设计原理
Go 语言中最常见的、也是经常被人提及的设计模式就是:不要通过共享内存的方式进行通信,而是应该通过通信的方式共享内存。在很多主流的编程语言中,多个线程传递数据的方式一般都是共享内存,为了解决线程竞争,我们需要限制同一时间能够读写这些变量的线程数量,然而这与 Go 语言鼓励的设计并不相同。
先入先出
目前的 Channel 收发操作均遵循了先进先出的设计,具体规则如下:
- 先从 Channel 读取数据的 Goroutine 会先接收到数据;
- 先向 Channel 发送数据的 Goroutine 会得到先发送数据的权利;
无锁管道
锁是一种常见的并发控制技术,我们一般会将锁分成乐观锁和悲观锁,即乐观并发控制和悲观并发控制,无锁(lock-free)队列更准确的描述是使用乐观并发控制的队列。乐观并发控制也叫乐观锁,很多人都会误以为乐观锁是与悲观锁差不多,然而它并不是真正的锁,只是一种并发控制的思想
Go 语言社区也在 2014 年提出了无锁 Channel 的实现方案,该方案将 Channel 分成了以下三种类型:
- 同步 Channel — 不需要缓冲区,发送方会直接将数据交给(Handoff)接收方;
- 异步 Channel — 基于环形缓存的传统生产者消费者模型;
- chan struct{}类型的异步 Channel —struct{}类型不占用内存空间,不需要实现缓冲区和直接发送(Handoff)的语义;
这个提案的目的也不是实现完全无锁的队列,只是在一些关键路径上通过无锁提升 Channel 的性能。社区中已经有无锁 Channel 的实现,但是在实际的基准测试中,无锁队列在多核测试中的表现还需要进一步的改进。
因为目前通过 CAS 实现的无锁 Channel 没有提供先进先出的特性,所以该提案暂时也被搁浅了。
数据结构
Go 语言的 Channel 在运行时使用runtime.hchan结构体表示。我们在 Go 语言中创建新的 Channel 时,实际上创建的都是如下所示的结构:
type hchan struct {qcount uint // buffer 中已放入的元素个数dataqsiz uint // 用户构造 channel 时指定的 buf 大小,也就是底层循环数组的长度buf unsafe.Pointer // 指向底层循环数组的指针 只针对有缓冲的 channelelemsize uint16 // buffer 中每个元素的大小closed uint32 // channel 是否关闭,== 0 代表未 closedelemtype *_type // channel 元素的类型信息sendx uint // 已发送元素在循环数组中的索引recvx uint // 已接收元素在循环数组中的索引recvq waitq // 等待接收的 goroutine list of recv waiterssendq waitq // 等待发送的 goroutine list of send waiterslock mutex // 保护 hchan 中所有字段}
runtime.hchan结构体中的五个字段qcount、dataqsiz、buf、sendx、recv构建底层的循环队列:
- qcount— Channel 中的元素个数;
- dataqsiz— Channel 中的循环队列的长度;
- buf— Channel 的缓冲区数据指针;
- sendx— Channel 的发送操作处理到的位置;
- recvx— Channel 的接收操作处理到的位置;
除此之外,elemsize和elemtype分别表示当前 Channel 能够收发的元素类型和大小;sendq和recvq存储了当前 Channel 由于缓冲区空间不足而阻塞的 Goroutine 列表,这些等待队列使用双向链表runtime.waitq表示,链表中所有的元素都是runtime.sudog结构:
type waitq struct {first *sudoglast *sudog}
runtime.sudog表示一个在等待列表中的 Goroutine,该结构中存储了两个分别指向前后runtime.sudog的指针以构成链表。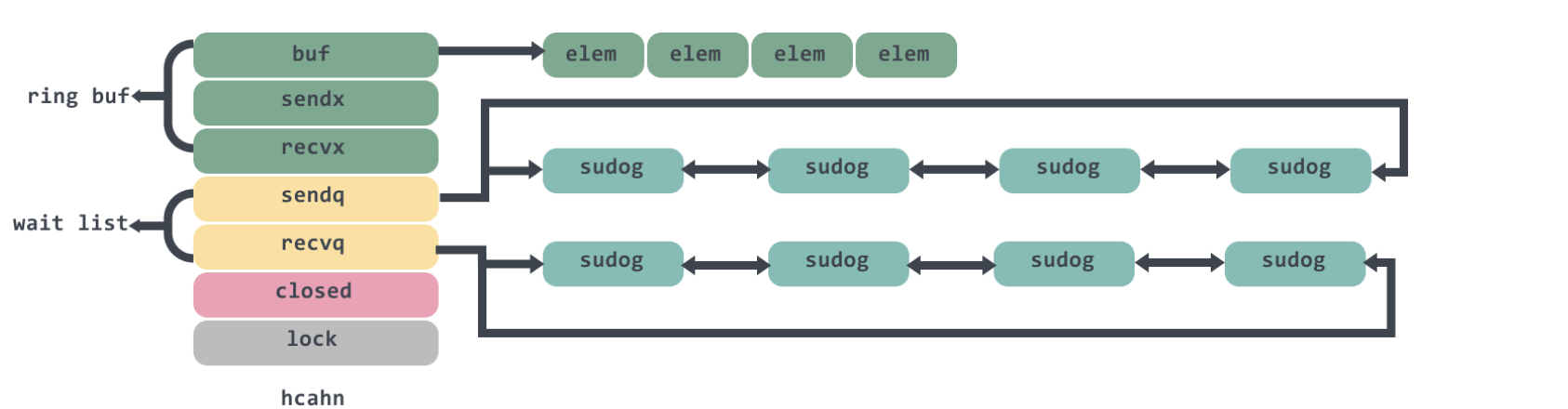
环形队列
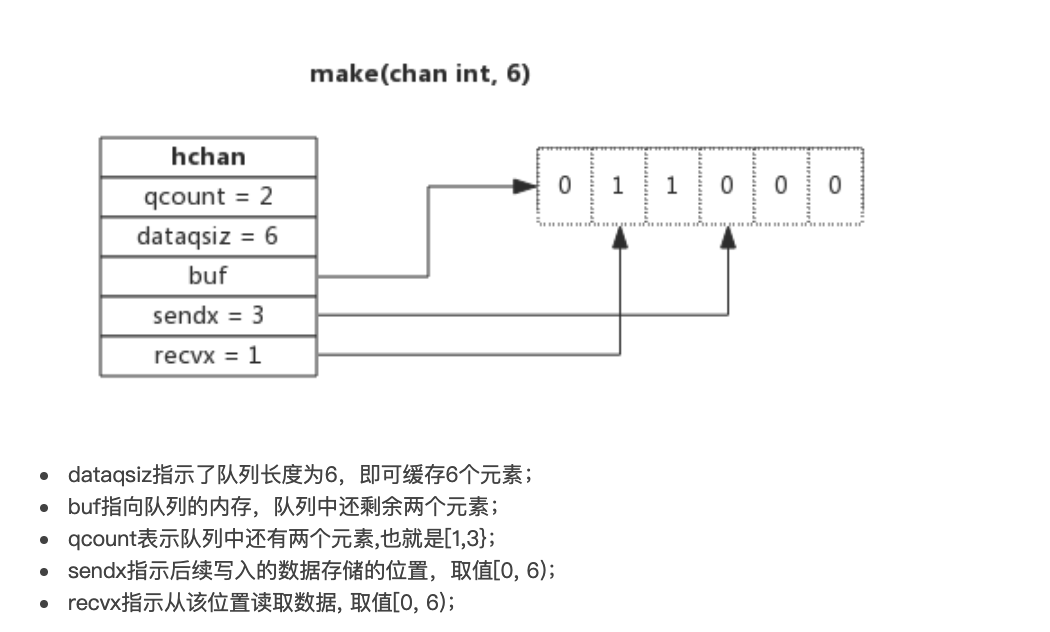
创建管道
Go 语言中所有 Channel 的创建都会使用make关键字。编译器会将make(chan int, 10)表达式被转换成OMAKE类型的节点,并在类型检查阶段将OMAKE类型的节点转换成OMAKECHAN类型:
func typecheck1(n *Node, top int) (res *Node) {switch n.Op {case OMAKE:...switch t.Etype {case TCHAN:l = nilif i < len(args) { // 带缓冲区的异步 Channel...n.Left = l} else { // 不带缓冲区的同步 Channeln.Left = nodintconst(0)}n.Op = OMAKECHAN}}}
这一阶段会对传入make关键字的缓冲区大小进行检查,如果我们不向make传递表示缓冲区大小的参数,那么就会设置一个默认值 0,也就是当前的 Channel 不存在缓冲区。
OMAKECHAN类型的节点最终都会在 SSA 中间代码生成阶段之前被转换成调用runtime.makechan或者runtime.makechan64的函数:
func walkexpr(n *Node, init *Nodes) *Node {switch n.Op {case OMAKECHAN:size := n.Leftfnname := "makechan64"argtype := types.Types[TINT64]if size.Type.IsKind(TIDEAL) || maxintval[size.Type.Etype].Cmp(maxintval[TUINT]) <= 0 {fnname = "makechan"argtype = types.Types[TINT]}n = mkcall1(chanfn(fnname, 1, n.Type), n.Type, init, typename(n.Type), conv(size, argtype))}}
runtime.makechan和runtime.makechan64会根据传入的参数类型和缓冲区大小创建一个新的 Channel 结构,其中后者用于处理缓冲区大小大于 2 的 32 次方的情况,因为这在 Channel 中并不常见,所以我们重点关注runtime.makechan:
func makechan(t *chantype, size int) *hchan {elem := t.elemmem, _ := math.MulUintptr(elem.size, uintptr(size))var c *hchanswitch {case mem == 0:// 队列或元素大小为零// 当前 Channel 中不存在缓冲区,为 runtime.hchan 分配一段内存空间c = (*hchan)(mallocgc(hchanSize, nil, true))c.buf = c.raceaddr()case elem.kind&kindNoPointers != 0:// 类型不是指针// 一次性给channel和buf(也就是底层数组)分类一块连续的空间c = (*hchan)(mallocgc(hchanSize+mem, nil, true))c.buf = add(unsafe.Pointer(c), hchanSize)default:// 默认情况下会单独为 runtime.hchan 和缓冲区分配内存c = new(hchan)c.buf = mallocgc(mem, elem, true)}// 最后更新几个字段的值c.elemsize = uint16(elem.size)c.elemtype = elemc.dataqsiz = uint(size)return c}
上述代码根据 Channel 中收发元素的类型和缓冲区的大小初始化runtime.hchan和缓冲区:
- 如果当前 Channel 中不存在缓冲区,那么就只会为runtime.hchan分配一段内存空间;
- 如果当前 Channel 中存储的类型不是指针类型,会为当前的 Channel 和底层的数组分配一块连续的内存空间;
- 在默认情况下会单独为runtime.hchan和缓冲区分配内存;
在函数的最后会统一更新runtime.hchan的elemsize、elemtype和dataqsiz几个字段。
发送数据
当我们想要向 Channel 发送数据时,就需要使用ch <- i语句,编译器会将它解析成OSEND节点并在cmd/compile/internal/gc.walkexpr中转换成runtime.chansend1:
func walkexpr(n *Node, init *Nodes) *Node {switch n.Op {case OSEND:n1 := n.Rightn1 = assignconv(n1, n.Left.Type.Elem(), "chan send")n1 = walkexpr(n1, init)n1 = nod(OADDR, n1, nil)n = mkcall1(chanfn("chansend1", 2, n.Left.Type), nil, init, n.Left, n1)}}
runtime.chansend1只是调用了runtime.chansend并传入 Channel 和需要发送的数据。runtime.chansend是向 Channel 中发送数据时一定会调用的函数,该函数包含了发送数据的全部逻辑,如果我们在调用时将block参数设置成true,那么表示当前发送操作是阻塞的:
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {lock(&c.lock)if c.closed != 0 {unlock(&c.lock)panic(plainError("send on closed channel"))}
在发送数据的逻辑执行之前会先为当前 Channel 加锁,防止多个线程并发修改数据。如果 Channel 已经关闭,那么向该 Channel 发送数据时会报 “send on closed channel” 错误并中止程序。
因为runtime.chansend函数的实现比较复杂,所以我们这里将该函数的执行过程分成以下的三个部分:
- 当存在等待的接收者时,通过runtime.send直接将数据发送给阻塞的接收者;
- 当缓冲区存在空余空间时,将发送的数据写入 Channel 的缓冲区;
- 当不存在缓冲区或者缓冲区已满时,等待其他 Goroutine 从 Channel 接收数据;
直接发送
如果目标 Channel 没有被关闭并且已经有处于读等待的 Goroutine,那么runtime.chansend会从接收队列recvq中取出最先陷入等待的 Goroutine 并直接向它发送数据:
if sg := c.recvq.dequeue(); sg != nil {send(c, sg, ep, func() { unlock(&c.lock) }, 3)return true}
发送数据时会调用runtime.send,该函数的执行可以分成两个部分:
- 调用runtime.sendDirect将发送的数据直接拷贝到x = <-c表达式中变量x所在的内存地址上;
- 调用runtime.goready将等待接收数据的 Goroutine 标记成可运行状态Grunnable并把该 Goroutine 放到发送方所在的处理器的runnext上等待执行,该处理器在下一次调度时会立刻唤醒数据的接收方;
需要注意的是,发送数据的过程只是将接收方的 Goroutine 放到了处理器的runnext中,程序没有立刻执行该 Goroutine。func send(c *hchan, sg *sudog, ep unsafe.Pointer, unlockf func(), skip int) {if sg.elem != nil {sendDirect(c.elemtype, sg, ep)sg.elem = nil}gp := sg.gunlockf()gp.param = unsafe.Pointer(sg)goready(gp, skip+1)}
缓冲区
如果创建的 Channel 包含缓冲区并且 Channel 中的数据没有装满,会执行下面这段代码:
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {...if c.qcount < c.dataqsiz {qp := chanbuf(c, c.sendx)typedmemmove(c.elemtype, qp, ep)c.sendx++if c.sendx == c.dataqsiz {c.sendx = 0}c.qcount++unlock(&c.lock)return true}...}
在这里我们首先会使用runtime.chanbuf计算出下一个可以存储数据的位置,然后通过runtime.typedmemmove将发送的数据拷贝到缓冲区中并增加sendx索引和qcount计数器。
如果当前 Channel 的缓冲区未满,向 Channel 发送的数据会存储在 Channel 的sendx索引所在的位置并将sendx索引加一。因为这里的buf是一个循环数组,所以当sendx等于dataqsiz时会重新回到数组开始的位置。
阻塞发送
当 Channel 没有接收者能够处理数据时,向 Channel 发送数据会被下游阻塞,当然使用select关键字可以向 Channel 非阻塞地发送消息。向 Channel 阻塞地发送数据会执行下面的代码,我们可以简单梳理一下这段代码的逻辑:
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {...if !block {unlock(&c.lock)return false}gp := getg()mysg := acquireSudog()mysg.elem = epmysg.g = gpmysg.c = cgp.waiting = mysgc.sendq.enqueue(mysg)goparkunlock(&c.lock, waitReasonChanSend, traceEvGoBlockSend, 3)// someone woke usgp.waiting = nilgp.param = nilmysg.c = nilreleaseSudog(mysg)return true}
- 调用runtime.getg获取发送数据使用的 Goroutine;
- 执行runtime.acquireSudog获取runtime.sudog结构并设置这一次阻塞发送的相关信息,例如发送的 Channel、是否在 select 中和待发送数据的内存地址等;
- 将刚刚创建并初始化的runtime.sudog加入发送等待队列,并设置到当前 Goroutine 的waiting上,表示 Goroutine 正在等待该sudog准备就绪;
- 调用runtime.goparkunlock将当前的 Goroutine 陷入沉睡等待唤醒;
- 被调度器唤醒后会执行一些收尾工作,将一些属性置零并且释放runtime.sudog结构体;
函数在最后会返回true表示这次我们已经成功向 Channel 发送了数据。
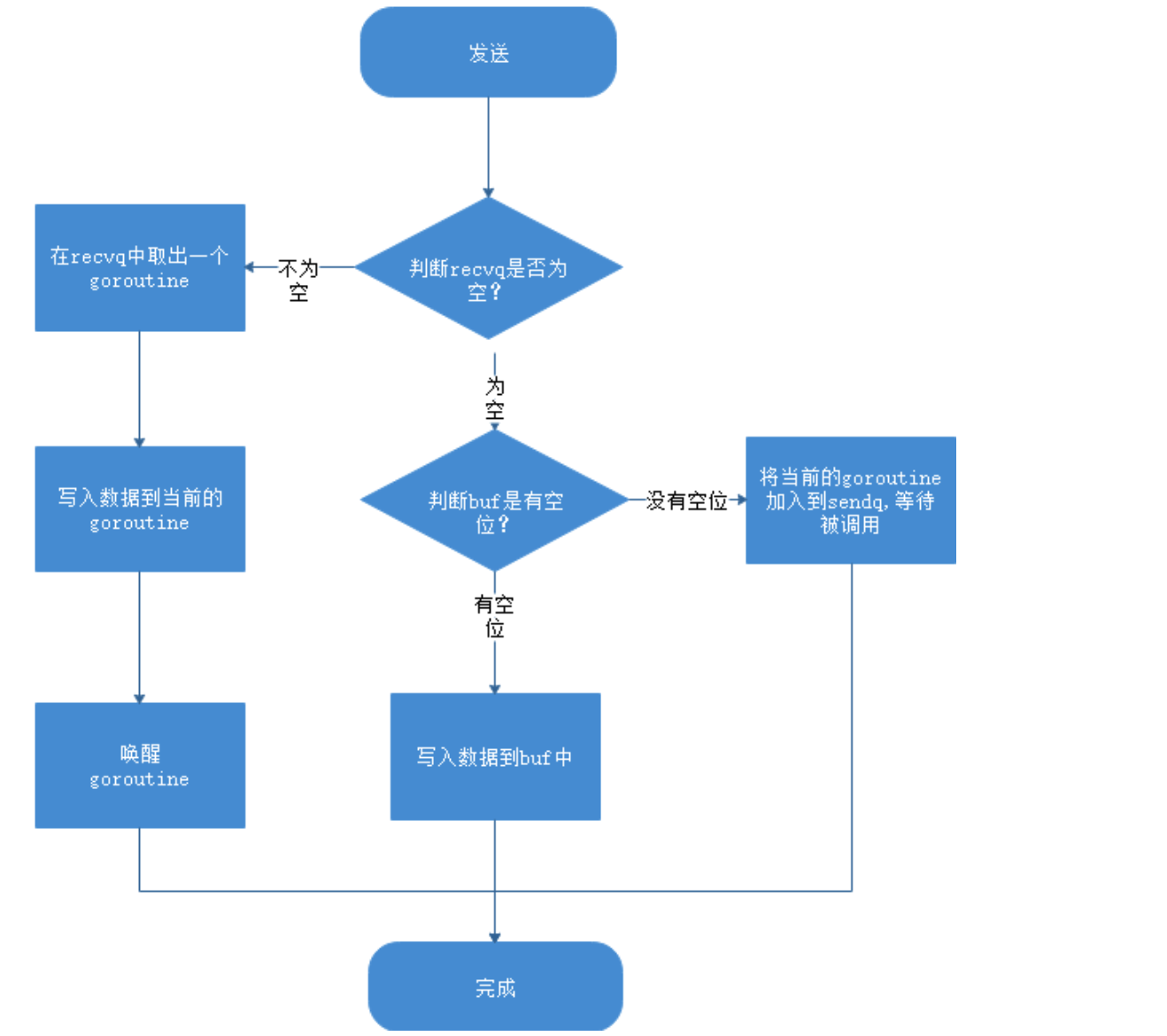
接收数据
我们接下来继续介绍 Channel 操作的另一方:接收数据。Go 语言中可以使用两种不同的方式去接收 Channel 中的数据:
i <- chi, ok <- ch
这两种不同的方法经过编译器的处理都会变成ORECV类型的节点,后者会在类型检查阶段被转换成OAS2RECV类型。数据的接收操作遵循以下的路线图: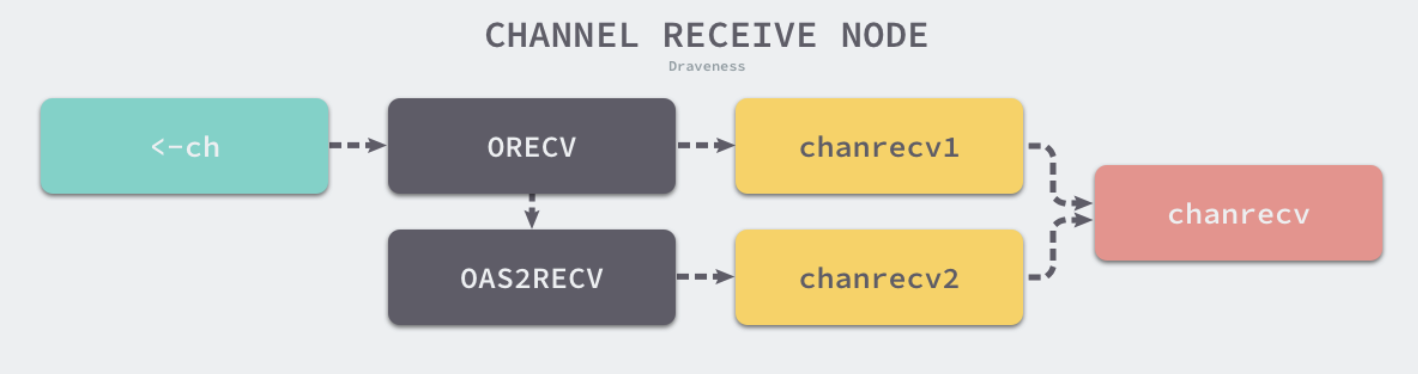
虽然不同的接收方式会被转换成runtime.chanrecv1和runtime.chanrecv2两种不同函数的调用,但是这两个函数最终还是会调用runtime.chanrecv。
当我们从一个空 Channel 接收数据时会直接调用runtime.gopark让出处理器的使用权。
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {if c == nil {if !block {return}gopark(nil, nil, waitReasonChanReceiveNilChan, traceEvGoStop, 2)throw("unreachable")}lock(&c.lock)if c.closed != 0 && c.qcount == 0 {unlock(&c.lock)if ep != nil {typedmemclr(c.elemtype, ep)}return true, false}
如果当前 Channel 已经被关闭并且缓冲区中不存在任何数据,那么会清除ep指针中的数据并立刻返回。
除了上述两种特殊情况,使用runtime.chanrecv从 Channel 接收数据时还包含以下三种不同情况:
- 当存在等待的发送者时,通过runtime.recv从阻塞的发送者或者缓冲区中获取数据;
- 当缓冲区存在数据时,从 Channel 的缓冲区中接收数据;
- 当缓冲区中不存在数据时,等待其他 Goroutine 向 Channel 发送数据;
直接接收
当 Channel 的sendq队列中包含处于等待状态的 Goroutine 时,该函数会取出队列头等待的 Goroutine,处理的逻辑和发送时相差无几,只是发送数据时调用的是runtime.send函数,而接收数据时使用runtime.recv:
if sg := c.sendq.dequeue(); sg != nil {recv(c, sg, ep, func() { unlock(&c.lock) }, 3)return true, true}
runtime.recv的实现比较复杂:
func recv(c *hchan, sg *sudog, ep unsafe.Pointer, unlockf func(), skip int) {if c.dataqsiz == 0 {if ep != nil {recvDirect(c.elemtype, sg, ep)}} else {qp := chanbuf(c, c.recvx)if ep != nil {typedmemmove(c.elemtype, ep, qp)}typedmemmove(c.elemtype, qp, sg.elem)c.recvx++c.sendx = c.recvx // c.sendx = (c.sendx+1) % c.dataqsiz}gp := sg.ggp.param = unsafe.Pointer(sg)goready(gp, skip+1)}
该函数会根据缓冲区的大小分别处理不同的情况:
- 如果 Channel 不存在缓冲区;
- 调用runtime.recvDirect将 Channel 发送队列中 Goroutine 存储的elem数据拷贝到目标内存地址中;
- 如果 Channel 存在缓冲区;
- 将队列中的数据拷贝到接收方的内存地址;
- 将发送队列头的数据拷贝到缓冲区中,释放一个阻塞的发送方;
无论发生哪种情况,运行时都会调用runtime.goready将当前处理器的runnext设置成发送数据的 Goroutine,在调度器下一次调度时将阻塞的发送方唤醒。
缓冲区
当 Channel 的缓冲区中已经包含数据时,从 Channel 中接收数据会直接从缓冲区中recvx的索引位置中取出数据进行处理:
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
...
if c.qcount > 0 {
qp := chanbuf(c, c.recvx)
if ep != nil {
typedmemmove(c.elemtype, ep, qp)
}
typedmemclr(c.elemtype, qp)
c.recvx++
if c.recvx == c.dataqsiz {
c.recvx = 0
}
c.qcount--
return true, true
}
...
}
如果接收数据的内存地址不为空,那么会使用runtime.typedmemmove将缓冲区中的数据拷贝到内存中、清除队列中的数据并完成收尾工作。
阻塞接收
当 Channel 的发送队列中不存在等待的 Goroutine 并且缓冲区中也不存在任何数据时,从管道中接收数据的操作会变成阻塞的,然而不是所有的接收操作都是阻塞的,与select语句结合使用时就可能会使用到非阻塞的接收操作:
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
...
if !block {
unlock(&c.lock)
return false, false
}
gp := getg()
mysg := acquireSudog()
mysg.elem = ep
gp.waiting = mysg
mysg.g = gp
mysg.c = c
c.recvq.enqueue(mysg)
goparkunlock(&c.lock, waitReasonChanReceive, traceEvGoBlockRecv, 3)
// someone woke us up
gp.waiting = nil
closed := gp.param == nil
gp.param = nil
releaseSudog(mysg)
return true, !closed
}
在正常的接收场景中,我们会使用runtime.sudog将当前 Goroutine 包装成一个处于等待状态的 Goroutine 并将其加入到接收队列中。
完成入队之后,上述代码还会调用runtime.goparkunlock,让出处理器的使用权并等待调度器的调度。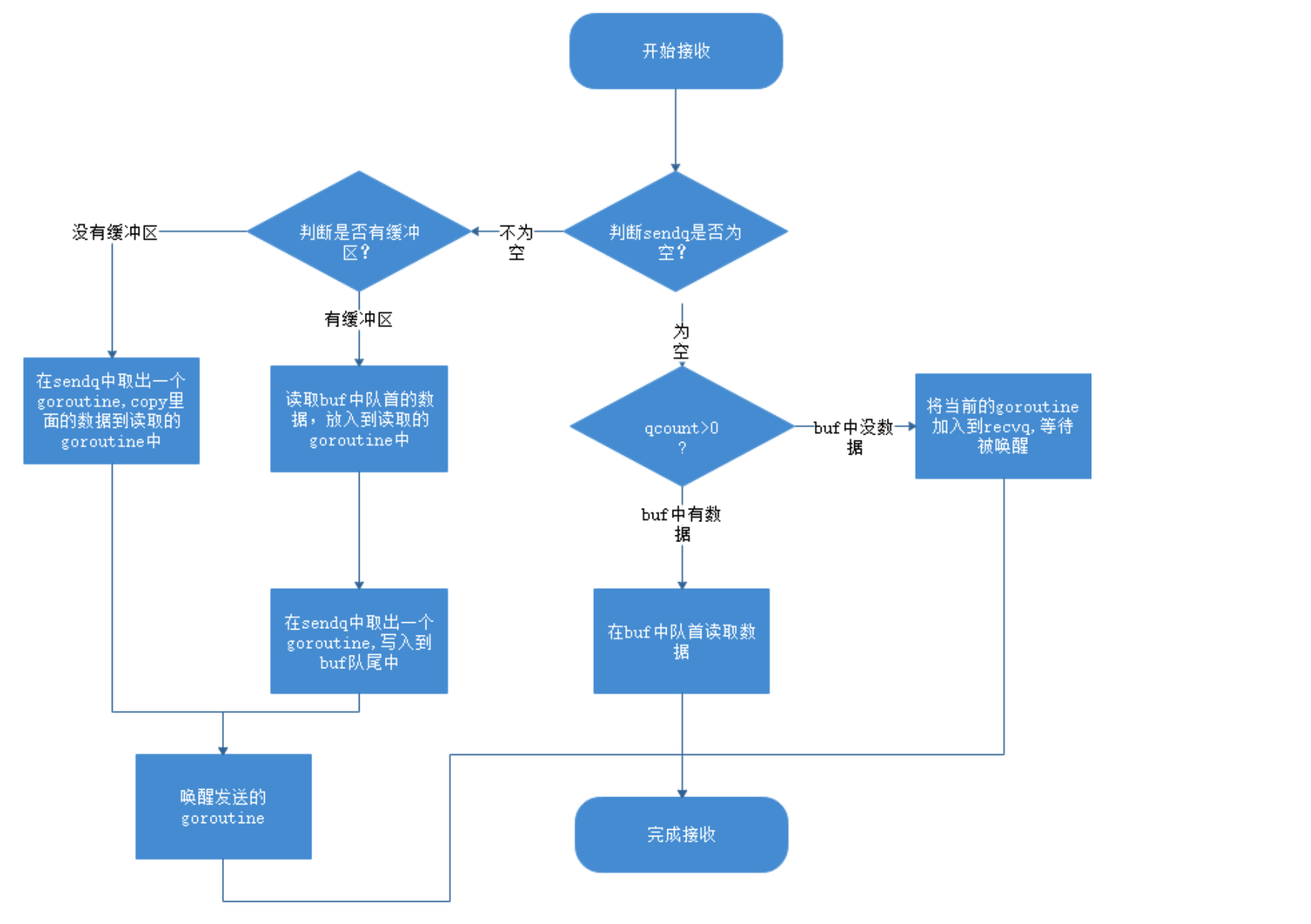
channel的关闭
chanbel的关闭,对于其中的recvq和sendq也就是阻塞的发送者和接收者,对于等待接收者而言,会收到一个相应类型的零值。对于等待发送者,会直接 panic。
channel的关闭不当会出现panic的场景:
- 关闭值为nil的channel
- 关闭已经关闭的channel
向已经关闭的channel写入数据
func closechan(c *hchan) { // 关闭值为nil的channel,报错panic if c == nil { panic(plainError("close of nil channel")) } // 加锁 lock(&c.lock) // 关闭已经关闭的channel,报错panic if c.closed != 0 { unlock(&c.lock) panic(plainError("close of closed channel")) } if raceenabled { callerpc := getcallerpc() racewritepc(c.raceaddr(), callerpc, funcPC(closechan)) racerelease(c.raceaddr()) } // 修改关闭饿状态 c.closed = 1 var glist gList // 释放recvq中的sudog for { // 接收一个sudog sg := c.recvq.dequeue() // 全部接收完毕了 if sg == nil { break } // 如果 elem 不为空,说明此 receiver 未忽略接收数据 // 给它赋一个相应类型的零值 if sg.elem != nil { typedmemclr(c.elemtype, sg.elem) sg.elem = nil } if sg.releasetime != 0 { sg.releasetime = cputicks() } // 取出goroutine gp := sg.g gp.param = nil if raceenabled { raceacquireg(gp, c.raceaddr()) } glist.push(gp) } // 释放 sendq中的sudog // 如果存在,这些 goroutine 将会 panic for { // 取出 sg := c.sendq.dequeue() if sg == nil { break } // 发送者会 panic sg.elem = nil if sg.releasetime != 0 { sg.releasetime = cputicks() } gp := sg.g gp.param = nil if raceenabled { raceacquireg(gp, c.raceaddr()) } glist.push(gp) } unlock(&c.lock) // Ready all Gs now that we've dropped the channel lock. for !glist.empty() { // 取出一个 gp := glist.pop() gp.schedlink = 0 // 唤醒相应 goroutine goready(gp, 3) } }
其他
需要注意的点
| 操作 | nil channel | closed channel | not nil ,not closed |
|---|---|---|---|
| close | panic | panic | 正常关闭 |
| 读<-ch | 阻塞 | 里面的内容读完了,之后获取到的是类型的零值 | 阻塞或正常读取数据。缓冲型 channel 为空或非缓冲型 channel 没有等待发送者时会阻塞 |
| 写ch<- | 阻塞 | panic | 阻塞或正常写入数据。非缓冲型 channel 没有等待接收者或缓冲型 channel buf 满时会被阻塞 |
发送和接收的本质
Remember all transfer of value on the go channels happens with the copy of value.
和go中函数一样,channel中发送和接收的操作都是值传递。

若有收获,就点个赞吧
0 人点赞
