一些疑问
Q: 为什么选择sigmoid作为输出层的激活函数?
- 逻辑回归需要0-1值域的输出
- 套用sigmoid函数后,loss function是凸函数
从原理上来说: 最大熵解释
Q: 为什么不用平方作为损失函数?
最主要的原因是以LR的predict函数,如果继续采用平方损失,那么损失函数将会是一个非凸函数,很容易陷入到局部最优解。至于如何判断非凸函数,只需要求函数的二阶导,判断是否>0即可。
另外一个原因是,随着yf(x,w)的增大,损失应该减少,但是采用平方损失的话,其损失是会增大的。(这部分可以参见复旦邱锡鹏老师的《NNDL》)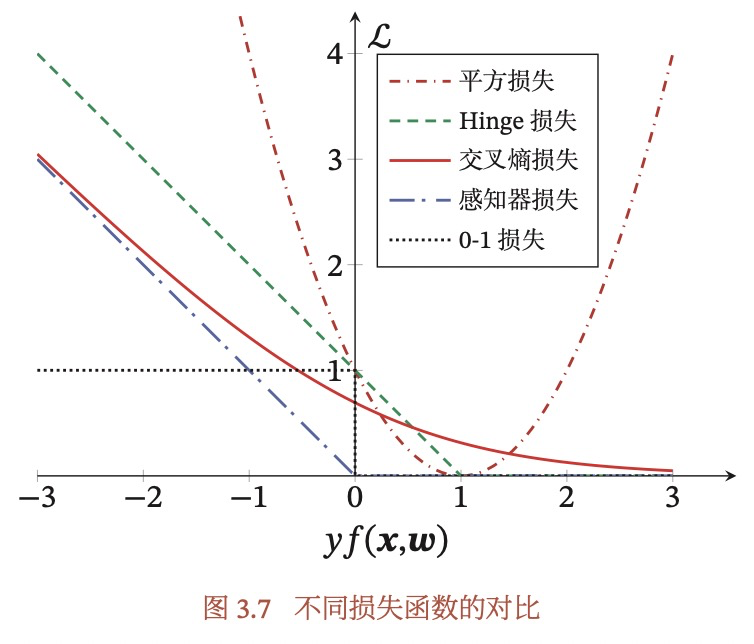
Q: LR的输入是否需要one-hot,稀疏和稠密的特征对LR来说有什么区别?
- dense格式不用one-hot编码,而sparse就是one-hot编码
- dense和kv哪个好?为什么互联网多试kv型处理
这就是one-hot编码的好处,个人理解主要是为了防止离散特征间的顺序关系,比如性别特征,男,女应该是同等地位的,用one-hot就很容易做到平等,但是如果是dense型特征,那么如果用0表示男,1表示女,那明显在计算线性部分时,女性的权重就高了。 - 是否需要考虑多重共线性的问题?ID型的是不是不太需要考虑这个问题?
是需要考虑的,个人理解ID型也存在这个问题,如果两个特征联系紧密,那么一个特征的在某个ID上取1,可能就会导致另外一个特征在相应位置也取1,但是这个肯定比dense型要好很多。 - 怎么对比离线和在线的结果?
离线看AUC,在线就实时看效果,如果实时效果增长幅度不太符合预期,可以看看是不是离线哪里有问题。
Q:特征数量是怎么算的?比如两条记录如下:
| user_id | Feature_1 | Feature_2 |
|---|---|---|
| u1 | u1_1 | gender_2 |
| u2 | u2_1 | gender_2 |
如果是dense型的特征,那么模型特征就是上面按列直接把特征输进去,每条记录基本都有这个特征;
如果是KV型特征,就是所有的特征量,每个人可能只有部分特征,有就是1,没有就是0.
源码查看

若有收获,就点个赞吧
0 人点赞
