优化算法
https://www.bilibili.com/video/BV1Qx41177Wh?from=search&seid=1912611513980043125
优化算法
7.1 网络优化
低维空间的网络优化和高维空间的网络优化有什么不同?
低维的非凸优化主要是逃离局部极值点,高维的非凸优化主要是逃离鞍点。
什么是鞍点?怎么逃离鞍点?
鞍点的梯度是0,但是在某些维度是最高点,某些维度是最低点。
通过在梯度方向上引入随机性,可以有效的逃离鞍点。
什么是平坦最小值和尖锐最小值?平坦最小值有什么好处?
深度网络的参数非常多,并且有一定冗余性,使得每个参数对损失的影响都比较小,导致损失函数在局部最小值附近是一个平坦的区域。平坦区域表明模型鲁棒性比较强,泛化能力好。对于深度网络来说,全局最小值反而比较容易过拟合。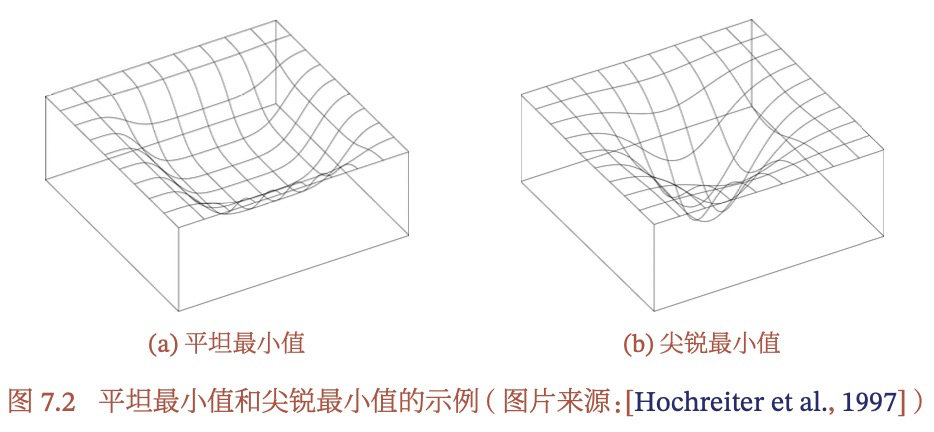
7.2 优化算法
batch大小如何影响随机梯度的期望和方差?
batch就相当于是从总体中抽样,因此期望是与整体一样的,但是随机梯度的方差会随着batch的增大而减小,这个很容易理解,样本数量越多,肯定就越稳定。
batch大小与学习率大小的关系?
batch大小与平坦最小值和尖锐最小值的关系?
有paper通过实验发现,batch越大,越容易收敛到尖锐最小值,batch越小,越容易收敛到平坦最小值。
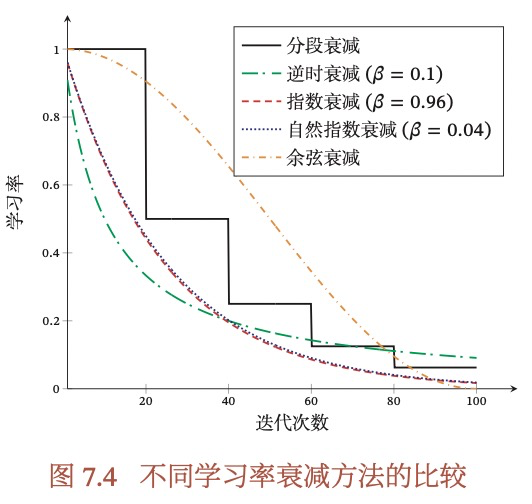
学习率的衰减,预热,周期性调整是什么意思?
衰减也成为模拟退火,就是每隔一定的迭代次数,对梯度进行衰减。
刚开始训练时,参数是随机初始化的,梯度也比较大,如果采用较大的初始学习率,会使得训练不稳定。所以,在训练初期,我们选择较小的学习率,随着迭代次数不断增大,逐渐恢复到初始学习率,这称为学习率的预热,当然之后你可以再采取学习率的衰减等其他策略。
周期性调整是每隔一段时间,增大学习率,从而使得梯度下降可能逃离鞍点或尖锐最小值。
学习率的衰减有哪些方法?预热有哪些方法?
EMA的公式是什么?为什么相当于最近1/(1-beta)的平均值?

介绍优化算法Momentum?
介绍自适应学习率调整算法AdaGrad?
在SGD的基础上,自适应学习率,每个参数通过累积自己梯度的平方,然后开方取倒数,作为每个参数自己的学习率。
介绍自适应学习率调整算法RMSprop?
介绍自适应学习率调整算法Adam?
7.3 参数初始化
什么是Xavier初始化?
根据每层神经元数量来自动计算初始化参数方差,目的是为了保持每个神经元的输入和输出的方差一致,使得信号在前向和反向传播中都不被放大或缩小。Xavier可以适用于Logistic或Tanh等激活函数。
什么是He初始化?
作用与Xavier一致,只是当使用ReLU作为激活函数时,称为He初始化,也就kaiming初始化,因为是何凯明发明的…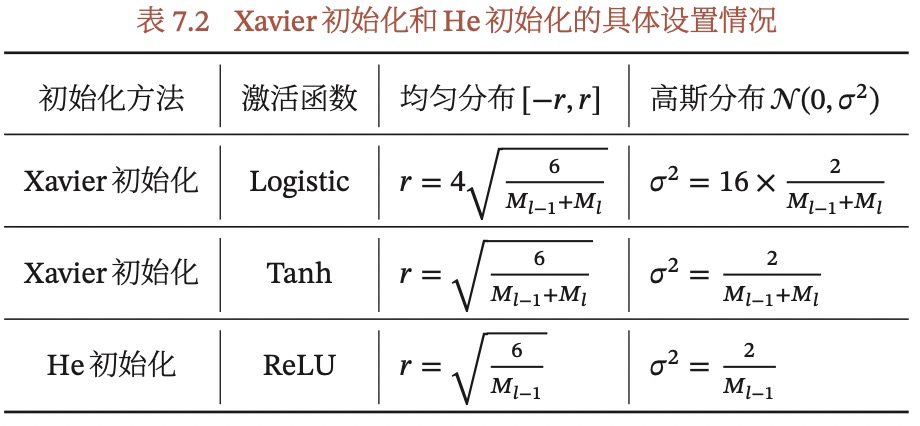
7.5 逐层归一化
什么是内部协变量偏移(Internal Covariate Shift)?
从机器学习的角度看,如果一个神经层的输入分布发生了变化,那么其参数需要重新学习。但是在DNN中,随着隐藏层的加深,偏差在逐渐累加,因此初始层的一些小变化,到深度以后,就会变成很大的偏差,从而导致深层的网络输入分布发生变化。
为什么逐层归一化可以提高训练效率?
逐层归一化 = 作用于DNN隐藏层的数据归一化
- 更好的尺度不变性:缓解内部协变量偏移,从而更高效的进行参数初始化和超参选择。
更平滑的优化地形:
- 逐层归一化可以使得输入保持在Sigmoid型函数的不饱和区域,从而让梯度变大,避免梯度消失问题
- 可以使得神经网络的优化地形更加平滑,梯度更加稳定,从而允许使用更大的学习率,提高收敛速度
什么是批量归一化(Batch Norm, BN)?
BN是作用于激活函数之前,仿射变换 之后,通常是对一个min-batch的输出进行标准化,均值和方差为该mini-batch的均值和方差。标准化会使得结果集中于0附近,在用Sigmoid型函数时,这个区间接近线性,减弱了神经网络的非线性性质,因此,一般会添加一个缩放和平移,以减少该影响,这个缩放和平移的具体值是一个参数,随着模型训练学习出来的。原论文中的公式如下:
之后,通常是对一个min-batch的输出进行标准化,均值和方差为该mini-batch的均值和方差。标准化会使得结果集中于0附近,在用Sigmoid型函数时,这个区间接近线性,减弱了神经网络的非线性性质,因此,一般会添加一个缩放和平移,以减少该影响,这个缩放和平移的具体值是一个参数,随着模型训练学习出来的。原论文中的公式如下:
BN还可以视为一种正则化方法,因为每个batch都是随机选的,而在训练和预测时,每个样本因为BN都会与其他样本有关,因此会减弱网络对某个特定样本的拟合。
更详细的内容可以参考张俊林:Batch Normalization导读
https://mp.weixin.qq.com/s?__biz=MzIwMTc4ODE0Mw==&mid=2247567437&idx=2&sn=14b77dcb74bbab2fad1b316d5abfda72BN在训练和预测时有什么区别?
BN在训练时的期望和方差都是采用的每个mini-batch的均值和方差,在预测时,只有1个样本,没有mini-batch怎么办?此时就采用训练样本整体的期望和方差来代替,这个整体的期望和方差,可以通过训练中mini-batch的每一个期望和方差求期望获得。即: %22%20aria-hidden%3D%22true%22%3E%0A%3Cg%20transform%3D%22translate(18216%2C0)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-45%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-5B%22%20x%3D%22764%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-78%22%20x%3D%221043%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-5D%22%20x%3D%221615%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-2190%22%20x%3D%222171%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3Cg%20transform%3D%22translate(3450%2C0)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-45%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-42%22%20x%3D%221044%22%20y%3D%22-213%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-5B%22%20x%3D%224825%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3Cg%20transform%3D%22translate(5104%2C0)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-3BC%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-42%22%20x%3D%22853%22%20y%3D%22-213%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-5D%22%20x%3D%226344%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3Cg%20transform%3D%22translate(16563%2C-1803)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-56%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-61%22%20x%3D%22769%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-72%22%20x%3D%221299%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-5B%22%20x%3D%221750%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-78%22%20x%3D%222029%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-5D%22%20x%3D%222601%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-2190%22%20x%3D%223157%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3Cg%20transform%3D%22translate(4158%2C0)%22%3E%0A%3Cg%20transform%3D%22translate(397%2C0)%22%3E%0A%3Crect%20stroke%3D%22none%22%20width%3D%222721%22%20height%3D%2260%22%20x%3D%220%22%20y%3D%22220%22%3E%3C%2Frect%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-6D%22%20x%3D%22921%22%20y%3D%22676%22%3E%3C%2Fuse%3E%0A%3Cg%20transform%3D%22translate(60%2C-687)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-6D%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-2212%22%20x%3D%221100%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-31%22%20x%3D%222101%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3C%2Fg%3E%0A%3C%2Fg%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-45%22%20x%3D%227398%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-5B%22%20x%3D%228162%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3Cg%20transform%3D%22translate(8441%2C0)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-3C3%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMAIN-32%22%20x%3D%22810%22%20y%3D%22488%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-42%22%20x%3D%22808%22%20y%3D%22-452%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-5D%22%20x%3D%229649%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3C%2Fg%3E%0A%3C%2Fsvg%3E#card=math&code=E%5Bx%5D%20%5Cleftarrow%20E_B%5B%5Cmu_B%5D%20%5C%5C%0AVar%5Bx%5D%20%5Cleftarrow%20%5Cfrac%7Bm%7D%7Bm-1%7DE%5B%5Csigma_B%5E2%5D%0A&id=HzHE0)
%22%20aria-hidden%3D%22true%22%3E%0A%3Cg%20transform%3D%22translate(18216%2C0)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-45%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-5B%22%20x%3D%22764%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-78%22%20x%3D%221043%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-5D%22%20x%3D%221615%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-2190%22%20x%3D%222171%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3Cg%20transform%3D%22translate(3450%2C0)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-45%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-42%22%20x%3D%221044%22%20y%3D%22-213%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-5B%22%20x%3D%224825%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3Cg%20transform%3D%22translate(5104%2C0)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-3BC%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-42%22%20x%3D%22853%22%20y%3D%22-213%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-5D%22%20x%3D%226344%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3Cg%20transform%3D%22translate(16563%2C-1803)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-56%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-61%22%20x%3D%22769%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-72%22%20x%3D%221299%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-5B%22%20x%3D%221750%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-78%22%20x%3D%222029%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-5D%22%20x%3D%222601%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-2190%22%20x%3D%223157%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3Cg%20transform%3D%22translate(4158%2C0)%22%3E%0A%3Cg%20transform%3D%22translate(397%2C0)%22%3E%0A%3Crect%20stroke%3D%22none%22%20width%3D%222721%22%20height%3D%2260%22%20x%3D%220%22%20y%3D%22220%22%3E%3C%2Frect%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-6D%22%20x%3D%22921%22%20y%3D%22676%22%3E%3C%2Fuse%3E%0A%3Cg%20transform%3D%22translate(60%2C-687)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-6D%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-2212%22%20x%3D%221100%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-31%22%20x%3D%222101%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3C%2Fg%3E%0A%3C%2Fg%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-45%22%20x%3D%227398%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-5B%22%20x%3D%228162%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3Cg%20transform%3D%22translate(8441%2C0)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-3C3%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMAIN-32%22%20x%3D%22810%22%20y%3D%22488%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-42%22%20x%3D%22808%22%20y%3D%22-452%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-5D%22%20x%3D%229649%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3C%2Fg%3E%0A%3C%2Fsvg%3E#card=math&code=E%5Bx%5D%20%5Cleftarrow%20E_B%5B%5Cmu_B%5D%20%5C%5C%0AVar%5Bx%5D%20%5Cleftarrow%20%5Cfrac%7Bm%7D%7Bm-1%7DE%5B%5Csigma_B%5E2%5D%0A&id=HzHE0)
BN为什么不能用于原始RNN中?
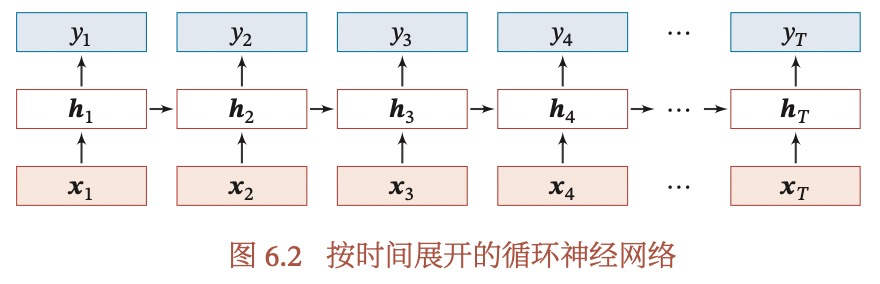
我们来看一下原始RNN的网络结构,每个样本输入的长度可能是不同的,对于一个样本来说,有T个输入,也就是有T个时间步,假如我们把训练样本都补足到mini-batch内最长的长度,极端来说,最长的样本在T时刻可能只有1个,没有其他样本可以计算均值和方差。
再比如,预测时有一个样本超越了所有训练样本,那么超出的部分,均值和方差怎么算呢?什么是层归一化(Layer Norm, LN)?
LN与BN类似,作用的位置相同,但是他的均值和方差是整个L层单元的均值和方差,然后也会进行缩放和平移。
RNN中梯度消失和梯度爆炸是由于内部协变量偏移导致,所以LN应用于RNN中,可以缓解梯度消失或梯度爆炸。什么时候选择BN,什么时候选择LN?
假设一个样本经过仿射变换后,对一个神经元,生成一个值,那么一个M个batch的样本,就是M个值,BN就是用这M个值的均值和方差进行标准化。而LN是,一个样本经过仿射变换后,对一个神经元生成一个值,但是该层假设有L个神经元,那就是L个值,LN是用这L个值的均值和方差进行标准化。
一般来说,BN更好,但是当batch较小时,选择LN更好。7.6 超参数优化
常见的超参数优化有几种方法?每种都是怎么操作的?
网格搜索:尝试所有超参的组合,如果超参是连续值,可以选取几个离散化的值,如学习率,可以取{0.01, 0.1, 0.5, 1.0}这样。
- 随机搜索:网格搜索时遍历所有的超参组合,而随机搜索则是随机挑选一部分超参组合。
- 贝叶斯优化
- 动态资源分配
-
7.7 网络正则化
常见的正则化方法有哪些?
L1,L2正则
- 权重衰减:类似于L2正则,通过减小参数的权重来实现正则化,直观的理解是,参数变小后,每个参数的作用都被削弱,那么模型就不会非常依赖于某一个参数,从而达到正则化的效果。
- early stop:额外使用一个验证集,验证模型在验证集上的错误,当错误不再下降,就停止迭代。
- dropout:通过随机丢弃某些神经元,减少对固定神经元的依赖,从而防止过拟合
什么是L1正则,什么是L2正则,两者有什么区别 ?
更详细的内容可以参见林轩田机器学习基石里的Normalization部分。
结论:L1是参数一范数的和,L2是参数二范数的和,L1比L2更容易产生稀疏解。
具体理解为下:假设我们只有一个参数W,那么对应的L1公式为: ,L1及其导数对应的图像如下图,那么在梯度更新时,不管L1的大小是多少,梯度都是-1或+1,所以每次更新,他都是朝着0稳定前进的,如最右边的图:
,L1及其导数对应的图像如下图,那么在梯度更新时,不管L1的大小是多少,梯度都是-1或+1,所以每次更新,他都是朝着0稳定前进的,如最右边的图: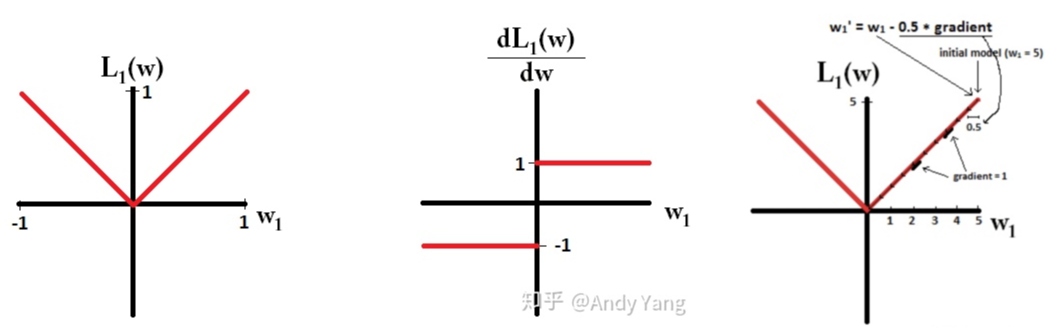
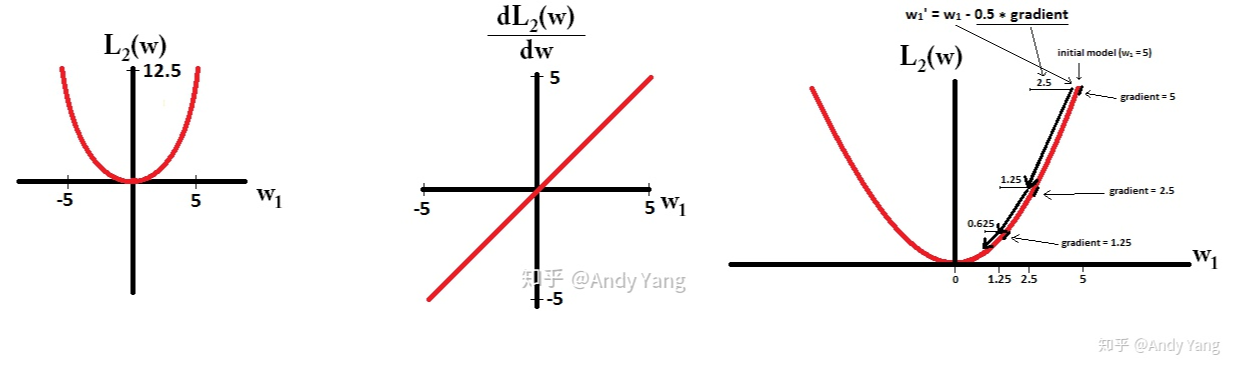
而L2的公式及其函数,导数图如下,也就是随着W逐渐接近0,梯度也是在不断减小的,这就使得L2正则比较难达到真正的0:
什么是dropout?
对神经网络随机丢弃一些神经元,每个神经元保留的概率为p,通过设置一个mask函数来实现: ,其中
,其中
所以,在训练时,激活的神经元是全部神经元的p倍,而在测试时,所有神经元都是激活的,这会导致训练和测试时的输出不一致,为了缓解这个问题,在测试时,需要将输入乘以p,相当于把不同的神经网络做了平均。
这部分可以通过看代码更深入的了解。从集成学习角度和贝叶斯学习角度,分别怎么理解dropout?
- 集成学习:相当于每次都是训练了不同的子网络,最终的网络是子网络的组合
- 贝叶斯学习:dropout可以看成贝叶斯学习的近似
要同时使用BN和dropout该如何使用?
同时使用BN和dropout时,可能存在方差偏移的问题
针对方差偏移,论文给出了两种解决方案:
- 拒绝方差偏移,只在所有BN层的后面采用dropout层(现在大部分开源的模型,都在网络的中间加了BN,我们也就只能在softmax的前一层加加dropout了,效果还行,至少不会比不加dropout差。还有另外一种方法是模型训练完后,固定参数,以测试模式对训练数据求BN的均值和方差,再对测试数据进行归一化,论文证明这种方法优于baseline)
- dropout原文提出了一种高斯dropout,论文再进一步对高斯dropout进行扩展,提出了一个均匀分布Dropout,这样做带来了一个好处就是这个形式的Dropout(又称为“Uout”)对方差的偏移的敏感度降低了

若有收获,就点个赞吧
0 人点赞
