平均温度?
以 为例,
为例, ,近似于0.3,或者1/e,同理,如果是
,近似于0.3,或者1/e,同理,如果是 ,
, 也差不多,所以意思是当权重只有0.3或者更小以后,就基本可以忽略了,没找到明确的数学证明,从《动手做深度学习》的讲解来看,这个基本算是一个共识吧。
也差不多,所以意思是当权重只有0.3或者更小以后,就基本可以忽略了,没找到明确的数学证明,从《动手做深度学习》的讲解来看,这个基本算是一个共识吧。
偏差修正可以解决最初的计算偏差过大的问题,也就是用
在t很大时,分子接近于1,在t很小时,可以更好的修正平均值的计算。
额外补充一些其他的平均方法:
- 移动平均
- 简单移动平均:选定一个窗口N,每个数据权重相等,计算N个数的平均数。随着时间推移,窗口N跟着推移,例如窗口为7,那么计算10月8日的数据就用10月1-7号,计算10月9日数据就用10.2-8号。这种方法的缺点就是要始终记录最近的N个数据,多占用了一些内存。
- 加权移动平均:也是选定窗口N,但是权重不一定是相等,一般会按照时间进行衰减。但是N个数据的权重总和还是1。
在移动平均的基础上,又发展出了指数加权平均,也就是我们上面介绍的,这种只需要记录最近一次结果,所以节省了内存。
同时,上面介绍的指数平滑其实是一次指数平滑,相应的还有二次指数平滑和三次指数平滑等。
Momentum - SGD+EMA
假设我们用 表示mini-batch的梯度向量,那么动量法的公式为:
表示mini-batch的梯度向量,那么动量法的公式为:
可见,Momentum是融合了EMA,对历史的梯度进行移动加权平均。
示例,假设有2个参数,在SGD时,更新的过程如下图: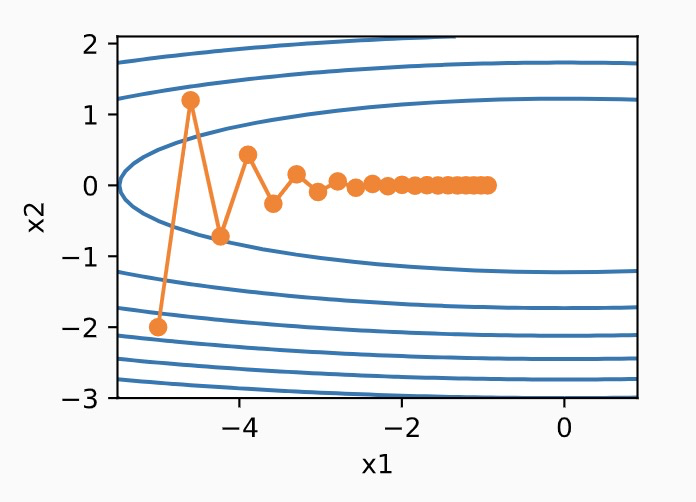
那么我们可以看到,梯度呈现zig-zag现象,在x2维度上,梯度一会是正的,一会是负的,这导致loss收敛的很慢,如果我们加大lr,那么很可能loss直接崩溃了。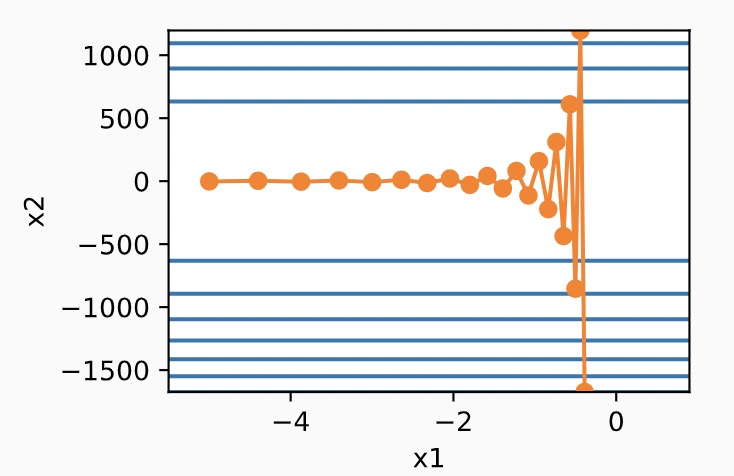
而采用了动量法以后,在x2方向上,因为每次的梯度都会考虑之前的梯度,所以正负被抵消了,而在水平方向上,则不断前进,因此,收敛速度大大加快。结果如下: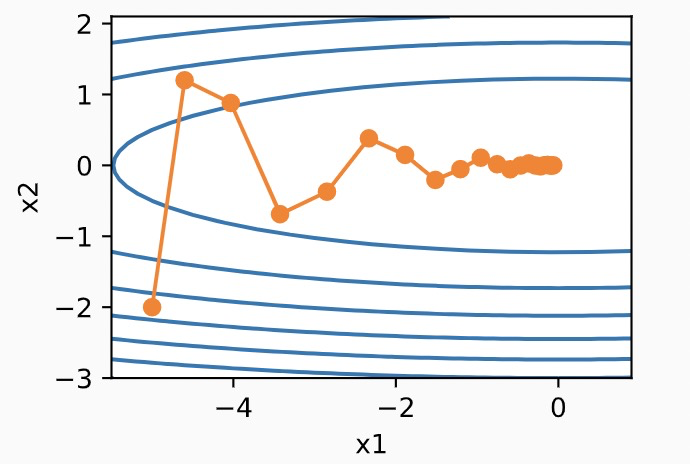
Adagrad - 自适应学习率,梯度方
SGD,Momentum,Nesterov等有一个问题,即对每一个参数,他们的学习率lr是一致的,但有些方向,如上图的x2,每次更新时,就应该用相对较小的lr,而x1方向,就应该用相对较大的lr。Adagrad就是对每个参数采用自适应的lr。
可见,s是随着迭代次数而不断累加的,因此如果s比较大,那么学习率lr会下降的非常快,因此Adagrad的问题在于,Adagrad在一开始发表时,是针对凸优化问题的,在凸优化的设定下,lr随着迭代次数不断衰减是有利于loss收敛的,但是在深度学习中,大多数是非凸优化问题,那么如果一开始Adagrad经过一定迭代次数依然没有找到最优点时,由于此时lr已经非常小,很难继续找到最优点。
RMSprop(EMA+Adagrad)
针对Adagrad前期梯度下降可能较快,导致当迭代一定次数依然没找到最优点时,参数更新缓慢的问题,有两个算法从不同的角度给出了方法,分别是RMSProp和Adadelta。

RMSProp的解决方法为,在更新s时,融入EMA思想,因为s初始化为0,所以在融入EMA后,s的变化幅度会相对变小,从而解决早期s过大而导致的lr过小的问题。
Adadelta(没有lr)
Adadelta在RMSprop的基础上,进一步去除了lr,用了一个新的变量来代替。

Adam(Momentum+RMSprop)

其中v’, s’的目的是对EMA中的v和s的初始值做偏差修正。
带warmup的adamw通常怎么选择b1,b2
为什么梯度是下降最快的方向?
参考自:梯度的方向为什么是函数值增加最快的方向?
为什么局部下降最快的方向就是梯度的负方向?
为什么梯度反方向是函数下降最快的方向?

若有收获,就点个赞吧
0 人点赞
