假如用某个指标评价,如RMSE,如何评价该RMSE是否合理?
首先看一下你label的波动范围是多大?首先尝试预估一个平均数看看RMSE,然后再上个简单的线性回归,看看RMSE,或者你都预估成0再看看RMSE,也可以对比一下xgboost或者lightGBM等模型看看能有多少提升。如果提升很大,那我感觉基本你的问题也就是这个rmse水平了。单纯的一个RMSE的数字说明不了啥,除非他非常小,比如接近0了,那说明确实很好了,大部分情况下,比如RMSE=1000,你说这个模型效果是好还是坏?就只能用上面描述的方法了。
- SAE/SAD
Sum of Absolute Error/Difference,绝对误差,公式为 。
。
- MAE/MAD
Mean Absolute Error/Difference,平均绝对误差,公式为 。
。
MAE的问题在于受目标变量值影响较大,例如目标值是10000,那可能MAE=100表示模型很好了,而如果目标值是100,那MAE=100,表示模型效果其实比较差。那么,规避掉量纲带来的困扰,就有了MAPE。
- MAPE(通常是MAE结合MAPE来看,MAE看误差量级,MAPE看误差大小)
Mean Absolute Percentage Error,平均绝对百分比误差,公式为 ,也就是再除以一个真实值,相当于是误差的百分比。如果大于100%,一般表示模型效果不好,如果真实值的分母中有为0的数据,可能需要特殊处理。
,也就是再除以一个真实值,相当于是误差的百分比。如果大于100%,一般表示模型效果不好,如果真实值的分母中有为0的数据,可能需要特殊处理。
- wMAPE
MAPE虽然常用,但是有一些常见的问题,例如当原y为0时,除数就成了0,另外受较小的y影响较大,例如y=1,pred y = 2,那么MAPE=100%,但实际上,这个影响还是比较小的。
- SMAPE
对称平均绝对百分比误差(Symmetric Mean Absolute Percentage Error),公式为 ,同时考虑到了预测值和真实值。
,同时考虑到了预测值和真实值。
- MSE
Mean Square Error,均方误差,公式为: ,也就是(真实值-预测值)的平方和,再除以样本量N,求平均。最好情况是MSE=0。
,也就是(真实值-预测值)的平方和,再除以样本量N,求平均。最好情况是MSE=0。
对于回归问题来说,这也可以作为损失函数,在这种情况下,相当于是损失函数与评价指标是一致的了,好像也啥毛病。
这个公式有两个问题:
- 他改变了原有的量纲,比如目标变量为房价,单位是元,那么经过平方,单位是啥?就没办法解释了
- 因为有平方项,所以他受一些预测差的结果影响较大
- RMSE
Root Mean Square Error,均方根误差,公式为 ,在MSE的基础上,对结果进行开根号,从而避免了单位的问题,假如预测的目标为房价,单位是元,那么这里得到的误差,单位就是元,可以直接解释为预测与实际的偏差是多少元。
,在MSE的基础上,对结果进行开根号,从而避免了单位的问题,假如预测的目标为房价,单位是元,那么这里得到的误差,单位就是元,可以直接解释为预测与实际的偏差是多少元。
通常来说,同样的模型,RMSE>MAE,这是一个数学规律,即一组正数的平均数的平方,小于每个数的平方和的平均数。
上面的几个指标,都与具体的目标变量有很大的关系,不同的数据之间,是没办法直接比较的,比如房价,以元为单位和以万元为单位,采用上面几个指标,可能数值差异非常大,例如同样的预测结果,采用元,MSE=10000,而采用万元,那么MSE=1。而在分类问题上,我们采用例如正确率这样的指标,是可以对不同模型,不同数据之间进行比较的。那么回归问题有没有类似的指标呢?以下几个就是:
SSR:Sum of Squares for Regression,回归平方和,公式为 ,即预测值值与真实值的平均值,差的平方和。
,即预测值值与真实值的平均值,差的平方和。
SSE:Sum of Squares for Error,误差平方和,公式为 ,即真实值与预测值,差的平方和,也就是模型预测的误差。
,即真实值与预测值,差的平方和,也就是模型预测的误差。
SST:Sum of Squared for Total,总平方和,公式为 ,真实值与真实值的平均值,差的平方和,也就是当模型采用平均值预测时的误差。
,真实值与真实值的平均值,差的平方和,也就是当模型采用平均值预测时的误差。
通过最小二乘法可以证明,SST=SSR+SSE,证明如下: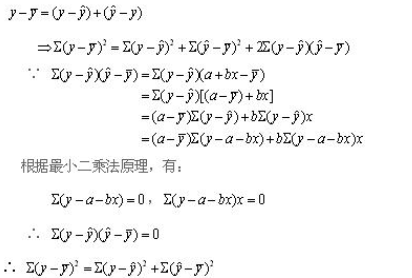
- R
Multiple Correlation Coeffient,多重相关系数。

Coefficient of Determination,判定系数,公式为: ,分子=模型产生的误差,分母可以看为是一个baseline,即以平均值为预测结果时产生的误差。
,分子=模型产生的误差,分母可以看为是一个baseline,即以平均值为预测结果时产生的误差。
所以,这个公式的含义是模型预测的误差比用平均数作为预测的时候的好坏,如果比值大于1,也就是模型还不如采用平均值预测的结果,此时R2小于0;如果比值小于1,也就是模型预测的误差比采用平均值小,模型优于平均值预测的结果,此时R2大于0,最大为1,当SSR=0时。

若有收获,就点个赞吧
0 人点赞
