8.1 attention
什么是attention的分布?
首先,我们有N个输入向量,然后通过引入一个查询向量,来筛选出与任务有关的输入,得到N个输入,每个的权重,就是一个attention的分布。
通过一个打分函数来计算输入向量和查询向量之间的相关性,得到每个查询向量的权重。
attention打分函数有几种?各有什么优缺点?
- 加性模型:

- 点积模型:

加性模型和点积模型复杂度差不多,但是点积模型可以利用矩阵运算,效率更高。
- 缩放点积模型:

D是输入向量的维度,当D较大时,点积模型的值方差较大,从而导致Softmax函数的梯度较小,因此通过缩放点积解决这个问题。
- 双线性模型:

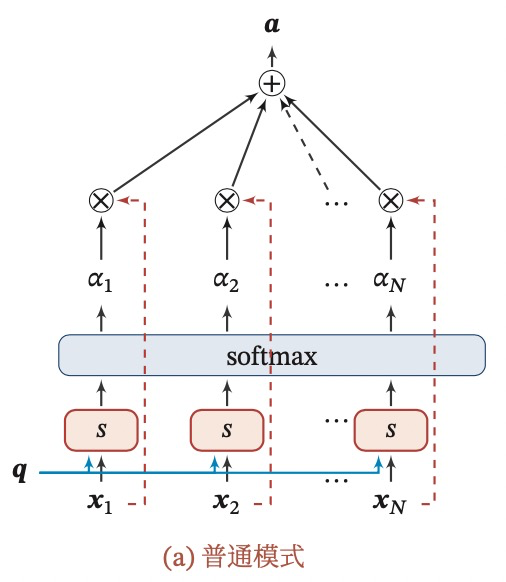
什么是软性attention?
对每个输入向量进行加权平均,称为软性注意力机制。
 |
 |
|---|---|
什么是硬性attention?
相比于软件attention关注每一个输入向量,硬性attention只关注其中某1个输入向量。例如:
- 选取概率最高的输入向量,类似于max pooling
- 在attention分布上随机采样1个
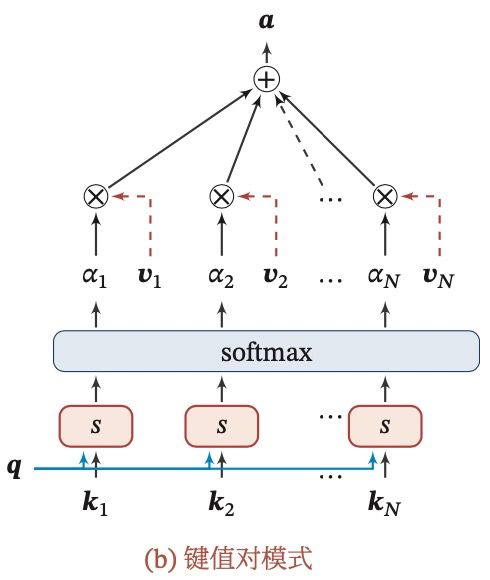
什么是key-value pair attention?
将输入分为key和value两个部分,key用来计算注意力分布,value用来计算聚合信息。那么对每一个输入向量,都有一组对应的key和value,如果K=V,就是普通的注意力机制。
 |
 |
|---|---|
什么是multi-head attention?
就是查询向量也有多个,每个都与之前介绍的一致,最终将这多个结果拼接起来,可以并行的从输入中选取多组信息,每个查询向量关注不同的部分。
*什么是结构化attention?
指针网络pointer是什么?
注意力机制分为两步:
- 计算注意力分布
- 计算输入向量的加权平均
8.2 self-attention
什么是self-attention?
这部分的实例在transformer中,可以查看图解transformer。
有Q,K,V 3个向量,但都是由输入向量X生成的。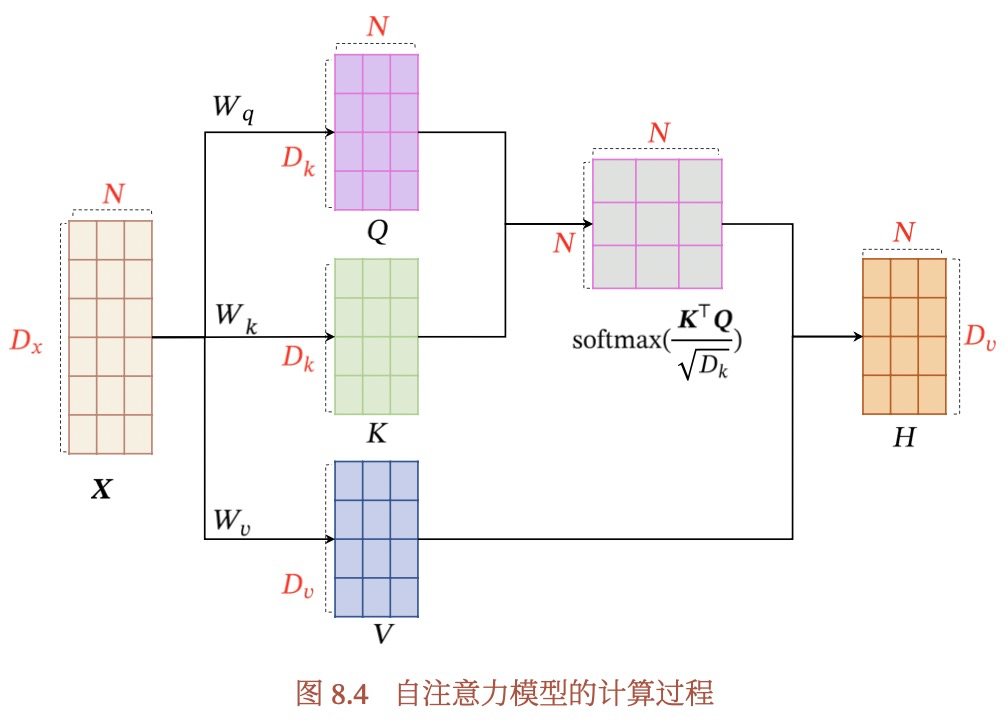
自注意力模型可以用来处理变长序列,可以作为神经网络中的一层,来代替卷积层或循环层。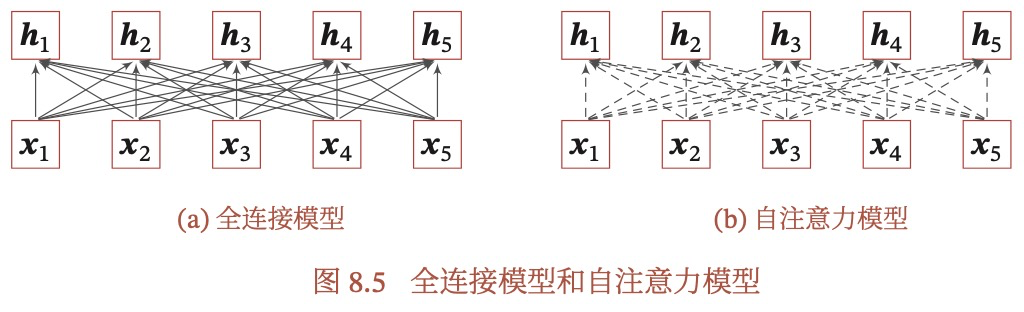
什么是Multi-head self-attention?
在self-attention的基础上,增加多组(Q,K,V),试图从不同的角度捕捉信息。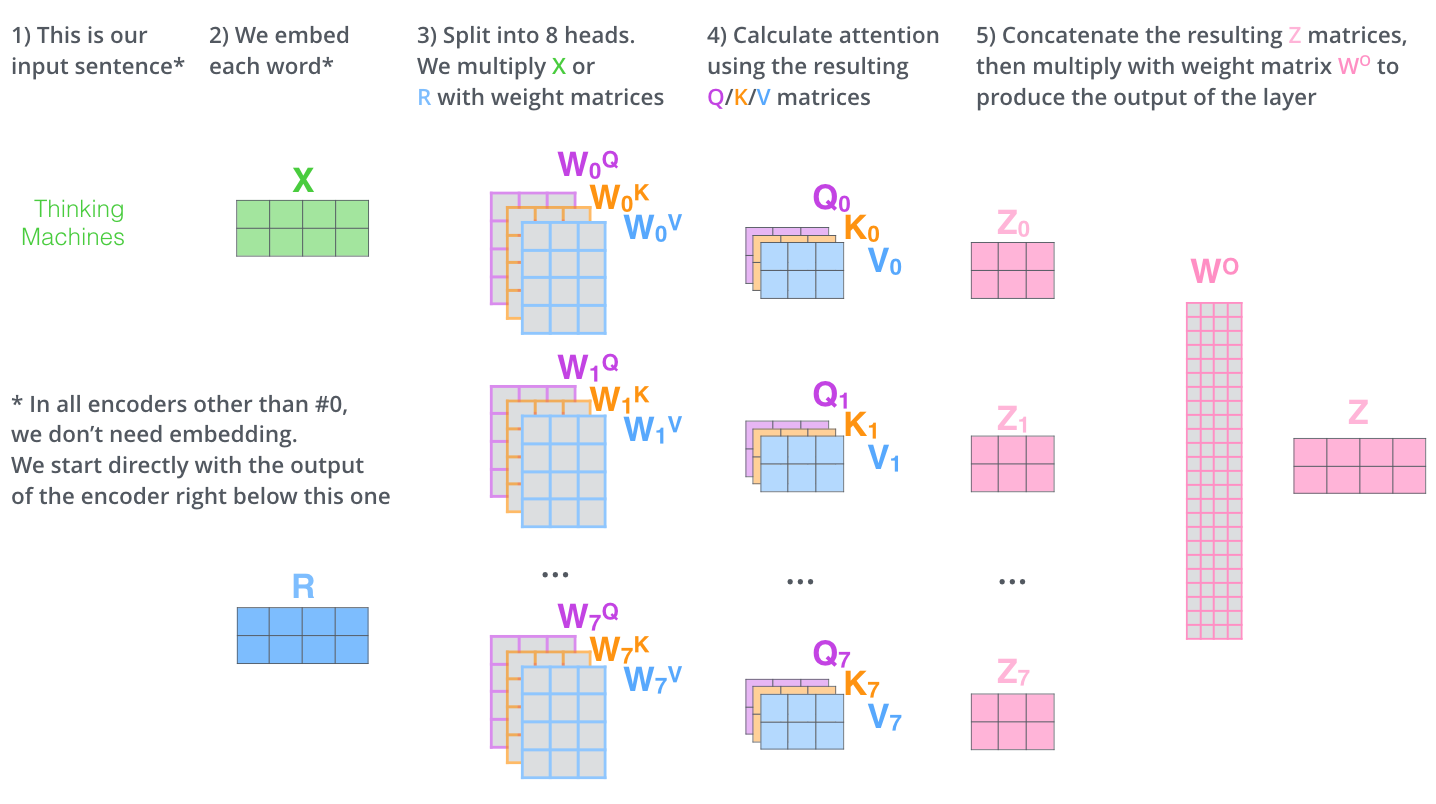

若有收获,就点个赞吧
0 人点赞
