6.1 简介
RNN与前馈神经网络有什么不同?这种不同有什么好处?
- 前馈神经网络:
- 只能处理固定长度的输入,不能处理变长输入(即每个样本长度可能不一致)。
- 静态网络,没有记忆力
- RNN:


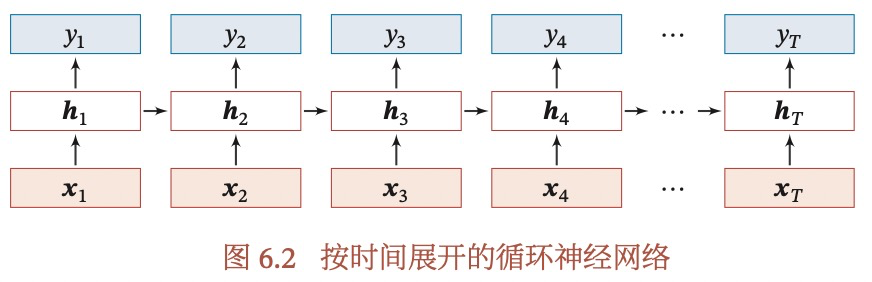
- 序列->类别
- 同步的sequence-to-sequence
- 异步的sequence-to-sequence:自回归,也被称为Encoder-Decoder模型。
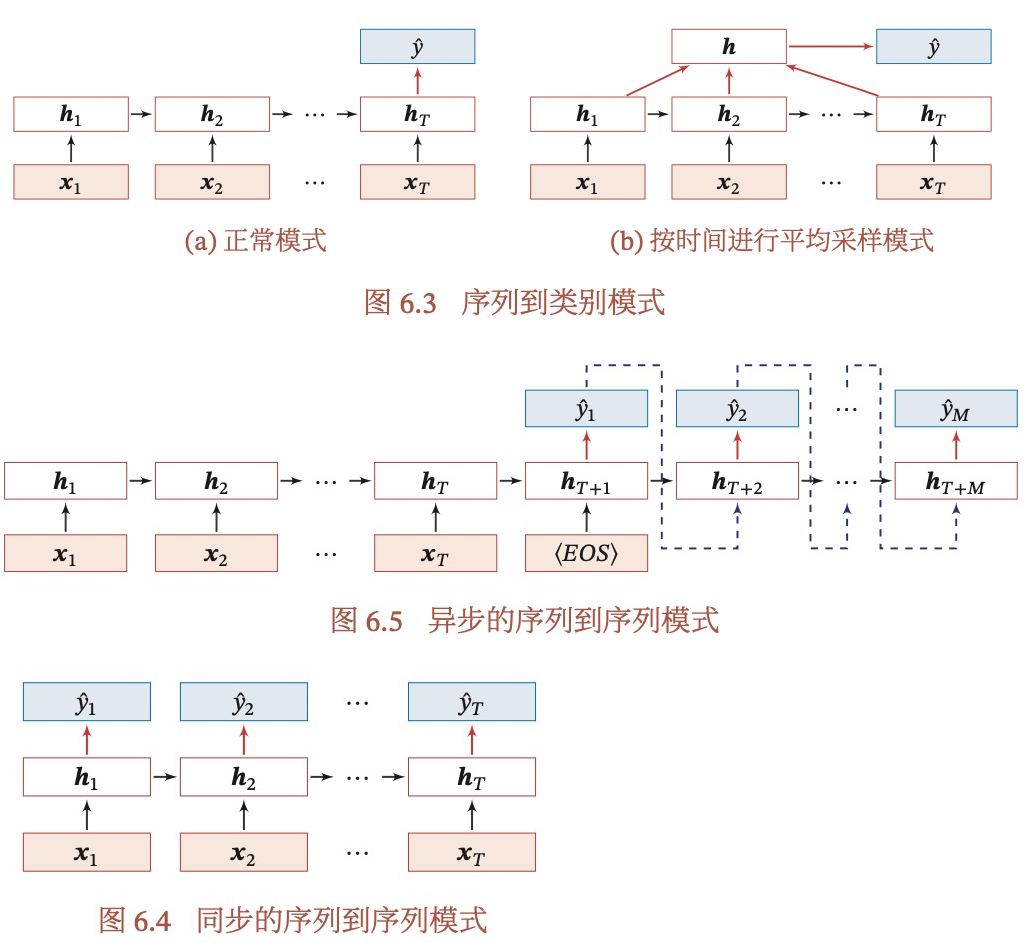
6.4 参数学习
介绍一下随时间反向传播算法BPTT?
以下内容参考

简单说一下图,图中表示了一个有3个时间步的RNN网络示意图。其中x1,x2,x3代表输入(每个为单样本,d维度,即d个特征),W都是参数矩阵,参数在RNN中都是共享的,假设隐藏层的激活函数是f(x)=x,那么前向传播为:t这里好像很混乱,这里明显代表是第t步,ot应该是一个实数,怎么下面又是表示向量?
因为每个时间步都有一个输出,所以总的损失为每个时间步损失的和:
在反向传播时,对ot(ot有q维,这里q=3,即o1,o2,o3)有: 这一步有啥意义?
这一步有啥意义?
对输出层来说,Wqh的梯度为: 
而ht的情况则比较复杂,因为除了h3是只跟L有关,其他如h2就必须依赖h3,h1必须依赖h2和h3,所以分为t=T和t
当t
t
最终,我们得到了参数的梯度,注意我们这里激活函数f(x)=x,因此省略了一步,实际上最终结果还应该包含一个激活函数的导数(注意这里ht-1可以理解为是在当前层已经是实数了,不用继续求导),从这里看的话,好像RNN用Sigmoid激活函数也没关系?毕竟上下时间步用的是用一套参数?:
附加内容,上面的通项公式,从t=T倒推比较容易看出来:
6.5 长程依赖问题
什么是长程依赖问题?
理论上来说,RNN相比于传统神经网络具有记忆力,因此可以建模长距离依赖关系,但实际上由于梯度消失/爆炸,只能学习到短期依赖,这种无法学习到长距离依赖的情况,称为长程依赖问题。
什么是梯度消失/爆炸?为什么会出现?怎么解决?
为什么出现梯度消失或爆炸:
梯度消失/爆炸是指在反向传播时,隐藏层的梯度逐渐趋于0或无穷大,从而导致梯度消失或爆炸。
原因:
上面RNN中隐藏层梯度的计算公式如下:
在这个公式中,WThh的幂度有可能是非常大的,当T很大,或者i很小的时候,矩阵WThh小于1的特征值将会消失,大于1的特征值将会发散,这在数值上是不稳定的,表现形式为梯度消失或梯度爆炸(注意这里是指更远距离的梯度会出现梯度消失,即幂数较大的,其实近距离的是没问题的,因为这是个求和,近距离的梯度还是存在的,只是远距离的较难传播过来)。直观的理解,假如WThh是一个实数,例如0.5,那么0.5的幂如果非常大的话,就会趋近于0,出现梯度消失;如果WThh=2,当幂非常大的时候,就会趋于无穷大,出现梯度爆炸。注意,梯度消失更精确的原因是 消失了,从而影响到了
消失了,从而影响到了 ,即对隐藏层的梯度消失了,导致对参数矩阵的梯度消失了。
,即对隐藏层的梯度消失了,导致对参数矩阵的梯度消失了。
缓解:
梯度爆炸:梯度爆炸一般比较容易解决,通过权重衰减和梯度截断可以有效避免,权重衰减是通过L1或L2正则来限制参数的取值范围,梯度截断则是直接对梯度结果进行截断,超过一定阈值时,取固定值,也避免了梯度持续的增大。
梯度消失:梯度消失是RNN的主要问题。
- 梯度裁剪
- 使用合理的参数初始化方案,如He初始化。合理的初始化方案,可以确保Whh更加合理,从而缓解梯度消失。但这个方案比较依赖人工经验,且比较难到达良好效果。
- 使用 ReLU、LReLU、ELU、maxout 等激活函数,sigmoid函数的梯度随着x的增大或减小和消失,而ReLU不会。但这个并没有解决Whh的问题
- 使用BN,使得输入中心化,一定程度上缓解Sigmoid函数的问题。
- 残差结构
RNN中的梯度消失和前馈神经网络中的梯度消失有什么不同?
前馈神经网络的梯度消失是由于激活函数引起的,而RNN中除了激活函数外,还有隐藏层的长距离依赖引起的。6.6 基于门控的RNN
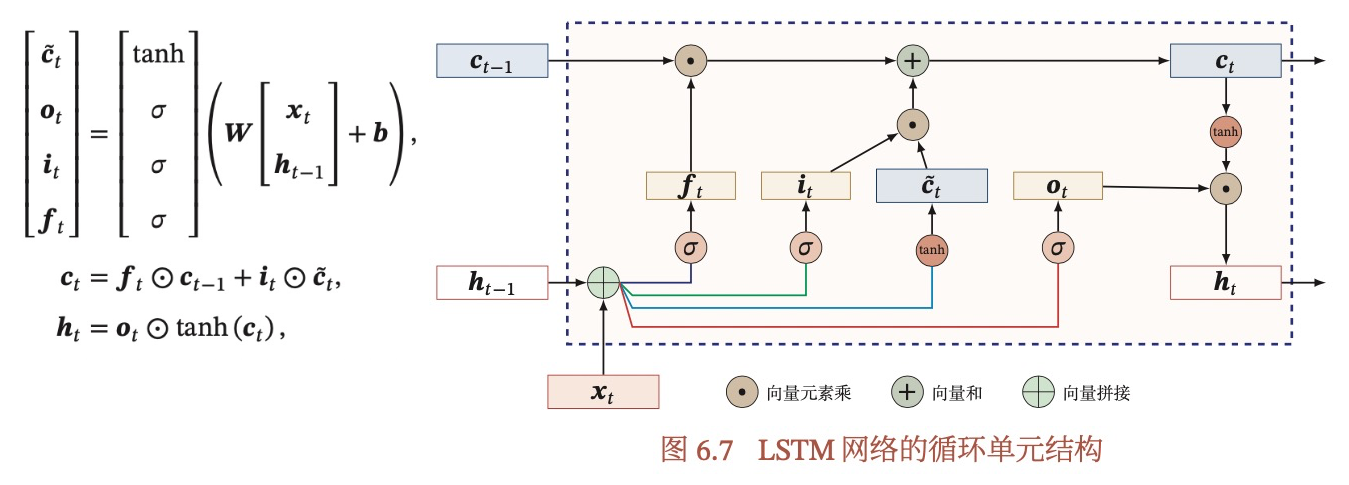
为什么要有LSTM?介绍一下LSTM,比RNN的改进在哪里?
LSTM是为了解决普通RNN的梯度消失或爆炸问题,通过引入一个新的内部状态(即记忆细胞)和门控机制,实现了信息的远距离传递。普通RNN中,隐藏太在每个时刻都会被重写,因此称为短期记忆,而通过记忆细胞,LSTM能够把某个时刻的短期记忆保存较长的时间,这也是LSTM中文名称长-短期记忆网络的名字由来。
LSTM有3个门(输入门i,输出门o和遗忘门f)和两个细胞(候选记忆细胞 ,记忆细胞c)
,记忆细胞c)
- 输入门:logistic函数,控制当前记忆细胞从候选细胞获取多少信息
- 输出门:logistic函数,控制当前记忆细胞有多少信息需要输出
- 遗忘门:logistic函数,控制当前记忆细胞需要从上一个记忆细胞获取多少信息
候选细胞是用结合上一个隐层状态和当前的输入信息,经过tanh得来。
- 先算候选细胞
- 通过3个门,控制当前细胞和输出
介绍一下GRU,比RNN的改进在哪里?
GRU也是引入门控机制来控制信息的更新,但是没有记忆细胞。
GRU通过更新门z和重置门r来实现LSTM同样的功能。更新门同时控制从上一个隐藏态和候选状态的信息,实现了LSTM中遗忘门和输入门的作用;重置门用来控制候选状态从上一个状态获取的信息量。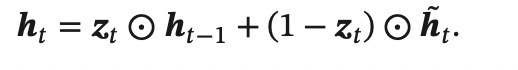
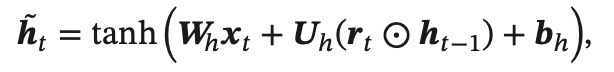
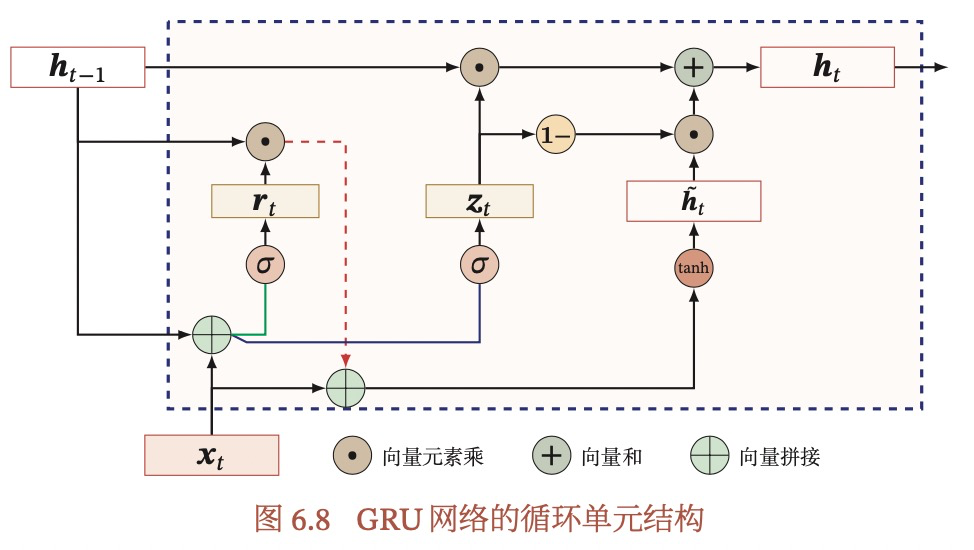
GRU为什么选择了Tanh作为激活函数?
6.8 扩展到图结构
循环神经网络(Recurrent)与递归神经网络和图神经网络的关系?
递归神经网络是RNN在树状层次的扩展,图神经网络是将信息传递的思想扩展到图上。

若有收获,就点个赞吧
0 人点赞
