感知机(Perceptron)是神经网络和SVM的基础。
直观理解
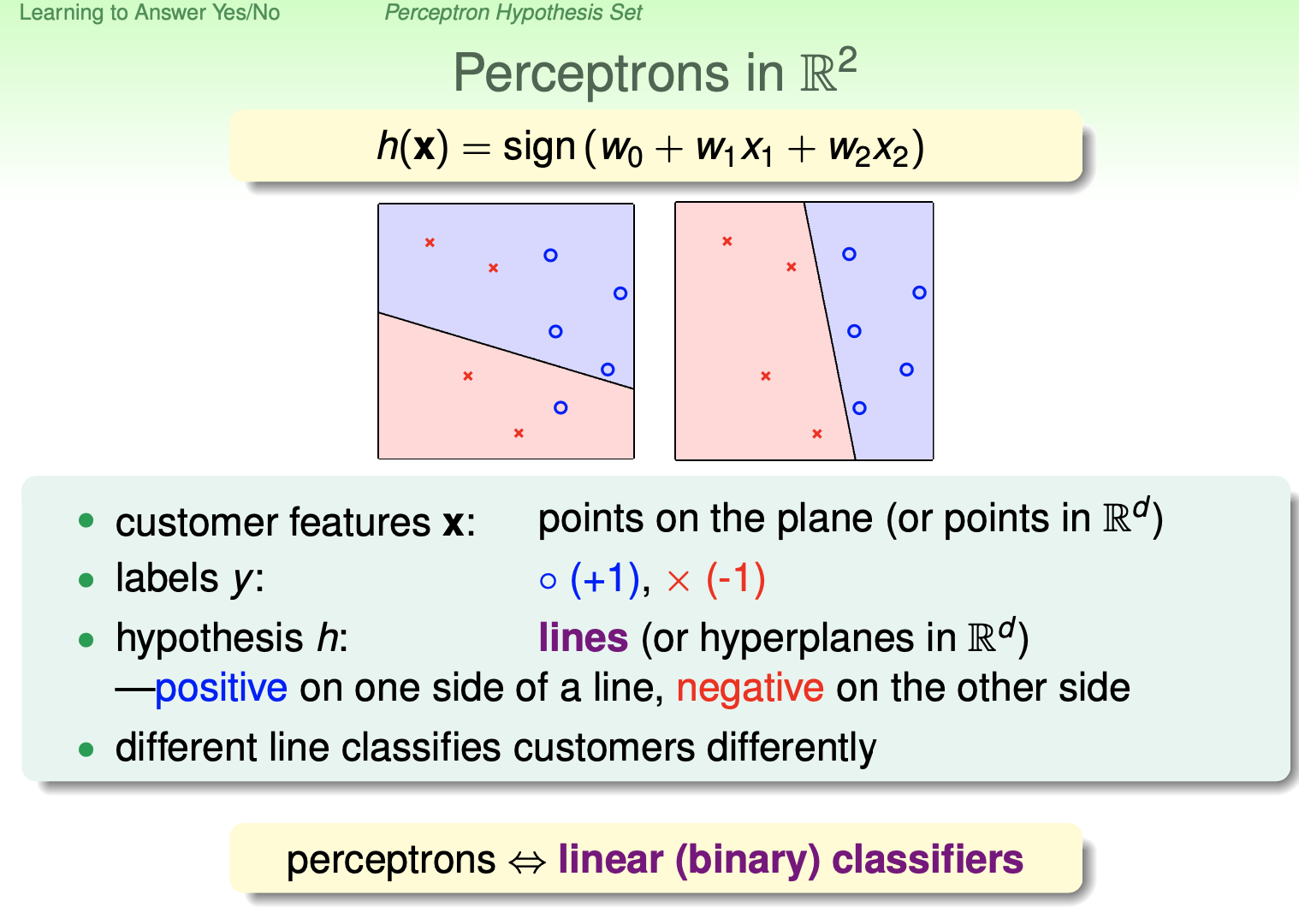
以二维的情况为例,图中的横坐标和纵坐标分别是x1和x2,那么一个样本就是一个(x1, x2)的点,然后x和o表示标签是-1还是+1,h表示假设空间,在这里,假设空间就是平面上的一条直线,表达式为,假设在直线上,就是表达式为0,在直线上面,表达式>0,在直线下面,表达式<0(关于直线和表达式的关系是初中几何的知识)。而我们的目标就是找到一条直线,可以完美隔开x和o。
原理
首先,感知机属于监督算法,是一个二分类的线性分类模型,属于判别模型,主要目的是求出将训练数据进行线性划分的分离超平面,所以,使用感知机的前提是数据集必须是线性可分的。
感知机的训练过程是用训练集分类错误的样本,来纠正分离超平面:
1)如果f(x)给出正确结果,即f(x)的预测结果与实际label一致,就验证下一个样本
2)如果给出错误结果,就调整决策边界
3)重复1),2)步骤,直到找出一个决策边界,可以将训练集中所有的样本均分类正确
感知机模型
输入空间:
输出空间:{-1, +1}
映射函数:%3Dsign(w%20%5Ccdot%20x%2Bb)#card=math&code=f%28x%29%3Dsign%28w%20%5Ccdot%20x%2Bb%29&height=20&width=160)
分离超平面:
其中sign(x)是符号函数:
%20%3D%20%5Cbegin%7Bcases%7D%0A%20%20%20%2B1%20%26%20x%20%5Cgeqslant%200%20%5C%5C%0A%20%20%20-1%20%26%20x%20%3C%200%0A%5Cend%7Bcases%7D%0A#card=math&code=sign%28x%29%20%3D%20%5Cbegin%7Bcases%7D%0A%20%20%20%2B1%20%26%20x%20%5Cgeqslant%200%20%5C%5C%0A%20%20%20-1%20%26%20x%20%3C%200%0A%5Cend%7Bcases%7D%0A&height=45&width=173)
损失函数
这里的损失函数,其实是经验风险函数,即在训练集上的平均损失。
Q:为什么不选择使用误分类点的个数,不是更简单直观吗?
A:以误分类点的数目作为损失函数,则该损失函数不是关于w,b连续可导,不宜优化。因此,感知机的损失函数,是基于误分类的损失函数,衡量所有分类错误的样本,距离决策边界的距离之和。
点到超平面的距离公式为:
所有误分类点集合到超平面的总距离为:
%0A#card=math&code=-%20%5Cfrac%7B1%7D%7B%5ClVert%20%5Comega%20%5CrVert%7D%20%5Csum_%7Bx_i%20%5Cin%20M%7Dy_i%20%28%5Comega%20%5Ccdot%20x_i%20%2B%20b%29%0A&height=48&width=177)
加入是为了保证结果为正,因为集合M里都是分类错误的点,所以当
时,
;而当
时,
。
为什么这里可以不考虑1/w?**不考虑,就得到了感知机的损失函数:**
%3D-%5Csum%7Bx_i%20%5Cin%20M%7Dy_i%20(%5Comega%20%5Ccdot%20x_i%20%2B%20b)%0A#card=math&code=L%28%5Comega%2C%20b%29%3D-%5Csum%7Bx_i%20%5Cin%20M%7Dy_i%20%28%5Comega%20%5Ccdot%20x_i%20%2B%20b%29%0A&height=42&width=215)
其中M为误分类点的集合,很明显L是一个连续可导函数,在没有误分类点时,L=0。
原始形式
为了求得,我们先任意选取一个超平面
,然后一次随机选取一个误分类点,使用梯度下降法,不断地极小化目标函数L。
假设误分类点M是固定的,那么损失函数#card=math&code=L%28%5Comega%2C%20b%29&height=20&width=49)的梯度为:
%26%3D-%5Csum%7Bx_i%20%5Cin%20M%7Dy_ix_i%20%5C%5C%0A%5Cnabla_b%20L(%5Comega%2C%20b)%26%3D-%5Csum%7Bxi%20%5Cin%20M%7Dy_i%0A%5Cend%7Baligned%7D%0A#card=math&code=%5Cbegin%7Baligned%7D%0A%5Cnabla_w%20L%28%5Comega%2C%20b%29%26%3D-%5Csum%7Bxi%20%5Cin%20M%7Dy_ix_i%20%5C%5C%0A%5Cnabla_b%20L%28%5Comega%2C%20b%29%26%3D-%5Csum%7Bx_i%20%5Cin%20M%7Dy_i%0A%5Cend%7Baligned%7D%0A&height=86&width=181)
原始形式的算法过程:
- 输出:w, b
- 感知机模型:
%3Dsign(w%20%5Ccdot%20x%20%2B%20b)#card=math&code=f%28x%29%3Dsign%28w%20%5Ccdot%20x%20%2B%20b%29&height=20&width=160)
- 选取初值
- 在训练集中选取数据
#card=math&code=%28x_i%2C%20y_i%29&height=20&width=49)
- 如果
%20%5Cleqslant%200#card=math&code=y_i%28w%20%5Ccdot%20x_i%20%2B%20b%29%20%5Cleqslant%200&height=20&width=125),表示分类错误,则进行修正:

如何更直观的理解这个修正?为什么这样就可以生效?
从公式上来说,梯度下降法是在尝试减少损失函数的大小,因此,当一个点被误分类时,也就是位于分离超平面的错误一侧时,我们通过调整w,b,使得分离超平面向着错误点的方向靠近,从而减少分类错误的点离分离超平面的距离,直到分离超平面越过分类错误点,使其被正确分类。
- 转到步骤2,直到训练集中没有误分类的点。
对偶形式
Q:对偶形式的意义在哪?
A:对偶形式的意义在于,如果能提前计算出gramm matrix,那么计算速度会快很多,至于什么是gramm matrix,下面有。
对偶形式是试图用样本点本身的特征#card=math&code=%28x_i%2Cy_i%29&height=20&width=49)来表示w和b。
从上面原始形式w,b的更新步骤来看:
其实,如果都相比于初始的w,b,那么每次w,b关于误分类点#card=math&code=%28x_i%2C%20y_i%29&height=20&width=49)的增量分别是
和
,这里
,
 表示是第次迭代,注意这里说了是针对点
表示是第次迭代,注意这里说了是针对点 ,也就是说当是误分类点时,才会对w,b进行更新,因此每个点对w,b的更新次数都不一样,因此实际表示了该点被误分类了多少次,也就对w,b更新了多少次,所以,最后学习到的w,b可以分别表示为:
,也就是说当是误分类点时,才会对w,b进行更新,因此每个点对w,b的更新次数都不一样,因此实际表示了该点被误分类了多少次,也就对w,b更新了多少次,所以,最后学习到的w,b可以分别表示为:
这里,,当
时,表示第i个样本由于误分类而进行更新的次数。上面这个公式的意思就是,对N个点,每个点都可能被误分类
次,从而对w,b产生了次的修改。实例点更新次数越多,意味着它距离分离超平面越近,也就越难正确分类。因为分离超平稍微改变一下w,b,该点就被分离错了,所以表明他离分离超平面很近。换句话说,这样的实例对学习结果影响最大。
对偶形式的算法过程:
输出:a, b
感知机模型: ,其中
,其中 %5ET#card=math&code=%5Calpha%3D%28%5Calpha1%2C%20%5Calpha_2%2C…%2C%5Calpha_N%29%5ET&height=23&width=160)
(1)
(2)在训练集中选取数据 #card=math&code=%28x_i%2C%20y_i%29&height=20&width=49)
(3)如果
(4)转到第(2)步,直到没有误分类数据
对偶形式中的训练样本仅以内积的形式出现,因此,为了方便,可以预先将训练集中样本间的内积计算出来,并以矩阵的形式存储,这个矩阵就是Gramm matrix:
收敛性
可以证明,对于线性可分的数据集
1)一定可以找到分离超平面
2)一定可以在有限次内收敛
3)感知机算法存在很多解,为得到唯一分离超平面,需要增加约束,如SVM
即经过有限次搜索,可以找到将训练数据完全正确分开的分离超平面
核心代码
原始形式的核心代码如下:
# 数据线性可分,二分类数据class Model:def __init__(self):# data[0]指的是data的第一个样本, 包含标签self.w = np.zeros(len(data[0])-1, dtype=np.float32)self.b = 0self.lr = 0.1def sign(self, x, w, b):y = np.dot(x, w) + breturn 1 if y >= 0 else -1# SGDdef fit(self, X_train, y_train):wrong_count = 1epoch = 0while wrong_count > 0:wrong_count = 0epoch += 1for i in range(len(X_train)):X = X_train[i] # (2, )y = y_train[i] # 1is_wrong = y * self.sign(X, self.w, self.b) < 0# 如果分类错误,更新w,bif is_wrong:print("epoch = %d, i = %d, w = %s, b = %d" % (epoch, i, self.w, self.b))self.w += self.lr * y * Xself.b += self.lr * ywrong_count += 1return 'Original Perceptron Model!'
参考
- 李航《统计学习方法》第二章
- 林轩田《机器学习基石》

若有收获,就点个赞吧
0 人点赞

{kind=link}