sync.Pool 是一个临时对象池。一句话来概括,sync.Pool 管理了一组临时对象,当需要时从池中获取,使用完毕后从再放回池中,以供他人使用。
Pool 结构体
type Pool struct {noCopy noCopy// 每个 P 的本地队列,实际类型为 [P]poolLocallocal unsafe.Pointer // local fixed-size per-P pool, actual type is [P]poolLocal// [P]poolLocal的大小localSize uintptr // size of the local arrayvictim unsafe.Pointer // local from previous cyclevictimSize uintptr // size of victims array// 自定义的对象创建回调函数,当 pool 中无可用对象时会调用此函数New func() interface{}}
因为 Pool 不希望被复制,所以结构体里有一个 noCopy 的字段,使用 go vet 工具可以检测到用户代码是否复制了 Pool。
noCopy的实现非常简单:
// noCopy 用于嵌入一个结构体中来保证其第一次使用后不会被复制//// 见 https://golang.org/issues/8005#issuecomment-190753527type noCopy struct{}// Lock 是一个空操作用来给 `go vet` 的 -copylocks 静态分析func (*noCopy) Lock() {}func (*noCopy) Unlock() {}
local 字段存储指向 [P]poolLocal 数组(严格来说,它是一个切片)的指针,localSize 则表示 local 数组的大小。访问时,P 的 id 对应 [P]poolLocal 下标索引。通过这样的设计,多个 goroutine 使用同一个 Pool 时,减少了竞争,提升了性能。
在一轮 GC 到来时,victim 和 victimSize 会分别“接管” local 和 localSize。victim 的机制用于减少 GC 后冷启动导致的性能抖动,让分配对象更平滑。
Victim Cache 本来是计算机架构里面的一个概念,是 CPU 硬件处理缓存的一种技术,sync.Pool 引入的意图在于降低 GC 压力的同时提高命中率。
底层结构
上面已经看到 sync.Pool 内部本质上保存了一个 poolLocal 数组,每个 poolLocal 都只被一个 P 拥有
type poolLocal struct {poolLocalInternal// 将 poolLocal 补齐至两个缓存行的倍数,防止 false sharing,// 每个缓存行具有 64 bytes,即 512 bit// 目前我们的处理器一般拥有 32 * 1024 / 64 = 512 条缓存行// 伪共享,仅占位用,防止在 cache line 上分配多个 poolLocalInternalpad [128 - unsafe.Sizeof(poolLocalInternal{})%128]byte}// Local per-P Pool appendix.type poolLocalInternal struct {// P 的私有缓存区,使用时无需要加锁private interface{}// 公共缓存区。本地 P 可以 pushHead/popHead;其他 P 则只能 popTailshared poolChain}
字段 pad 主要是防止 false sharing,董大的《什么是 cpu cache》里讲得比较好:
现代 cpu 中,cache 都划分成以 cache line (cache block) 为单位,在 x86_64 体系下一般都是 64 字节,cache line 是操作的最小单元。 程序即使只想读内存中的 1 个字节数据,也要同时把附近 63 节字加载到 cache 中,如果读取超个 64 字节,那么就要加载到多个 cache line 中。
简单来说,如果没有 pad 字段,那么当需要访问 0 号索引的 poolLocal 时,CPU 同时会把 0 号和 1 号索引同时加载到 cpu cache。在只修改 0 号索引的情况下,会让 1 号索引的 poolLocal 失效。这样,当其他线程想要读取 1 号索引时,发生 cache miss,还得重新再加载,对性能有损。增加一个 pad,补齐缓存行,让相关的字段能独立地加载到缓存行就不会出现 false sharding 了。
poolChain 是一个双端队列的实现:
type poolChain struct {// 只有生产者会 push to,不用加锁head *poolChainElt// 读写需要原子控制。 pop fromtail *poolChainElt}type poolChainElt struct {poolDequeue// next 被 producer 写,consumer 读。所以只会从 nil 变成 non-nil// prev 被 consumer 写,producer 读。所以只会从 non-nil 变成 nilnext, prev *poolChainElt}type poolDequeue struct {// The head index is stored in the most-significant bits so// that we can atomically add to it and the overflow is// harmless.// headTail 包含一个 32 位的 head 和一个 32 位的 tail 指针。这两个值都和 len(vals)-1 取模过。// tail 是队列中最老的数据,head 指向下一个将要填充的 slot// slots 的有效范围是 [tail, head),由 consumers 持有。headTail uint64// vals 是一个存储 interface{} 的环形队列,它的 size 必须是 2 的幂// 如果 slot 为空,则 vals[i].typ 为空;否则,非空。// 一个 slot 在这时宣告无效:tail 不指向它了,vals[i].typ 为 nil// 由 consumer 设置成 nil,由 producer 读vals []eface}
poolDequeue 被实现为单生产者、多消费者的固定大小的无锁(atomic 实现) Ring 式队列(底层存储使用数组,使用两个指针标记 head、tail)。生产者可以从 head 插入、head 删除,而消费者仅可从 tail 删除。
headTail指向队列的头和尾,通过位运算将 head 和 tail 存入 headTail 变量中
我们用一幅图来完整地描述 Pool 结构体: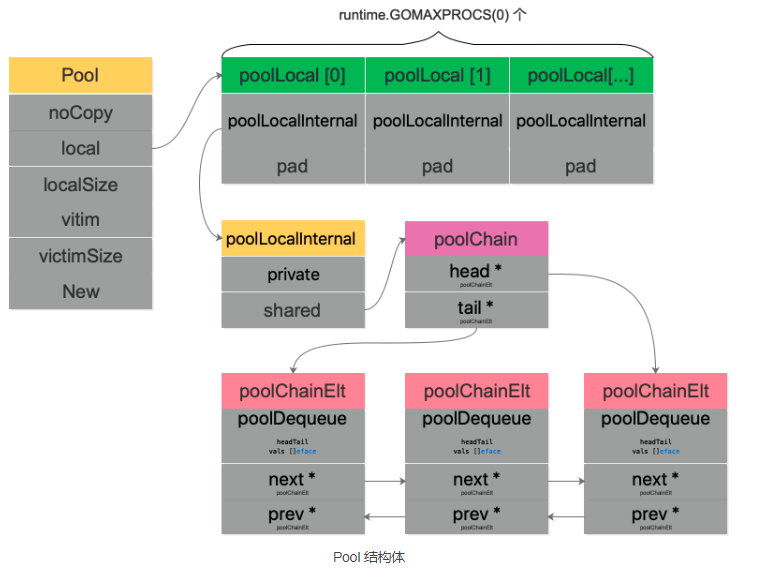
结合木白的技术私厨的《请问sync.Pool有什么缺点?》里的一张图,对于双端队列的理解会更容易一些: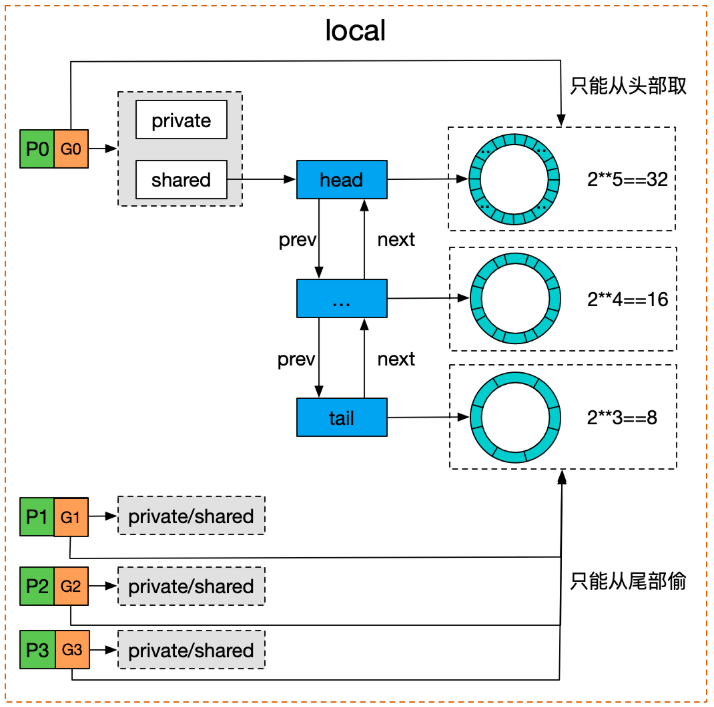
我们看到 Pool 并没有直接使用 poolDequeue,原因是它的大小是固定的,而 Pool 的大小是没有限制的。因此,在 poolDequeue 之上包装了一下,变成了一个 poolChainElt 的双向链表,可以动态增长。
Get
func (p *Pool) Get() interface{} {// ......l, pid := p.pin()x := l.privatel.private = nilif x == nil {x, _ = l.shared.popHead()if x == nil {x = p.getSlow(pid)}}runtime_procUnpin()// ......if x == nil && p.New != nil {x = p.New()}return x}
省略号的内容是 race 相关的,属于阅读源码过程中的一些噪音,暂时注释掉。这样,Get 的整个过程就非常清晰了:
- 首先,调用
p.pin()函数将当前的 goroutine 和 P 绑定,禁止被抢占,返回当前 P 对应的 poolLocal,以及 pid。 - 然后直接取 l.private,赋值给 x,并置 l.private 为 nil。
- 判断 x 是否为空,若为空,则尝试从 l.shared 的头部 pop 一个对象出来,同时赋值给 x。
- 如果 x 仍然为空,则调用 getSlow 尝试从其他 P 的 shared 双端队列尾部“偷”一个对象出来。
- Pool 的相关操作做完了,调用
runtime_procUnpin()解除非抢占。 - 最后如果还是没有取到缓存的对象,那就直接调用预先设置好的 New 函数,创建一个出来。
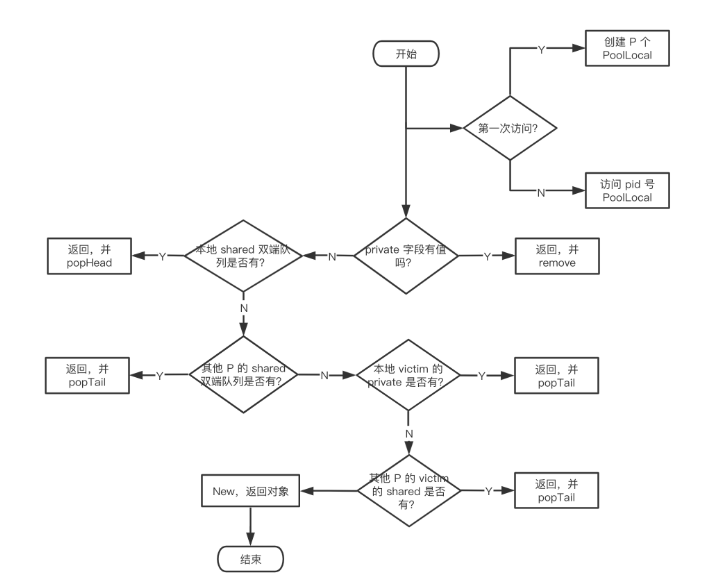
pin
// src/sync/pool.go// pin 会将当前 goroutine 订到 P 上, 禁止抢占(preemption) 并从 poolLocal 池中返回 P 对应的 poolLocal// 调用方必须在完成取值后调用 runtime_procUnpin() 来取消抢占。func (p *Pool) pin() *poolLocal {// 返回当前 P.idpid := runtime_procPin()// 在 pinSlow 中会存储 localSize 后再存储 local,因此这里反过来读取// 因为我们已经禁用了抢占,这时不会发生 GC// 因此,我们必须观察 local 和 localSize 是否对应// 观察到一个全新或很大的的 local 是正常行为s := atomic.LoadUintptr(&p.localSize) // load-acquirel := p.local // load-consume// 因为可能存在动态的 P(运行时调整 P 的个数)procresize/GOMAXPROCS// 如果 P.id 没有越界,则直接返回if uintptr(pid) < s {return indexLocal(l, pid)}// 没有结果时,涉及全局加锁// 例如重新分配数组内存,添加到全局列表return p.pinSlow()}
pin() 首先会调用运行时实现获得当前 P 的 id,将 P 设置为禁止抢占。然后检查 pid 与 p.localSize 的值 来确保从 p.local 中取值不会发生越界。如果不会发生,则调用 indexLocal() 完成取值。否则还需要继续调用 pinSlow()。
func indexLocal(l unsafe.Pointer, i int) *poolLocal {// 简单的通过 p.local 的头指针与索引来第 i 个 pooLocallp := unsafe.Pointer(uintptr(l) + uintptr(i)*unsafe.Sizeof(poolLocal{}))return (*poolLocal)(lp)}
在这个过程中我们可以看到在运行时调整 P 的大小的代价。如果此时 P 被调大,而没有对应的 poolLocal 时, 必须在取之前创建好,从而必须依赖全局加锁,这对于以性能著称的池化概念是比较致命的,因此这也是 pinSlow 的由来。
popHead
回到 Get 函数,再来看另一个关键的函数:poolChain.popHead()
func (c *poolChain) popHead() (interface{}, bool) {d := c.headfor d != nil {if val, ok := d.popHead(); ok {return val, ok}// There may still be unconsumed elements in the// previous dequeue, so try backing up.d = loadPoolChainElt(&d.prev)}return nil, false}
popHead 函数只会被 producer 调用。首先拿到头节点:c.head,如果头节点不为空的话,尝试调用头节点的 popHead 方法。注意这两个 popHead 方法实际上并不相同,一个是 poolChain 的,一个是 poolDequeue 的,有疑惑的,不妨回头再看一下 Pool 结构体的图。我们来看 poolDequeue.popHead():
// /usr/local/go/src/sync/poolqueue.gofunc (d *poolDequeue) popHead() (interface{}, bool) {var slot *efacefor {ptrs := atomic.LoadUint64(&d.headTail)head, tail := d.unpack(ptrs)// 判断队列是否为空if tail == head {// Queue is empty.return nil, false}// head 位置是队头的前一个位置,所以此处要先退一位。// 在读出 slot 的 value 之前就把 head 值减 1,取消对这个 slot 的控制head--ptrs2 := d.pack(head, tail)if atomic.CompareAndSwapUint64(&d.headTail, ptrs, ptrs2) {// We successfully took back slot.slot = &d.vals[head&uint32(len(d.vals)-1)]break}}// 取出 valval := *(*interface{})(unsafe.Pointer(slot))if val == dequeueNil(nil) {val = nil}// 重置 slot,typ 和 val 均为 nil// 这里清空的方式与 popTail 不同,与 pushHead 没有竞争关系,所以不用太小心*slot = eface{}return val, true}
此函数会删掉并且返回 queue 的头节点。但如果 queue 为空的话,返回 false。这里的 queue 存储的实际上就是 Pool 里缓存的对象。
整个函数的核心是一个无限循环,这是 Go 中常用的无锁化编程形式。
首先调用 unpack 函数分离出 head 和 tail 指针,如果 head 和 tail 相等,即首尾相等,那么这个队列就是空的,直接就返回 nil,false。
否则,将 head 指针后移一位,即 head 值减 1,然后调用 pack 打包 head 和 tail 指针。使用 atomic.CompareAndSwapUint64 比较 headTail 在这之间是否有变化,如果没变化,相当于获取到了这把锁,那就更新 headTail 的值。并且把 vals 相应索引处的元素赋值给 slot。
因为 vals 长度实际是只能是 2 的 n 次幂,因此 len(d.vals)-1 实际上得到的值的低 n 位是全 1,它再与 head 相与,实际就是取 head 低 n 位的值。
得到相应 slot 的元素后,经过类型转换并判断是否是 dequeueNil,如果是,说明没取到缓存的对象,返回 nil。
// /usr/local/go/src/sync/poolqueue.go// 因为使用 nil 代表空的 slots,因此使用 dequeueNil 表示 interface{}(nil)type dequeueNil *struct{}
最后,返回 val 之前,将 slot “归零”:*slot = eface{}。
回到 poolChain.popHead(),调用 poolDequeue.popHead() 拿到缓存的对象后,直接返回。否则,将 d 重新指向 d.prev,继续尝试获取缓存的对象。
pinSlow
因为需要对全局进行加锁,pinSlow() 会首先取消 P 的不可抢占,然后使用 allPoolsMu 进行加锁:
var (allPoolsMu MutexallPools []*Pool)
当完成加锁后,再重新固定 P ,取其 pid。注意,因为中途可能已经被其他的线程调用,因此这时候需要再次对 pid 进行检查。 如果 pid 在 p.local 大小范围内,则不再此时创建,直接返回。
如果 p.local 为空,则将 p 扔给 allPools 并在垃圾回收阶段回收所有 Pool 实例。 最后再完成对 p.local 的创建(彻底丢弃旧数组)
func (p *Pool) pinSlow() (*poolLocal, int) {// Retry under the mutex.// Can not lock the mutex while pinned.runtime_procUnpin()allPoolsMu.Lock()defer allPoolsMu.Unlock()pid := runtime_procPin()// poolCleanup won't be called while we are pinned.// 没有使用原子操作,因为已经加了全局锁了s := p.localSizel := p.local// 因为 pinSlow 中途可能已经被其他的线程调用,因此这时候需要再次对 pid 进行检查。 如果 pid 在 p.local 大小范围内,则不用创建 poolLocal 切片,直接返回。if uintptr(pid) < s {return indexLocal(l, pid), pid}if p.local == nil {allPools = append(allPools, p)}// If GOMAXPROCS changes between GCs, we re-allocate the array and lose the old one.// 当前 P 的数量size := runtime.GOMAXPROCS(0)local := make([]poolLocal, size)// 旧的 local 会被回收atomic.StorePointer(&p.local, unsafe.Pointer(&local[0])) // store-releaseatomic.StoreUintptr(&p.localSize, uintptr(size)) // store-releasereturn &local[pid], pid}
getSlow
终于,我们获取到了 poolLocal。就回到了我们从中取值的过程。在取对象的过程中,我们仍然会面临 既不能从 private 取、也不能从 shared 中取得尴尬境地。这时候就来到了 getSlow()。
试想,如果我们在本地的 P 中取不到值,是不是可以考虑从别人那里偷一点过来?总会比创建一个新的要快。 因此,我们再次固定 P,并取得当前的 P.id 来从其他 P 中偷值,那么我们需要先获取到其他 P 对应的 poolLocal。假设 size 为数组的大小,local 为 p.local,那么尝试遍历其他所有 P:
for i := 0; i < int(size); i++ {// 获取目标 poolLocal, 引入 pid 保证不是自身l := indexLocal(local, (pid+i+1)%int(size))}
我们来证明一下此处确实不会发生取到自身的情况,不妨设:pid = (pid+i+1)%size 则 pid+i+1 = a*size+pid。 即:a*size = i+1,其中 a 为整数。由于 i<size,于是 a*size = i+1 < size+1,则: (a-1)*size < 1 ==> size < 1 / (a-1),由于 size 为非负整数,这是不可能的。
因此当取到其他 poolLocal 时,便能从 shared 中取对象了。
func (p *Pool) getSlow(pid int) interface{} {// See the comment in pin regarding ordering of the loads.size := atomic.LoadUintptr(&p.localSize) // load-acquirelocals := p.local // load-consume// Try to steal one element from other procs.// 从其他 P 中窃取对象for i := 0; i < int(size); i++ {l := indexLocal(locals, (pid+i+1)%int(size))if x, _ := l.shared.popTail(); x != nil {return x}}// 尝试从victim cache中取对象。这发生在尝试从其他 P 的 poolLocal 偷去失败后,// 因为这样可以使 victim 中的对象更容易被回收。size = atomic.LoadUintptr(&p.victimSize)if uintptr(pid) >= size {return nil}locals = p.victiml := indexLocal(locals, pid)if x := l.private; x != nil {l.private = nilreturn x}for i := 0; i < int(size); i++ {l := indexLocal(locals, (pid+i)%int(size))if x, _ := l.shared.popTail(); x != nil {return x}}// 清空 victim cache。下次就不用再从这里找了atomic.StoreUintptr(&p.victimSize, 0)return nil}
popTail
最后,还剩一个 popTail 函数:
func (c *poolChain) popTail() (interface{}, bool) {
d := loadPoolChainElt(&c.tail)
if d == nil {
return nil, false
}
for {
d2 := loadPoolChainElt(&d.next)
if val, ok := d.popTail(); ok {
return val, ok
}
if d2 == nil {
// 双向链表只有一个尾节点,现在为空
return nil, false
}
// 双向链表的尾节点里的双端队列被“掏空”,所以继续看下一个节点。
// 并且由于尾节点已经被“掏空”,所以要甩掉它。这样,下次 popHead 就不会再看它有没有缓存对象了。
if atomic.CompareAndSwapPointer((*unsafe.Pointer)(unsafe.Pointer(&c.tail)), unsafe.Pointer(d), unsafe.Pointer(d2)) {
// 甩掉尾节点
storePoolChainElt(&d2.prev, nil)
}
d = d2
}
}
在 for 循环的一开始,就把 d.next 加载到了 d2。因为 d 可能会短暂为空,但如果 d2 在 pop 或者 pop fails 之前就不为空的话,说明 d 就会永久为空了。在这种情况下,可以安全地将 d 这个结点“甩掉”。
最后,将 c.tail 更新为 d2,可以防止下次 popTail 的时候查看一个空的 dequeue;而将 d2.prev 设置为 nil,可以防止下次 popHead 时查看一个空的 dequeue。
我们再看一下核心的 poolDequeue.popTail:
// src/sync/poolqueue.go:147
func (d *poolDequeue) popTail() (interface{}, bool) {
var slot *eface
for {
ptrs := atomic.LoadUint64(&d.headTail)
head, tail := d.unpack(ptrs)
// 判断队列是否空
if tail == head {
// Queue is empty.
return nil, false
}
// 先搞定 head 和 tail 指针位置。如果搞定,那么这个 slot 就归属我们了
ptrs2 := d.pack(head, tail+1)
if atomic.CompareAndSwapUint64(&d.headTail, ptrs, ptrs2) {
// Success.
slot = &d.vals[tail&uint32(len(d.vals)-1)]
break
}
}
// We now own slot.
val := *(*interface{})(unsafe.Pointer(slot))
if val == dequeueNil(nil) {
val = nil
}
slot.val = nil
atomic.StorePointer(&slot.typ, nil)
// At this point pushHead owns the slot.
return val, true
}
popTail 从队列尾部移除一个元素,如果队列为空,返回 false。此函数可能同时被多个消费者调用。
函数的核心是一个无限循环,又是一个无锁编程。先解出 head,tail 指针值,如果两者相等,说明队列为空。
因为要从尾部移除一个元素,所以 tail 指针前进 1,然后使用原子操作设置 headTail。
最后,将要移除的 slot 的 val 和 typ “归零”:
slot.val = nil
atomic.StorePointer(&slot.typ, nil)
Put
// src/sync/pool.go
// Put 将对象添加到 Pool
func (p *Pool) Put(x interface{}) {
if x == nil {
return
}
// ……
l, _ := p.pin()
if l.private == nil {
l.private = x
x = nil
}
if x != nil {
l.shared.pushHead(x)
}
runtime_procUnpin()
//……
}
同样删掉了 race 相关的函数,看起来清爽多了。整个 Put 的逻辑也很清晰:
- 先绑定 g 和 P,然后尝试将 x 赋值给 private 字段。
- 如果失败,就调用
pushHead方法尝试将其放入 shared 字段所维护的双端队列中。
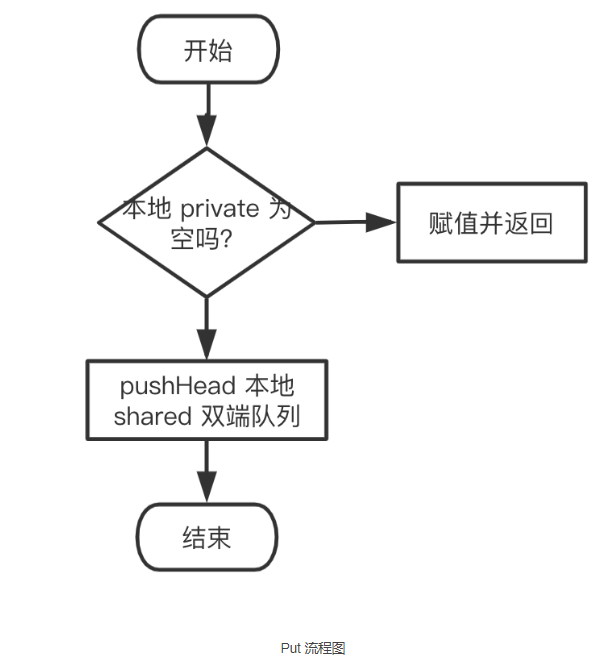
pushHead
我们来看 pushHead 的源码,比较清晰:
// src/sync/poolqueue.go
func (c *poolChain) pushHead(val interface{}) {
d := c.head
if d == nil {
// poolDequeue 初始长度为8
const initSize = 8 // Must be a power of 2
d = new(poolChainElt)
d.vals = make([]eface, initSize)
c.head = d
storePoolChainElt(&c.tail, d)
}
if d.pushHead(val) {
return
}
// 前一个 poolDequeue 长度的 2 倍
newSize := len(d.vals) * 2
if newSize >= dequeueLimit {
// Can't make it any bigger.
newSize = dequeueLimit
}
// 首尾相连,构成链表
d2 := &poolChainElt{prev: d}
d2.vals = make([]eface, newSize)
c.head = d2
storePoolChainElt(&d.next, d2)
d2.pushHead(val)
}
如果 c.head 为空,就要创建一个 poolChainElt,作为首结点,当然也是尾节点。它管理的双端队列的长度,初始为 8,放满之后,再创建一个 poolChainElt 节点时,双端队列的长度就要翻倍。当然,有一个最大长度限制(2^30):
const dequeueBits = 32
const dequeueLimit = (1 << dequeueBits) / 4
调用 poolDequeue.pushHead 尝试将对象放到 poolDeque 里去:
// src/sync/poolqueue.go
// 将 val 添加到双端队列头部。如果队列已满,则返回 false。此函数只能被一个生产者调用
func (d *poolDequeue) pushHead(val interface{}) bool {
ptrs := atomic.LoadUint64(&d.headTail)
head, tail := d.unpack(ptrs)
if (tail+uint32(len(d.vals)))&(1<<dequeueBits-1) == head {
// 队列满了
return false
}
slot := &d.vals[head&uint32(len(d.vals)-1)]
// 检测这个 slot 是否被 popTail 释放
typ := atomic.LoadPointer(&slot.typ)
if typ != nil {
// 另一个 groutine 正在 popTail 这个 slot,说明队列仍然是满的
return false
}
// The head slot is free, so we own it.
if val == nil {
val = dequeueNil(nil)
}
// slot占位,将val存入vals中
*(*interface{})(unsafe.Pointer(slot)) = val
// head 增加 1
atomic.AddUint64(&d.headTail, 1<<dequeueBits)
return true
}
首先判断队列是否已满:
if (tail+uint32(len(d.vals)))&(1<<dequeueBits-1) == head {
// Queue is full.
return false
}
也就是将尾部指针加上 d.vals 的长度,再取低 31 位,看它是否和 head 相等。我们知道,d.vals 的长度实际上是固定的,因此如果队列已满,那么 if 语句的两边就是相等的。如果队列满了,直接返回 false。
否则,队列没满,通过 head 指针找到即将填充的 slot 位置:取 head 指针的低 31 位。
// Check if the head slot has been released by popTail.
typ := atomic.LoadPointer(&slot.typ)
if typ != nil {
// Another goroutine is still cleaning up the tail, so
// the queue is actually still full.
// popTail 是先设置 val,再将 typ 设置为 nil。设置完 typ 之后,popHead 才可以操作这个 slot
return false
}
上面这一段用来判断是否和 popTail 有冲突发生,如果有,则直接返回 false。
最后,将 val 赋值到 slot,并将 head 指针值加 1。
// slot占位,将val存入vals中
*(*interface{})(unsafe.Pointer(slot)) = val
这里的实现比较巧妙,slot 是 eface 类型,将 slot 转为 interface{} 类型,这样 val 能以 interface{} 赋值给 slot 让 slot.typ 和 slot.val 指向其内存块,于是 slot.typ 和 slot.val 均不为空。
pack/unpack
最后我们再来看一下 pack 和 unpack 函数,它们实际上是一组绑定、解绑 head 和 tail 指针的两个函数。
// src/sync/poolqueue.go
const dequeueBits = 32
func (d *poolDequeue) pack(head, tail uint32) uint64 {
const mask = 1<<dequeueBits - 1
return (uint64(head) << dequeueBits) |
uint64(tail&mask)
}
mask 的低 31 位为全 1,其他位为 0,它和 tail 相与,就是只看 tail 的低 31 位。而 head 向左移 32 位之后,低 32 位为全 0。最后把两部分“或”起来,head 和 tail 就“绑定”在一起了。
相应的解绑函数:
func (d *poolDequeue) unpack(ptrs uint64) (head, tail uint32) {
const mask = 1<<dequeueBits - 1
head = uint32((ptrs >> dequeueBits) & mask)
tail = uint32(ptrs & mask)
return
}
取出 head 指针的方法就是将 ptrs 右移 32 位,再与 mask 相与,同样只看 head 的低 31 位。而 tail 实际上更简单,直接将 ptrs 与 mask 相与就可以了。
GC
对于 Pool 而言,并不能无限扩展,否则对象占用内存太多了,会引起内存溢出。
几乎所有的池技术中,都会在某个时刻清空或清除部分缓存对象,那么在 Go 中何时清理未使用的对象呢?
答案是 GC 发生时。
在 pool.go 文件的 init 函数里,注册了 GC 发生时,如何清理 Pool 的函数:
// src/sync/pool.go
func init() {
runtime_registerPoolCleanup(poolCleanup)
}
编译器在背后做了一些动作:
// src/runtime/mgc.go
// Hooks for other packages
var poolcleanup func()
// 利用编译器标志将 sync 包中的清理注册到运行时
//go:linkname sync_runtime_registerPoolCleanup sync.runtime_registerPoolCleanup
func sync_runtime_registerPoolCleanup(f func()) {
poolcleanup = f
}
具体来看下:
func poolCleanup() {
for _, p := range oldPools {
p.victim = nil
p.victimSize = 0
}
// Move primary cache to victim cache.
for _, p := range allPools {
p.victim = p.local
p.victimSize = p.localSize
p.local = nil
p.localSize = 0
}
oldPools, allPools = allPools, nil
}
poolCleanup 会在 STW 阶段被调用。整体看起来,比较简洁。主要是将 local 和 victim 作交换,这样也就不致于让 GC 把所有的 Pool 都清空了,有 victim 在“兜底”。
如果 sync.Pool 的获取、释放速度稳定,那么就不会有新的池对象进行分配。如果获取的速度下降了,那么对象可能会在两个 GC 周期内被释放,而不是以前的一个 GC 周期。
鸟窝的【Go 1.13中 sync.Pool 是如何优化的?】讲了 1.13 中的优化。
参考资料【理解 Go 1.13 中 sync.Pool 的设计与实现】 手动模拟了一下调用 poolCleanup 函数前后 oldPools,allPools,p.vitcim 的变化过程,很精彩:
- 初始状态下,oldPools 和 allPools 均为 nil。
- 第 1 次调用 Get,由于 p.local 为 nil,将会在 pinSlow 中创建 p.local,然后将 p 放入 allPools,此时 allPools 长度为 1,oldPools 为 nil。
- 对象使用完毕,第 1 次调用 Put 放回对象。
- 第 1 次GC STW 阶段,allPools 中所有 p.local 将值赋值给 victim 并置为 nil。allPools 赋值给 oldPools,最后 allPools 为 nil,oldPools 长度为 1。
- 第 2 次调用 Get,由于 p.local 为 nil,此时会从 p.victim 里面尝试取对象。
- 对象使用完毕,第 2 次调用 Put 放回对象,但由于 p.local 为 nil,重新创建 p.local,并将对象放回,此时 allPools 长度为 1,oldPools 长度为 1。
- 第 2 次 GC STW 阶段,oldPools 中所有 p.victim 置 nil,前一次的 cache 在本次 GC 时被回收,allPools 所有 p.local 将值赋值给 victim 并置为nil,最后 allPools 为 nil,oldPools 长度为 1。
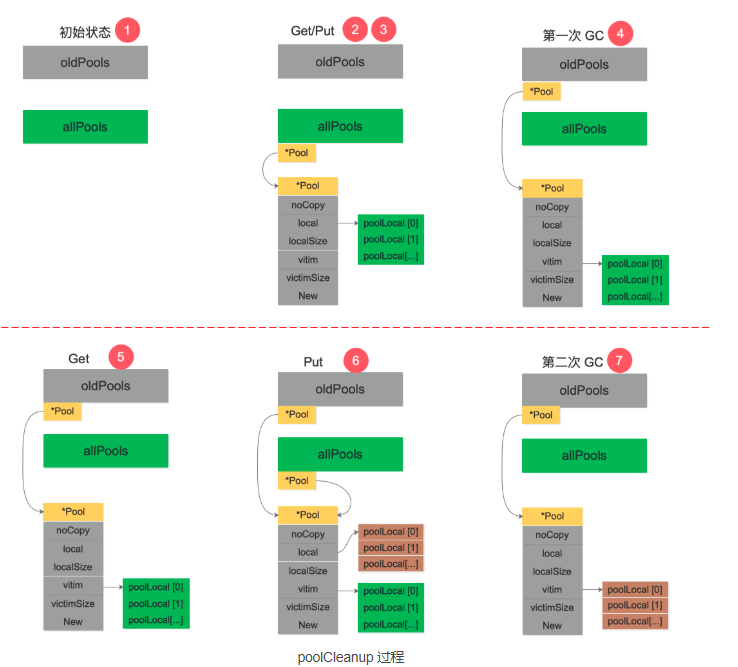
需要指出的是,allPools 和 oldPools 都是切片,切片的元素是指向 Pool 的指针,Get/Put 操作不需要通过它们。在第 6 步,如果还有其他 Pool 执行了 Put 操作,allPools 这时就会有多个元素。
在 Go 1.13 之前的实现中,poolCleanup 比较“简单粗暴”:
func poolCleanup() {
for i, p := range allPools {
allPools[i] = nil
for i := 0; i < int(p.localSize); i++ {
l := indexLocal(p.local, i)
l.private = nil
for j := range l.shared {
l.shared[j] = nil
}
l.shared = nil
}
p.local = nil
p.localSize = 0
}
allPools = []*Pool{}
}
直接清空了所有 Pool 的 p.local 和 poolLocal.shared。
通过两者的对比发现,新版的实现相比 Go 1.13 之前,GC 的粒度拉大了,由于实际回收的时间线拉长,单位时间内 GC 的开销减小。
由此基本明白 p.victim 的作用。它的定位是次级缓存,GC 时将对象放入其中,下一次 GC 来临之前如果有 Get 调用则会从 p.victim 中取,直到再一次 GC 来临时回收。 同时由于从 p.victim 中取出对象使用完毕之后并未放回 p.victim 中,在一定程度也减小了下一次 GC 的开销。原来 1 次 GC 的开销被拉长到 2 次且会有一定程度的开销减小,这就是 p.victim 引入的意图。
总结
本文的结尾部分,再来详细地总结一下关于 sync.Pool 的要点:
- 关键思想是对象的复用,避免重复创建、销毁。将暂时不用的对象缓存起来,待下次需要的时候直接使用,不用再次经过内存分配,复用对象的内存,减轻 GC 的压力。
sync.Pool是协程安全的,使用起来非常方便。设置好 New 函数后,调用 Get 获取,调用 Put 归还对象。- Go 语言内置的 fmt 包,encoding/json 包都可以看到 sync.Pool 的身影;
gin,Echo等框架也都使用了 sync.Pool。 - 不要对 Get 得到的对象有任何假设,更好的做法是归还对象时,将对象“清空”。
- Pool 里对象的生命周期受 GC 影响,不适合于做连接池,因为连接池需要自己管理对象的生命周期。
- Pool 不可以指定⼤⼩,⼤⼩只受制于 GC 临界值。
procPin将 G 和 P 绑定,防止 G 被抢占。在绑定期间,GC 无法清理缓存的对象。- 在加入
victim机制前,sync.Pool 里对象的最⼤缓存时间是一个 GC 周期,当 GC 开始时,没有被引⽤的对象都会被清理掉;加入victim机制后,最大缓存时间为两个 GC 周期。 - Victim Cache 本来是计算机架构里面的一个概念,是 CPU 硬件处理缓存的一种技术,
sync.Pool引入的意图在于降低 GC 压力的同时提高命中率。 sync.Pool的最底层使用切片加链表来实现双端队列,并将缓存的对象存储在切片中。
参考资料
【欧神 源码分析】https://changkun.us/archives/2018/09/256/
【Go 夜读】https://reading.hidevops.io/reading/20180817/2018-08-17-sync-pool-reading.pdf
【夜读第 14 期视频】https://www.youtube.com/watch?v=jaepwn2PWPk&list=PLe5svQwVF1L5bNxB0smO8gNfAZQYWdIpI
【源码分析,伪共享】https://juejin.im/post/5d4087276fb9a06adb7fbe4a
【golang的对象池sync.pool源码解读】https://zhuanlan.zhihu.com/p/99710992
【理解 Go 1.13 中 sync.Pool 的设计与实现】https://zhuanlan.zhihu.com/p/110140126
【优缺点,图】http://cbsheng.github.io/posts/golang%E6%A0%87%E5%87%86%E5%BA%93sync.pool%E5%8E%9F%E7%90%86%E5%8F%8A%E6%BA%90%E7%A0%81%E7%AE%80%E6%9E%90/
【xiaorui 优化锁竞争】http://xiaorui.cc/archives/5878
【性能优化之路,自定义多种规格的缓存】https://blog.cyeam.com/golang/2017/02/08/go-optimize-slice-pool
【sync.Pool 有什么缺点】https://mp.weixin.qq.com/s?__biz=MzA4ODg0NDkzOA==&mid=2247487149&idx=1&sn=f38f2d72fd7112e19e97d5a2cd304430&source=41#wechat_redirect
【1.12 和 1.13 的演变】https://github.com/watermelo/dailyTrans/blob/master/golang/sync_pool_understand.md
【董泽润 演进】https://www.jianshu.com/p/2e08332481c5
【noCopy】https://github.com/golang/go/issues/8005#issuecomment-190753527
【董泽润 cpu cache】https://www.jianshu.com/p/dc4b5562aad2
【gomemcache 例子】https://docs.kilvn.com/The-Golang-Standard-Library-by-Example/chapter16/16.01.html
【鸟窝 1.13 优化】https://colobu.com/2019/10/08/how-is-sync-Pool-improved-in-Go-1-13/
【A journey with go】https://medium.com/a-journey-with-go/go-understand-the-design-of-sync-pool-2dde3024e277
【封装了一个计数组件】https://www.akshaydeo.com/blog/2017/12/23/How-did-I-improve-latency-by-700-percent-using-syncPool/
【伪共享】http://ifeve.com/falsesharing/

若有收获,就点个赞吧
0 人点赞

{kind=link}
{kind=link}